
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we have explored How a (Machine Learning) ML Dataset is designed? with the example of the PASCAL dataset (Pascal-1 Visual Object Classes (VOC)) and how it evolved over the years and how the initial dataset was prepared.

Data in the 21st Century is like Oil in the 18th Century: an immensely, untapped valuable asset. Big companies like Google, Facebook, Netflix and even Governments of different countries need Data. Data is used to monitor growth, analyze and improve performance and most important for Machine Learning and Artifical Intelligence.
Collection of Data is not as easy as it looks!. Most of the data available online is useless for analyzing and using in AI&ML models. Data has to be cleaned and pre-processed. This is either done by the Data Scientists of the companies or Research Scientists of Institutes like Standford and MIT. These Datasets are then available for public use. Let's see how a dataset is designed ?
Data Collection

Data collection varies as per the data required. In case of structured data, it is maintained in Public Databases and are easily available in Government or Company Websites. Data is also collected through surveys through Google Forms or Microsoft Form which can be exported to Excel Sheets. For Text Data, there are many web scrappers available which are able to extract text data from HTML Pages. For Images, companies like Google or Facebook has access to User Photos. There are also many free Image APIs which search and collects images like Bing Image API
Data Cleaning

After the data collection is complete it is still useless and requires some cleaning and pre-processing in order to be fed to ML Models. According to experts 90% of time spent by Data Scientists at work is in cleaning the data. For structured data, data may contain some missing values which are statistically corrected. Most of the data collected becomes useless and therefore has to be deleted. For image data, the quality of images used are usually too much to be used by normal PCs, therefore (especially in public datasets) the images are down scaled. After the data is ready, generally it is split into Training and Testing set. The training set is further divided into Training and Validation set.
The PASCAL Dataset
The Pascal-1 Visual Object Classes (VOC) Challenge has
been an annual event since 2006. The challenge consists of
two components: (i) a publicly available dataset of images
obtained from the Flickr web site (2013), together with ground truth annotation and standardised evaluation software; and (ii) an annual competition and workshop. There are three principal challenges: classification—“does the image contain any instances of a particular object class?” (where object classes include cars, people, dogs, etc.), detection— “where are the instances of a particular object class in the image (if any)?”, and segmentation—“to which class does each pixel belong?”.
In case of PASCAL Dataset there are twenty major classes, named as follows: Aeroplane, Bottle, Bird, Person, Bicycle, Chair, Cat, Boat, Dining, Table, Cow, Bus, Potted, Plant, Dog, Car, Sofa, Horse, Motorbike, TV/Monitor, Sheep, Train. The revised version of the Dataset contains 150+ classes. Some pictures from the dataset are as follows:




Since we are dealing with supervised learning, we require some kind of labels for training purpose. There is complete annotation of the 20 classes: i.e. all
images are annotated with bounding boxes for every instance of the twenty classes for the classification and detection challenges. In addition to a bounding box for each object, attributes such as: ‘orientation’, ‘occluded’, ‘truncated’, ‘difficult’; are specified. Below are some of the examples :




Challenges in making the dataset
Annotation
The biggest challenge in the PASCAL Dataset is to annotate a dataset this huge. This was done using the Mechanical Turk.
Amazon Mechanical Turk (MTurk) is a crowdsourcing marketplace that makes it easier for individuals and businesses to outsource their processes and jobs to a distributed workforce who can perform these tasks virtually. This could include anything from conducting simple data validation and research to more subjective tasks like survey participation, content moderation, and more. MTurk enables companies to harness the collective intelligence, skills, and insights from a global workforce to streamline business processes, augment data collection and analysis, and accelerate machine learning development.
Although it took many trails to get all the annotations correct. After annotations were over, the next step was to perform Segmentation.
Segmentation
Segmentation requires substantially more annotation effort than detection—it can easily take ten times as long to segment an object than to draw a
bounding box around it. Over time, the annotation period was
adapted until around 50% of the time was spent on segmentation annotation and checking
Once post-hoc segmentation correction was completed, each annotator was sent a report detailing the number and kind of errors that they made, so they could avoid such errors in future years.
Changes in Dataset Over the Years
Over the years from 2005 to 2012, the PASCAL Dataset has changed significantly. First the dataset size has changed dramatically. The number of of classes increased from 20 to 120+ (as of 2014). The quality of Annotations as Segmentations increased with increase in the popularity of the competition and therefore more people making the competition a huge success.
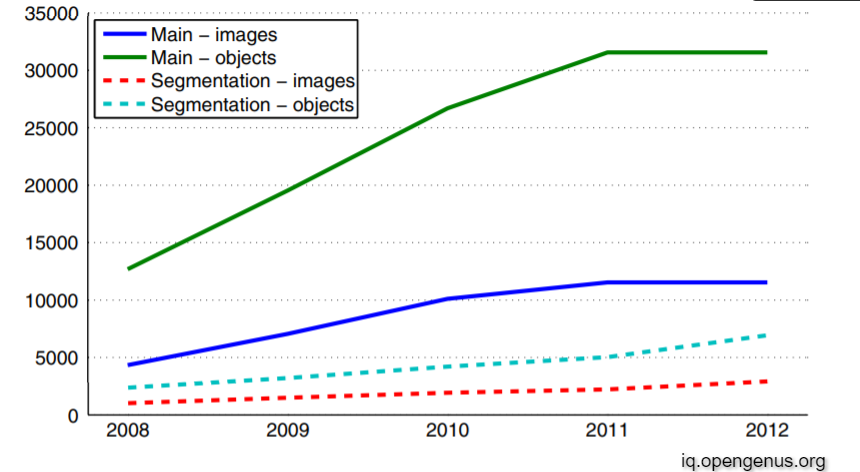
Changes in PASCAL Dataset Images over the years
Performance of Current Methods across Classes
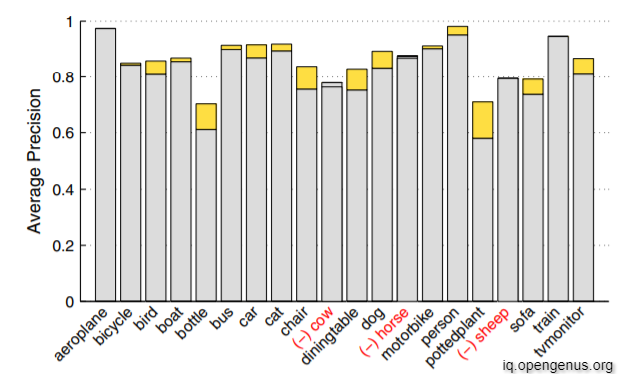
In the above picture you can see that the Average Precision of every class differs from the others with aeroplane being the highest and bottle being the lowest.
Let's take a look at precision distribution for classification over the years and for each class
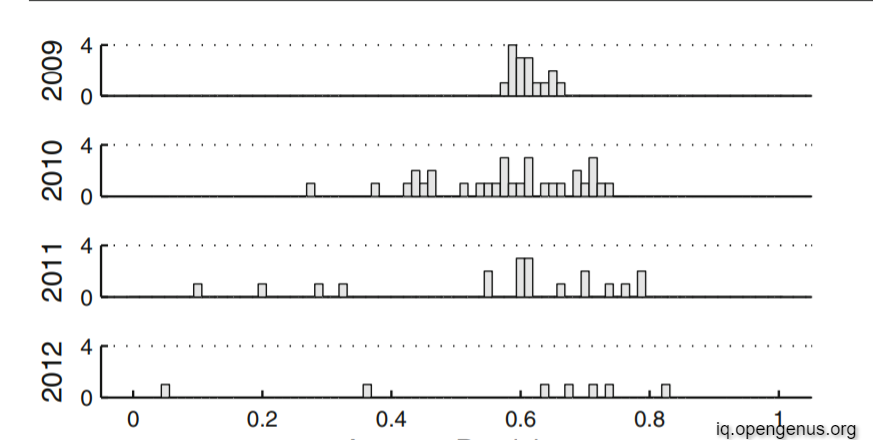
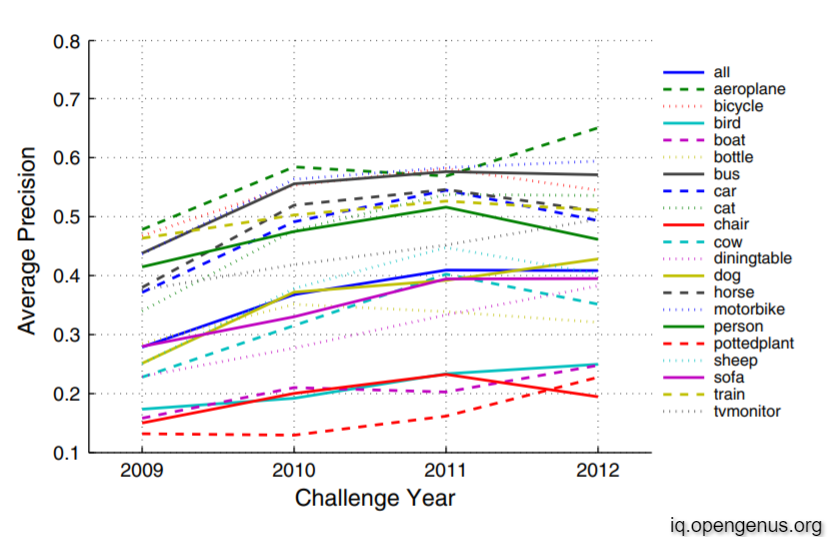
Conclusion
In this article, we saw how an ML dataset if designed. Depending on the task and the type of data used, the process widely differs though the collection and cleaning process still remains the same. Whether you are Researcher or a Hackathon/Competition organizer, knowing the above steps are crucial for your success. For more such articles follow OpenGenus Artificial Intelligence