
Reading time: 40 minutes
Image to image translation is a class of computer vision and graphics, & deep learning problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs.
Obviously, for most tasks, paired training data won't be available because:
- Obtaining paired training data can be difficult and expensive
- Acquiring input-output pairs for graphic tasks like artistic stylization can be even more difficult as the desired output is highly complex, often requiring artistic authoring and guidance.
- For many problems, such as object transfiguration (e.g. generating an image of a horse from a given image of a zebra), the desired output is not even well-defined.
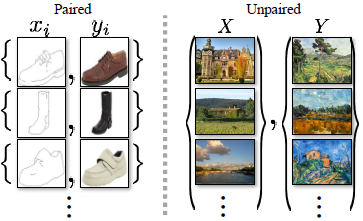
In the image above, paired training data (left) consists of training examples where the correspondence between and exists.
Unpaired training data (right), consists of a source set and a target set , with no information provided as to which matches which .
A need for an algorithm was felt which could learn to translate between domains without using paired input-output examples.
In their innovative paper titled, "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks", Isola et al. (2018) achieve just this.
They presented an approach for learning to translate an image from a source domain to a target domain in the absence of paired examples.

The above image illustrates the basic idea of the algorithm - Given any unordered image collections and , the algorithm learns to automatically "translate" an image from one into the other and vice versa.
They assumed that there is some underlying relationship between the domains - for example, that they are different renderings of the same underlying scenery - and sought to learn that relationship.
Though they lacked supervision in the form of paired examples, they exploited supervision at the set-level:
Given one set of images in domain and a different set in domain , the authors trained a mapping such that the output is indistinguishable from images by an adversary which is trained to classify from .
The objective of their algorithm was to learn a mapping such that the distribution of images from is indistinguishable from the distribution using an adversarial loss.
This mapping was found to be highly under-constrained, so they coupled it with an inverse mapping and introduced a cycle consistency loss to enforce and .
"Cycle consistent", in easy words, means if we translate a sentence from, say, English to Hindi, and then translate it back from Hindi to English, we should arrive back at the original sentence.
In mathematical terms, if we have a translator and another translator , then and should be inverses of each other, and both mappings should be bijections.
To make things clearer and so that you understand the concept properly, let's understand how the CycleGAN model proposed by the authors works, using a visual.
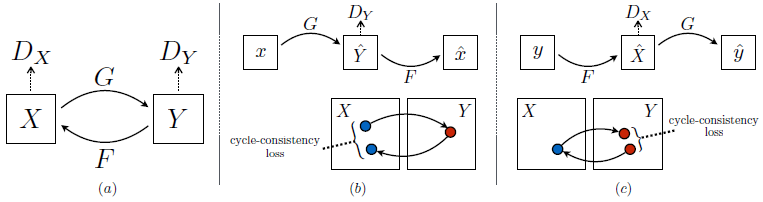
a) The model contains mapping functions and , and associated adversarial discriminators and .
encourages to translate into outputs indistinguishable from domain , and vice versa for and .
For the purpose of regularizing the mappings, cycle-consistency losses are introduced, which capture the intuition that if we translate one domain to the other and back again, we should arrive at where we started.
b) Forward cycle-consistency loss: , and
c) Backward cycle-consistency loss:
Related Work
A) Generative Adversarial Networks (GANs)
- GANs have achieved splendid results in image generation [2, 3], representation learning [3, 4], image editing [5].
- Recent methods adopt the same idea for conditional image generation applications, such as text2image [6], image inpainting [7], and future prediction [8], as well as to other domains like videos [9] and 3D data [10].
- The key to GANs' success is the idea of an adversarial loss that forces the generated images to be, in principle, indistinguishable from real images.
- In the CycleGAN paper, the authors adopt an adversarial loss to learn the mapping such that the translated images can't be distinguished from images in the target domain.
B) Image-to-Image Translation
- Recent applications all involve a dataset of input-output examples to learn a parametric translation function using CNNs (e.g. [11]).
- The approach in the CycleGAN paper builds on the "pix2pix" framework of Isola, et al., [12] which uses a conditional GAN to learn a mapping from input to output images.
- Parallel ideas have been applied to tasks such as generating photos from sketches [13] or from attribute and semantic layouts [14], but the CycleGAN algorithm learns the mapping without paired training examples.
C) Unpaired Image-to-Image Translation
- The goal in an unpaired setting is to relate domains: and .
- Rosales et al. [15] proposed a Bayesian framework which includes a prior based on a patch-based Markov random field computed from a source image and a likelihood term obtained from multiple style images.
- CoGAN [16] and cross-modal scene networks [17] use a weight-sharing strategy to learn a common representation across domains.
- Another line of work [18, 19] encourages the input and output to share specific "content" features even though they may differ in "style".
- Unlike the above approaches, the CycleGAN formulation does not rely on any task-specific, predefined similarity function between the input and output, nor does it assume that the input and output have to lie in the same low-dimensional embedding space.
- This is what makes the CycleGAN method a general-purpose solution for many computer vision and graphics use cases.
D) Cycle Consistency
- We have explained the concept of cycle-consistency above.
- Higher-order cycle consistency has been used in shape matching [20], dense semantic alignment [21], and depth estimation [22].
- Zhou et al. [23] and Godard et al. [22] are most similar to the work of the CycleGAN paper, as they used a cycle consistency loss as a way of using transitivity to supervise CNN training.
- In the CycleGAN paper, a similar loss was introduced to push and to be consistent with each other.
E) Neural Style Transfer
- Simply put, neural style transfer is a way to perform image-to-image translation, which generates a novel image by combining the content of one image with the style of another (usually a painting), based on matching the Gram matrix statistics of pre-trained deep features. [24, 25]
- However, the main focus of the CycleGAN paper was to learn the mapping between image collections, rather than between specific images, by trying to capture correspondences between higher-level appearance structures.
Formulation
As explained earlier, the goal of CycleGAN is to learn mapping functions between domains and given training examples where and where .
Let's denote the distributions as and .
The model includes mappings and .
Also, adversarial discriminators and are introduced, where aims to distinguish between images and translated images ; similarly, aims to discriminate between and .
Two kinds of losses are made use of -
✪ Adversarial losses - for matching the distribution of generated images to the data distribution in the target domain, and
✪ Cycle-Consistency losses - to prevent the learned mappings and from contradicting each other.
I) Adversarial Loss
➢ Adversarial losses are applied to both mapping functions:
➢ For the mapping function and its discriminator , we can express the objective as:
➢ Here, tries to generate images that look similar to images from domain , while aims to distinguish between translated samples and real samples .
➢ aims to minimize this objective against an adversary that tries to maximize it, i.e.,
➢ Similarly, the adversarial loss for the mapping function and its discriminator is:
II) Cycle-Consistency Loss
➢ For each image from domain , the image translation cycle should be able to bring back to the original image, i.e. .
This is called forward cycle-consistency.
➢ Equivalently, for each image from domain , and should also satisfy backward cycle-consistency: .
➢ The cycle consistency loss can thus, be defined as:

The above image shows the input images , output images and the reconstructed images from various experiments.
III) Full Objective Function
➢ The full objective function can be spread out as:
,
where controls the relative importance of the objectives.
➢ The aim is to solve the following:
IV) Model Implementation
➢ A CycleGAN is made up of architectures - a generator and a discriminator.
➢ The generator architecture is used to create models, Generator A and Generator B.
➢ The discriminator architecture is used to create another models, Discriminator A and Discriminator B.
A) Generator architecture
⚫ The generator network is akin to an autoencoder network - it takes in an image and outputs another image.
⚫ It has parts: an encoder and a decoder.
⚫ The encoder contains convolutional layers with downsampling capabilities and transforms an input of shape to an internal representation.
⚫ The decoder contains upsampling blocks and a final convolutional layer, which transforms the internal representation to an output of shape .
⚫ The generator network contains the following blocks:
➜ The convolutional block
➜ The residual block
➜ The upsampling block
➜ The final convolutional layer
The convolutional block
❂ The convolutional block contains a convolutional layer, followed by an instance normalization layer, and ReLU as the activation function.
❂ The generator network contains convolutional blocks.
The residual block
❂ The residual block contains two convolutional layers.
❂ Both layers are followed by a batch normalization layer with a momentum value of
❂ The generator network contains residual blocks.
❂ The addition layer which is the concluding layer of this block calculates the sum of the input tensor to the block and the output of the last batch normalization layer.
The upsampling block
❂ The upsampling block contains a transpose convolutional layer and uses ReLU as the activation function.
❂ There are upsampling blocks in the generator network.
The final convolutional layer
❂ The last layer is a convolutional layer that uses Tanh as the activation function.
❂ It generates an image of shape .
B) Discriminator Architecture
⚫ The architecture of the discriminator network is similar to that of the discriminator in a PatchGAN network.
⚫ It is a deep convolutional neural network and contains several convolutional blocks.
⚫ What it basically does is, take in an image having shape and predicts whether the image is real or fake.
⚫ It contains several ZeroPadding2D layers too.
⚫ The discriminator network returns a tensor of shape .
C) The Training Objective Function
⚫ CycleGANs have a training objective function which we need to minimize in order to train the model.
⚫ The loss function is a weighted sum of losses:
- Adversarial loss
- Cycle-consistency loss
Please refer to the Formulation section above to learn about these loss functions.
Results
I) Evaluation Metric (FCN Score)
➤ The FCN score was chosen as an automatic quantitative meausre which does not require human experiments and supervision (like in Amazon Mechanical Turk perceptual studies)
➤ The FCN score from [12] was adopted, and used to evaluate the performance of the CycleGAN on the Cityscapes labels photo task.
➤ The FCN metric evaluates how interpretable the generated photos are according to an off-the-shelf semantic segmentation algorithm (the fully connected network, FCN, from [11]).
➤ The FCN predicts a label map for a generated photo.
➤ This label map can then be compared against the input ground truth labels using standard semantic segmentation metrics (per-pixel accuracy, per-class accuracy and mean class Intersection-Over-Union (Class IOU)).
➤ The point is that, if we generate a photo from a label map of "bird on the tree", then we have succeeded if the FCN applied to the generated photo detects "bird on the tree".
II) Baselines
➤ Different models and architectures were trained alongside the CycleGAN so that a comprehensive performance evaluation could be made.
➤ The models that were tested are as follows:
➡ CoGAN [16]
➡ SimGAN [18]
➡ Feature loss + GAN
➡ BiGAN / ALI [26]
➡ pix2pix [12]
III) Comparison against the baselines

The image above illustrates the different methods for mapping labels photos trained on Cityscapes images.

This image depicts the different methods for mapping aerial photos maps on Google Maps.
It is obvious from the renderings above that the authors were unable to achieve credible results with any of the baselines.
Their CycleGAN method on the other hand, was able to produce translations that were often of similar quality to the fully supervised pix2pix.
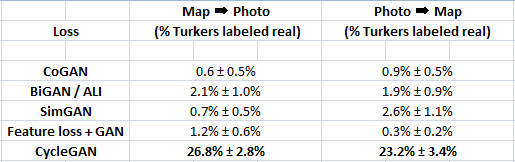
Table 1: AMT "real vs fake" test on maps aerial photos at x resolution.
Table 1 reports performance regarding the AMT perceptual realism task.
Here, we see that the CycleGAN method can fool participants on around a quarter of trials, in both the maps aerials photos direction and the aerial photos maps direction at x resolution.
All the baselines almost never fooled participants.
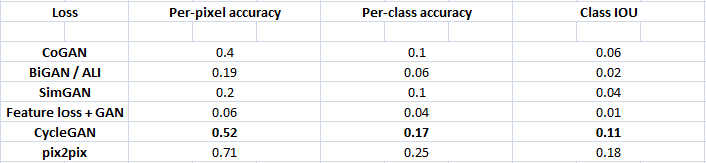
Table 2: FCN-scenes for different methods, evaluated on Cityscapes labels photo.
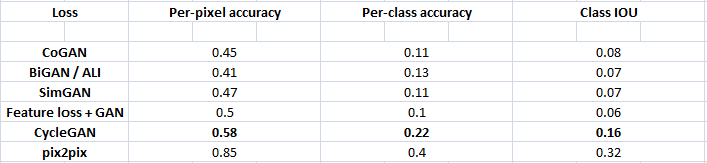
Table 3: Classification performance of photo labels for different methods on cityscapes.
Table 2 evaluates the perfomance of the labels photo task on the Cityscapes and Table 3 assesses the opposite mapping (photos labels).
In both cases, the CycleGAN method again outperforms the baselines.
IV) Additional results on paired datasets

Shown above are example results of CycleGAN on paired datasets used in "pix2pix", such as architectural labels photos (from the CMP Facade Database) and edges shoes (from the UT Zappos50K dataset).
The image quality of the CycleGAN results is close to those produced by the fully supervised pix2pix while the former method learns the mapping without paired supervision.
Implementation of CycleGAN in Keras
The entire working code of the CycleGAN model adds up to around 400 lines of code in Python, which we obviously won't manifest here.
But, we will show you how the Residual block, the Generator and the Discriminator networks are implemented, using the Keras framework.
Let's import all the required libraries first:
import time
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import PIL
from glob import glob
from keras import Input, Model
from keras.callbacks import TensorBoard
from keras.layers import Conv2D, BatchNormalization, Activation
from keras.layers import Add, Conv2DTranspose, ZeroPadding2D, LeakyReLU
from keras.optimizers import Adam
from imageio import imread
from skimage.transform import resize
from keras_contrib.layers.normalization.instancenormalization Import InstanceNormalization
I) Residual Block
def residual_block(x):
"""
Residual block
"""
res = Conv2D(filters = 128, kernel_size = 3, strides = 1, padding = "same")(x)
res = BatchNormalization(axis = 3, momentum = 0.9, epsilon = 1e-5)(res)
res = Activation('relu')(res)
res = Conv2D(filters = 128, kernel_size = 3, strides = 1, padding = "same")(res)
res = BatchNormalization(axis = 3, momentum = 0.9, epsilon = 1e-5)(res)
return Add()([res, x])
II) Generator Network
def build_generator():
"""
Creating a generator network with the hyperparameters defined below
"""
input_shape = (128, 128, 3)
residual_blocks = 6
input_layer = Input(shape = input_shape)
## 1st Convolutional Block
x = Conv2D(filters = 32, kernel_size = 7, strides = 1, padding = "same")(input_layer)
x = InstanceNormalization(axis = 1)(x)
x = Activation("relu")(x)
## 2nd Convolutional Block
x = Conv2D(filters = 64, kernel_size = 3, strides = 2, padding = "same")(x)
x = InstanceNormalization(axis = 1)(x)
x = Activation("relu")(x)
## 3rd Convolutional Block
x = Conv2D(filters = 128, kernel_size = 3, strides = 2, padding = "same")(x)
x = InstanceNormalization(axis = 1)(x)
x = Activation("relu")(x)
## Residual blocks
for _ in range(residual_blocks):
x = residual_block(x)
## 1st Upsampling Block
x = Conv2DTranspose(filters = 64, kernel_size = 3, strides = 2, padding = "same",
use_bias = False)(x)
x = InstanceNormalization(axis = 1)(x)
x = Activation("relu")(x)
## 2nd Upsampling Block
x = Conv2DTranspose(filters = 32, kernel_size = 3, strides = 2, padding = "same",
use_bias = False)(x)
x = InstanceNormalization(axis = 1)(x)
x = Activation("relu")(x)
## Last Convolutional Layer
x = Conv2D(filters = 3, kernel_size = 7, strides = 1, padding = "same")(x)
output = Activation("tanh")(x)
model = Model(inputs = [input_layer], outputs = [output])
return model
III) Discriminator Network
def build_discriminator():
"""
Create a discriminator network using the hyperparameters defined below
"""
input_shape = (128, 128, 3)
hidden_layers = 3
input_layer = Input(shape = input_shape)
x = ZeroPadding2D(padding = (1, 1))(input_layer)
## 1st Convolutional Block
x = Conv2D(filters = 64, kernel_size = 4, strides = 2, padding = "valid")(x)
x = LeakyReLU(alpha = 0.2)(x)
x = ZeroPadding2D(padding = (1, 1))(x)
## 3 Hidden Convolutional Blocks
for i in range(1, hidden_layers + 1):
x = Conv2D(filters = 2 ** i * 64, kernel_size = 64, strides = 2, padding = "valid")(x)
x = InstanceNormalization(axis = 1)(x)
x = LeakyReLU(alpha = 0.2)(x)
x = ZeroPadding2D(padding = (1, 1))(x)
## Last Convolutional Layer
output = Conv2D(filters = 1, kernel_size = 4, strides = 1, activation = "sigmoid")(x)
model = Model(inputs = [input_layer], outputs = [output])
return model
Bonus:
You can find the entire code for the CycleGAN model at this link.
Applications
The CycleGAN method is demonstrated on several use cases where paired training data does not exist.
It was observed by the authors that translations on training data are often more appealing than those on test data.
▶ Collection Style transfer
- The model was trained on landscape photographs from Flickr and WikiArt.
- Unlike recent work on "neural style transfer", this method learns to mimic the style of an entire collection of artworks, rather than transferring the style of a single selected piece of art.
- Therefore, we can learn to generate photos in the style of, e.g. Van Gogh, rather than just in the style of Starry Night.
- The size of the dataset for each artist / style was , , , and for Cezanne, Monet, Van Gogh, and Ukiyo-e.


▶ Object Transfiguration
- The model is trained to translate one object class from ImageNet to another (each class contains around training images).
- Campbell et al. [27] proposed a subspace model to translate one object into another, belonging to the same category, while the CycleGAN method focuses on object transfiguration between visually similar categories.


▶ Season transfer
The model was trained on winter photos and summer photos of Yosemite, downloaded from Flickr.

▶ Photo generation from paintings
The images below portray the relatively successful results on mapping Monet's paintings to a photographic style.


▶ Photo enhancement
- The CycleGAN method can also be used to generate photos with shallower depth of field (DoF).
- The model was trained on flower photos obtained from Flickr.
- The source domain consists of flower photos taken by smartphones, which usually have deep DoF due to a small aperture.
- The target contains photos captured by DSLR with a larger aperture.
- It was noted that the model successfully generated photos with shallower DoF from the photos taken by smartphones.

References
- Isola, et al. (2018), "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks"
- Chintala, et al. (2015), "Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks"
- Chintala, et al. (2015), "Unsupervised Representation Learning with Deep Convolutional GANs"
- Goodfellow, et al. (2016), "Improved Techniques for Training GANs"
- Efros, et al. (2016), "Generative Visual Manipulation of the Natural Image Manifold"
- Reed, et al. (2016), "Generative Adversarial Text to Image Synthesis"
- Efros, et al. (2016), "Context Encoders: Feature Learning by Inpainting"
- LeCun, et al. (2016), "Deep multi-scale video prediction beyond mean square error"
- Vondrick, et al. (2016), "Generating videos with scene dynamics"
- Tenenbaum, et al. (2016), "Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling"
- Darrell, et al. (2015), "Fully convolutional networks for semantic segmentation"
- Isola, et al. (2017), "Image-to-image translation with conditional adversarial networks"
- Hays, et al. (2016), "Controlling deep image synthesis with sketch and color"
- Erdem, et al. (2016), "Learning to generate images of outdoor scenes from attributes and semantic layouts"
- Rosales, et al. (2003), "Unsupervised Image Translation"
- Liu, et al. (2016), "Coupled generative adversarial networks"
- Vondrick, et al. (2016), "Cross-modal scene networks"
- Pfister, et al. (2017), "Learning from simulated and unsupervised images through adversarial learning"
- Wolf, et al. (2017), "Unsupervised cross-domain image generation"
- Huang, et al. (2013), "Consistent shape maps via semidefinite programming"
- Efros, et al. (2015), "Flowweb: Joint image set alignment by weaving consistent, pixel-wise correspondences"
- Godard, et al. (2017), "Unsupervised monocular depth estimation with left-right consistency"
- Efros, et al. (2016), "Learning dense correspondence via 3D-guided cycle consistency"
- Gatys, et al. (2016), "Image style transfer using convolutional neural networks"
- Johnson, et al. (2016), "Perceptual losses for real-time style transfer and super-resolution"
- Poole, et al. (2017), "Adversarially learned inference"
- Campbell, et al. (2015), "Modeling object appearance using context-conditioned component analysis"
So that was it, dear reader. I hope you enjoyed the article above and learnt how CycleGANs can generate realistic renditions of paintings without using paired training data.
Please comment below to let me know your views on this post, and also, any doubts that you might have.
Follow me on LinkedIn and Medium to get updates on more articles ☺ .