
In this article, I will be going to introduce you with the another application of BERT for finding out whether a particular pair of sentences have the similar meaning or not .The same concept can also be used to compare two sentences in different form instead of only for the similar meaning these task might be follow up or proceeding sentences or whether two sentences belong to the same related topic or not etc.
Sentence Semantic similarity
In general Natural Language Processing tasks we need to find similarity between two short texts or two pair of sentences and the most common one
is for query search in which generally a query mapped onto the full text corpus and return us the most similar text to that query ,So basically Sentence similarity a crucial role any search system which considers context.
So, what is the problems associated with using traditional RNN,LSTM approaches for computing the sentences similarity? .As traditional approaches do not consider semantic or contextual behaviour of the sentences they generally go for the frequency of occurence of similar words or token instead of really knowing what contextually sentence trying to say , as in the below example you can see below image.
So the idea behind this is that if two query or sentences have similar responses then they semantically similar for example in the below image the first query “How old are you?” and the second one “What is your age?” have the same response as “I am 20 years old” in contrast , the “How are you?” and “How old are you?” contains high frequency of similar words and the going to produce high similarity in non-contextual based approach but they have completely different meaning as a result we expect to have different response for them .Another way to visualize or learning this is by classifying
pair of sentences as query and responses.
Implementation of Sentence Semantic similarity using BERT:
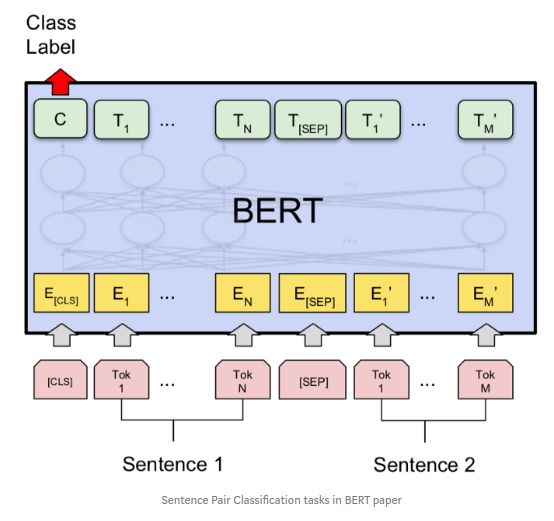
We are going to fine tune the BERT pre-trained model for out similarity task , we are going to join or concatinate two sentences with SEP token and the resultant output gives us whether two sentences are similar or not.
Dataset
Quora's question pairs dataset is the one we are going to use in which we are simply going classify whether two question are duplicates or not as they are many question asked on quora website which are basically the same or redundant questions.
Loading the dataset using pandas .
import pandas as pd
df=pd.read_csv('questions.csv')
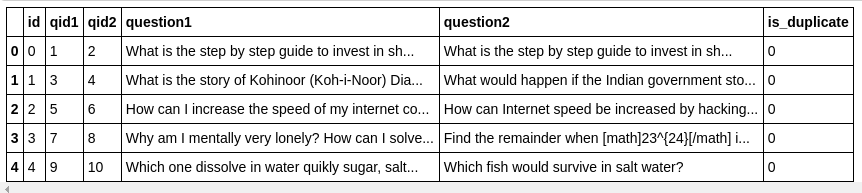
df.head()
Dataset should look like this:
As most of the setup code for configuring BERT ,converting the input specific format for feeding into the BERT Model ,Tokenization , Padding and trucnting would going to similar as in Text Classification article so i'm not going to repeat those steps here please see that article .
The thing we are going to different in this case it combining two sentences as a single one , then feed into the network.
Coding implementations :
#Storing two questions in different list
sent1=df.question1.values
sent2=df.question2.values
labels=df.is_duplicate.values
input_ids = []
tokenize_text=[]
for i in range(len(sent1)):
#As we have to tekenize these sentences and add special tokes such as CLS and SEP
encoded_sent = tokenizer.encode(
sent1[i],
sent2[i],
add_special_tokens = True,
max_length=64
)
input_ids.append(encoded_sent)
print('Original: ', sent1[0],sent2[0])
print('Token IDs:', input_ids[0])

We are still going to use BertForSequenceClassification variation of BERT from hugginface librabry.
from transformers import BertForSequenceClassification
Training :
Code for Training of BERT for sentence classification is same as for text classification the only change is that we are inputing a vector which is combination of two sentences , So please to my "Application of BERT : Binary Text Classification" article.
for epoch_i in range(0, 1):
# ========================================
# Training
# ========================================
print("")
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))
print('Training...')
t0 = time.time()
total_loss = 0
model.train()
for step, batch in enumerate(train_dataloader):
if step % 40 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
model.train()
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
loss = outputs[0]
total_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
model.zero_grad()
Continuing training from checkpoint:
You can use the following code if you having problem in fine tuning in single time .
from transformers import get_linear_schedule_with_warmup
epochs = 1
total_steps = len(train_dataloader) * epochs
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0,
num_training_steps = total_steps)
model2=torch.load('models/sent_bert1.pth')
model.load_state_dict(model2)
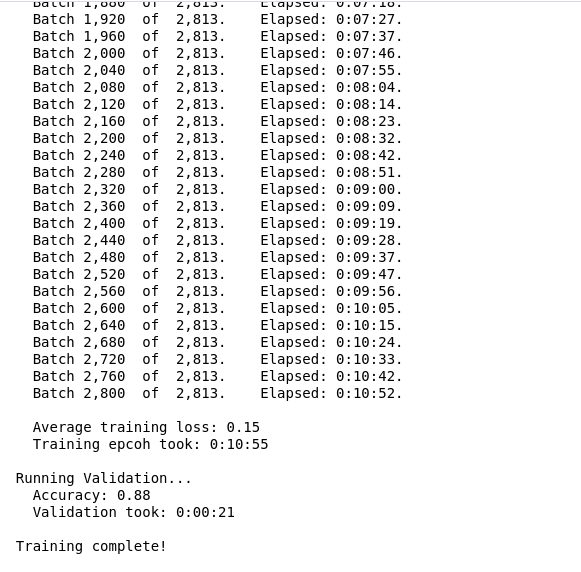
After training(fine tuning) for about 30min and 3 epochs i get around 88% accuracy , 83% f1 score , 86% precision score which is pretty high on this dataset.
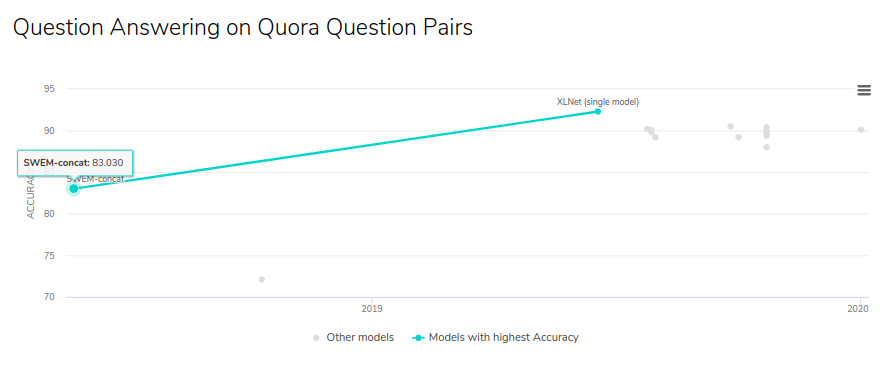
You can see state of art results on this dataset on paperswithcodeRight now state of art model on quora's question pair dataset is XLnet but BERT still performing better than most of the models.
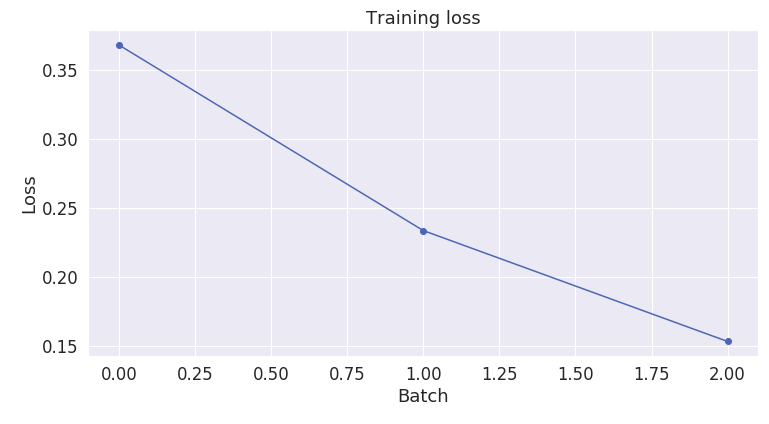
Loss on validation dataset during training for 3 epochs.However there is not much change as only one epoch is enough to fine tune the model which explain the advantage of using BERT as compared to training other model which can easily take upto hours to get good results.
Scope and Endnote:
Sentence similarity is one of the most widely used concept due to its advantages in searches .May be upcoming article we can how can we integrate our similarity model to get a search engine based application. As we only have to go through every corpus and compute is similarity score with the query .As you can see now why BERT is so popular because of the reason that even for different NLP tasks you can easily fine tune them with help BERT.