
Introduction
Data preprocessing is a process of working with the raw data to make it suitable for use with a machine learning model. It is the first and most crucial step while creating a machine learning model. In the context of NLP, it turns the raw text data into a format that ML models can understand by reducing noise and ambiguity in the text data.
Some examples of preprocessing tasks in NLP include:
As can be seen, the first two points have been covered upon in previous articles. The aim of this article would be to elaborate upon the third example i.e. Stemming - the concept behind it, it's use cases, suitabillity and implementation in Python and to provide a basic idea of said topic to the readers.
Concept
In the context of Natural Language Processing, Stemming is a technique used to reduce a given word to its base form that is, the removal of prefixes and suffixes from words to obtain their root or stem.
For example, the words "running", "runner", and "runs" would all be reduced to the root word "run" through stemming.
Stemming serves to simplify the analysis of text data by reducing the number of unique words that need to be processed.
For example, in the sentence -
"Rahul loves running and is an aspiring marathon runner. To prepare for marathon events, he runs 2 miles everyday. "
There are three words "running", "runner" and "runs". In case stemming is not implemented, these three words would be stored, despite the fact that they are similar in nature, which leads to wastage of space. But upon stemming, we need to save a single word i.e. "run". In this manner, Stemming can help in optimising use of storage space.
By reducing different forms of the same word to a common base form, it becomes easier to perform certain NLP tasks, such as sentiment analysis.
Now that we have a basic understanding of the concept of stemming. let's understand it's use cases.
Use Cases
Search Engines: Stemming improves the accuracy of search results in search engines. The search engine can match more documents and produce more pertinent results by condensing all word variations to a single word.
Sentiment Analysis: Sentiment analysis algorithms can better determine the sentiment of a document by condensing all word variations to a single word.
Text Classification: Text classification activities like spam filtering or topic modelling require stemming. It is easier to determine the categories that a document belongs to when all word variations are reduced to a single common stem.
Advantages and Disadvantages of Stemming
Advantages-
- Increased Accuracy: By decreasing the quantity of unique words that are tobe processed, stemming can increase the accuracy of NLP tasks. This may lead to quicker processing times and more precise results.
- Reduced Vocabulary Size: Stemming can also decrease the size of the vocabulary required to complete NLP tasks, which can be helpful when memory or processing capacity are constrained.
- Easier Preprocessing: By condensing many variants of the same word to a single entity, stemming can make preprocessing and by extension, cleaning and normalizing the text simpler.
Disadvantages-
Loss of Details- Stemming can cause the loss of crucial details like a word's tense or part of speech. This can lead to fewer accurate outcomes and/or if not outright wrong - at least a misleading interpretation of the material.
If stemming is not implemented properly, there can be two types of problems namely- overstemming and understemming.
-
Overstemming- When a word is overstemmed, too many letters are taken out, creating a stem that is not a word. This may lead to erroneous outcomes or processing problems.
-
Understemming- When a stemmer doesn't get rid of all the prefixes or suffixes from a word, the outcome is a stem that isn't the word's base form. This may lead to erroneous outcomes or processing problems.
With this, we are through with the theoretical understanding behind stemming. Now let's have a look at the various approaches used in implementing it in Python.
Implementation in Python
Firstly, we shall be trying a naive approach towards implementing stemming in Python, before using libraries like NLTK to implement it.
Porter Stemming Algorithm
The Porter Stemming Algorithm is a process for reducing words to their base or root form.It gradually eliminates suffixes from the words until they can no longer be shortened.
The algorithm employs a number of rules that are executed sequentially, each aiming to eliminate a certain suffix, said rules being based on English syllable and letter patterns.
The objective of the algorithm is to simplify words so they can be compared or evaluated more quickly. Although this method has flaws and occasionally yields inaccurate results, it nonetheless offers a fundamental grasp of how stemming algorithms work.
Let's first define a list of example words on which the algorithm will be applied.
words = ["running", "runner", "runs", "ran", "easily", "fairly"]
This line defines a list of example words that we will use to demonstrate the implementation of the Porter stemming algorithm.
We shall be taking a functional approach to this question and implement it using functions in Python.
def porter_stemmer(word):
suffixes = {"sses": "ss",
"ies": "i",
"ss": "ss",
"s": "",
"eed": "ee",
"ed": "",
"ing": ""}`
This line defines the function identifier and a dictionary called suffixes that maps suffixes to their corresponding replacements.
for suffix in suffixes:
if word.endswith(suffix):
stem = word[: -len(suffix)]
if len(stem) > 1:
if suffix in ["ed", "ing"]:
if (
stem[-2:] == "at"
or stem[-2:] == "bl"
or stem[-2:] == "iz"
):
stem += "e"
elif (
stem[-1:] == stem[-2:]
and stem[-1:] != "l"
and stem[-1:] != "s"
and stem[-1:] != "z"
):
stem = stem[:-1]
elif (
(len(stem) == 3)
and (stem[-1:] == "w" or stem[-1:] == "x" or stem[-1:] == "y")
):
stem += "e"
word = stem + suffixes[suffix]
return word`
We will loop over each suffix in the suffixes dictionary and check if the input word ends with that suffix. If yes, the suffix is removed from the word and and the resulting stem is assigned to the stem variable.
Now we check if the length of the stem is greater than 1, which is a requirement for the stem to be modified by the rules of the Porter stemming algorithm. If the suffix is "ed" or "ing", said rules are applied depending on the last two letters of the stem.
The word is then reconstructed by appending the appropriate suffix replacement from the suffixes dictionary to the stem and then returned.
Driver Code-
stemmed_words = []
for word in words:
stemmed_word = porter_stemmer(word)
stemmed_words.append(stemmed_word)
for i in range(len(words)):
print(f"{words[i]} -> {stemmed_words[i]}")
In this driver code, the porter_stemmer function is applied to each word in the example list and the resulting stemmed words are stored in a new list called stemmed_words. Also, the original and stemmed versions of each word in the example list are displayed side-by-side.
Output-
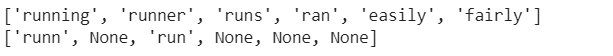
As it can be seen, the algorithm was able to stem only a few words out of all which were supplied to it.
Time and Space Complexity-
The algorithm applies the rules to a word character by character until it reaches the end of the word. Since the length of the word decides the number of iterations, time complexity of the porter_stemmer(word) function is O(N) where N= length of the word to be stemmed.
However, do note that this time is only for one word. When used in the driver code, the time complexity of the entire process becomes O(N*L) where N= length of the word to be stemmed and L = number of words in the word list.
Coming to space complexity- The algorithm creates a new string for each change made. At most, a stem could be modified by all the rules in the function, meaning that the space occupied by processing of one word would be directly proportional to it's length. Therefore, the space complexity per word for the algorithm would also be O(N) where N= length of the word to be stemmed.
Stemming using NLTK
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
words = ["running", "runner", "runs", "ran", "easily", "fairly"]
for word in words:
print(word," : ",stemmer.stem(word))
The implementation of stemming using NLTK is quite straightforward as it only involves importing of the NLTK library and calling the Porter Stemmer Method in a for loop. The rest of the code is self explanatory.
Output-

We can see that although all the words returned a response, some root words were not mentioned correctly. However, this is a significant improvement from before as the earlier method was not able to return a response on being passed certain words.
Time and Space complexity
Both the time and space complexities of the PorterStemmer method depend on the length of the input text and the length of the list of words.
The worst case time complexity for this method can be O(N * M), where N = number of words in the input text, and M = maximum length of a word, as each word in the input text is analyzed by the algorithm and a set of applicable stemming rules are applied to it. This process takes time directly proportionate to the length of each word.
Regarding space complexity, The PorterStemmer() method has a space complexity of O(M), where M is the length of the longest word possible, as the algorithm simply needs to store the word that is currently being stemmed as well as any intermediate outcomes from using the stemming rules.
Manual approach vs NLTK
| Naive implementation | PorterStemmer() from NLTK |
|---|---|
| More lines of direct code involved. | Lesser number of lines of direct code involved. |
| Less Efficient in removing suffixes. | More efficient in removing suffixes. |
| Time complexity per word is O(N) where N = length of word. For the entire list of words, it is O(N*L), L being the length of the list of words. | Worst case time complexity of this method is O(N * M), where N is the number of words in the input text, and M is the maximum length of a word. |
| Space complexity is O(N), where N = length of word. | Space complexity is O(M), where M is the maximum length of a word. . |
Questions to consider
Let's have a look at a few questions.
Q1)Which implementation approach out of the two mentioned is more practical?
Let's have a look at a few questions.
Q2)What is the effect of stemming in a sentiment analysis task?
With this article at OpenGenus, you must have the complete idea of Stemming in NLP.