
You might have seen URL shortener services such as TinyURL or Bit.ly which are used for using a short alias instead of long URLs. Even wondered why and how these kinds of applications work? In this article, we'll be discussing the system design of a URL shortener and compare it with some applications currently in use.
Before reading this article, it is suggested if you could go and try out tinyurl.com so that you could understand this article better.
What is the need of using this?
Why do we need to shorten the URL? Is it something necessary? Well, there are many advantages that shortening of URL provides. A very basic advantage could be that users tend to make very few mistakes while copying the URL if it is shortened. Secondly, they surely save a lot of space when used or printed. Moreover, it could be used if someone wishes not to use the original URL.
Expected features in the system
- The system should be able to generate a short link that is easy to copy.
- That short link should be able to redirect the page of the original link.
- The service should be available throughout the day.
- There should be an option for the user to be able to pick a custom name.
- Shorter links should not be able to guess and redirect should happen with minimum latency (delay).
- The service should maintain the analytics.
System Constraints
Estimating Traffic:
Let us assume 300M fresh URL shortening requests coming up each month. It is safe to assume that our service would have more requests for redirection as compared to shortening. Let's take the request ratio to be 50:1 between redirection and shortening. So, there would be around 50 X 300M = 15B redirections per month which is around 300 M / (30 days * 24 hrs * 3600 sec ) * 50 = 5K URL redirections in a second.
Estimating Storange and URL length:
Let's assume, we store URL requests for a period of 2 years. So, the number of objects to be stored would be around: 300 M * 2 yrs * 12 months = 7.2 B.
The size of each object is taken around 500 bytes, which will give an estimate of storage needed which would be around 7.2 B * 500 bytes = 3.6 TB
Estimating Memory Requirements:
According to the 80-20 rule, 80% of the traffic will be generated by 20% of the URLs, so it would be better to cache these 20% URLs. We have around 5K redirection requests per second, which would be around 5k requests * 60 secs * 60 mins * 24 hrs = 432 M requests per day.
The memory required to cache around 20% of these would be 0.2 * 432 M * 500 bytes = 43.2 GB. Considering, there could be multiple requests for the same URLs, so 43.2 GB is the upper limit for the memory requirement.
Bandwidth Required:
For URL shortening, there would be about 50 requests in a second, so the incoming data would be around 50 * 500 bytes = 25KB/s.
For URL redirection services, in a similar way the outgoing data would be around = 5K * 500 bytes = 2.5 MB/s.
Database to be used
First of all, we need to figure out what type of data we need to store in the database, and then we will further discuss the scalability of the database.
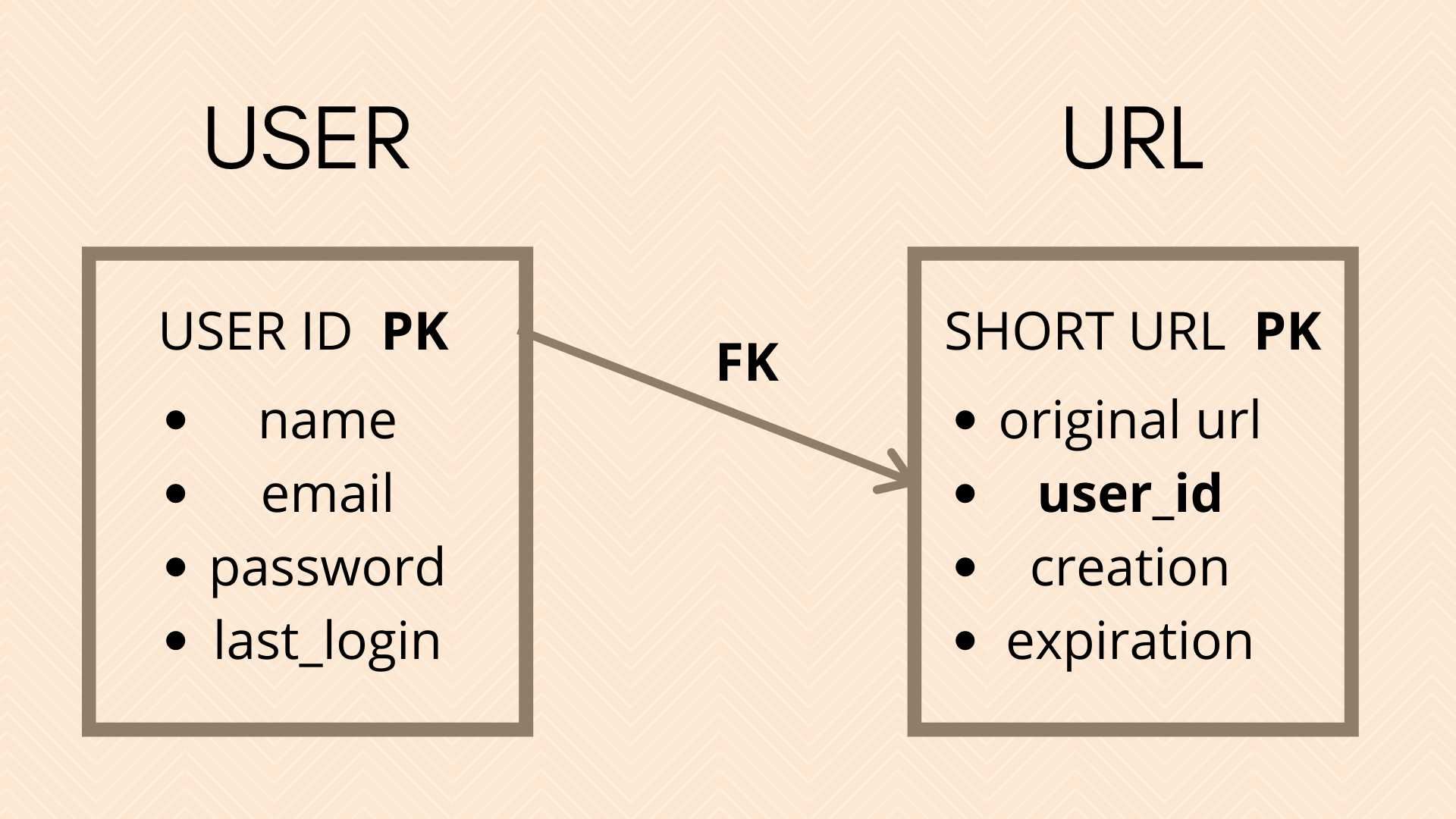
Some points before considering whether to use SQL or NoSQL for the database:
- We only need to store which user has requested the shortening of the URL.
- As stated earlier, the system would handle more redirection requests as compared to shortening requests.
- The system is expected to have minimum latency in the redirection.
- The object size is not that large. (Around 500 bytes)
- SQL databases are always preferred when complex query retrievals are involved in a system and the system has a complex database schema.
- Scaling Relational or SQL databases would increase the complexity of the system considering the number of queries to be dealt (with Around a billion records to be stored).
Considering the above points, a NoSQL database seems like a wise choice. Examples of NoSQL databases include Amazon's DynamoDB, Facebook's Cassandra, and many more.
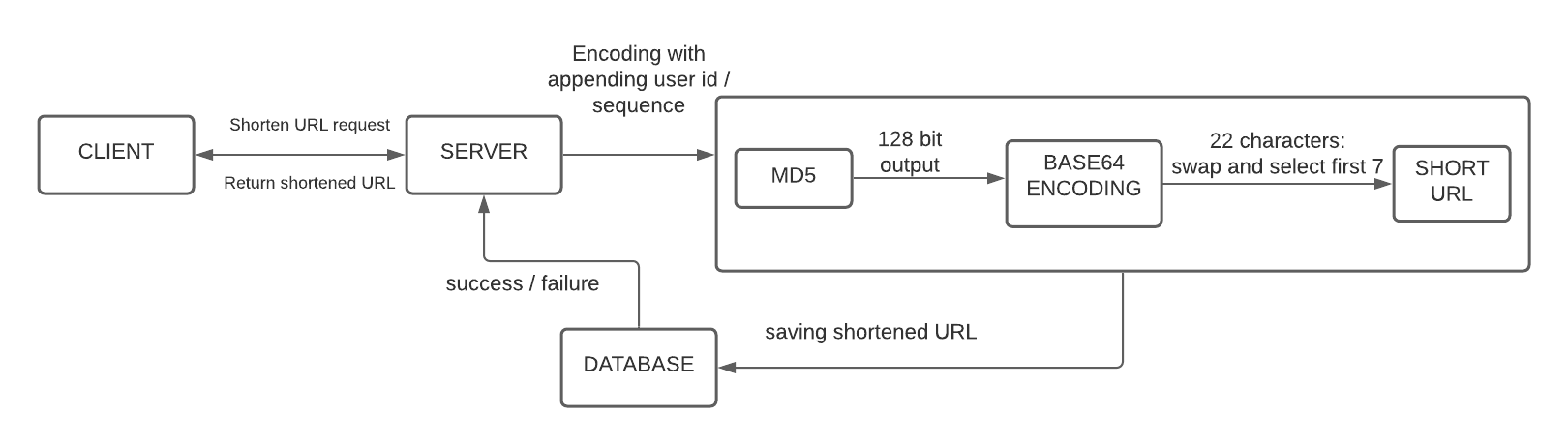
Algorithm for URL shortening
For generating a short URL that is unique from an existing URL, we could use hashing techniques for the same. The hash which is to be encoded, could be in Base36 ([a-z ,0-9]), Base62 ([A-Z][a-z][0-9]) or Base64 ([A-Z][a-z][0-9],’+’,’/’). Let us consider Base64 encoding as it contains all characters which can be included in a URL, then what length should be the appropriate length of the shortened URL.
URL Length = 6, => 64^6 = ~70 B possible URLs
URL Length = 7, => 64^7 = ~5 T possible URLs
URL Length = 8, => 64^8 = ~280 T possible URLs
Length of URL:
For our system memory requirements, the length of 6 characters is more than sufficient. (Even if we store the data for 5 years, we will merely store around 20B URLs)
Using MD5 hashing:
After using the MD5 hashing algorithm which generates 128 bits hash value, we will have 22 characters as the output, since Base64 encoding will use 6 bits for representing a character. In this case, we can randomly select 7 characters or swap some characters and select the first 7 characters.
Some issues that we can encounter with this algorithm:
- What if two same URLs could produce the same shortened URL links even after randomization and swapping?
- https://iq.opengenus.org/author/pul/ could be URL encoded into https%3A%2F%2Fiq.opengenus.org%2Fauthor%2Fpul%2F (UTF-8 encoding scheme). The above algorithm will produce two different shortened URLs.
Possible solutions for the above could be:
- One solution to the first problem could be to append the user id (primary key) after he is logged in, to the original URL and then apply the algorithm.
- Another solution could to maintain an increasing counter with the URLs and appending it with the original URL. (But this solution could lead to sequence overflow after a particular limit)
- For the second issue, the simple solution is to accept only UTF-8 URLs, if it is encoded then we need to convert it first into UTF-8 and then apply the algorithm.
Database Sharding or Partition
We need to scale our database to store around a billion URLs. We need to partition our data into different machines to increase the capacity or storage.
We can work out a solution for partitioning based on Hashing. A hash function could be used to decide the machine number for the particular URL.
Let's suppose we decide to partition our data into 512 machines/shards, then:
HASH(shortened URL) = Machine Number (0-511)
Load balancing
Load balancers are generally used to resolve the issue of limited bandwidth and single-point failures which could improve the response and availability of an application.
Load balancers could be placed between these layers:
- The client and the server.
- The server and the database.
Round Robin approach could be followed initially to equally divide load among the servers. But this could pose a problem that it does not look on the server load, so even if it is slow, this approach will keep sending the requests. So, a better approach would use the Least Bandwidth approach wherein it sends the request to the server with the least load.
In this way with this article at OPENGENUS, we could design a system for URL shortening service which is scalable in the real environment.