
Introduction
We shall be looking at a type of non-relational database called Wide-column stores. Last time, we looked at Time-series databases and we saw how they worked and how to apply them in certain use cases. So this article will be focusing entirely on Wide-column stores in the same manner we looked at Time-series databases. Keep reading further if you are interested in finding out.
Table of contents
- What is a wide-column store?
- Examples of wide-column stores
- Implementaion and use cases
- Benefits of wide-column stores
- Drawbacks of wide-column stores
What is a wide-column store?
A wide-column store a type of non-relational (NoSQL) database. It is used to store data in records and have the capability of holding exponential amounts of dynamic columns. Dynamic columns because a wide-column store is used to make a read or write query on column values.
Wide-column stores are different from column stores because unlike column stores, the columnar data layout on wide-column store is such that each column is not stored separately on a disk. This done (columnar stores) to improve the read and write performance of a relational database/store for OLAP workloads and stores the data of a table in columns rather than in records. Wide-column stores already come inherently with this functionality unlike relational systems that implement column oriented storage.
Examples of wide-column stores
Some notable exampled of wide-coulmn stores include the following undermentioned:
- Apache Caasandra
- Apache HBase
- DataStax
- Bigtable
- Hypertable (not to be mistaken for TimescaleDB hypertables)
Like I did previously for the time-series database article, I shall be focusing on one specific wide-column store type throughout the article to give a solid explanation on the workings of wide-column stores. Let’s focus on Bigtable in this scenario
Bigtable is a comprehensive wide-column store that is used for substantial analytical and operational workloads. It was designed and created by a group of Google database engineers in 2004 and has been leveraged on by a number of Google applications. It was developed for four main reasons:
- Scalability
- Better grasp on performance attributes.
- Wide applicability
- High Availability
Since its inception, Bigtable has served as a base for most RDBMS (relational database management systems) and some wide-column stores including Apache Cassandra and Apache HBase. It was made public on Google Cloud after been proprietary for nearly 11 years.
Design, Implementation and Use Cases
Design
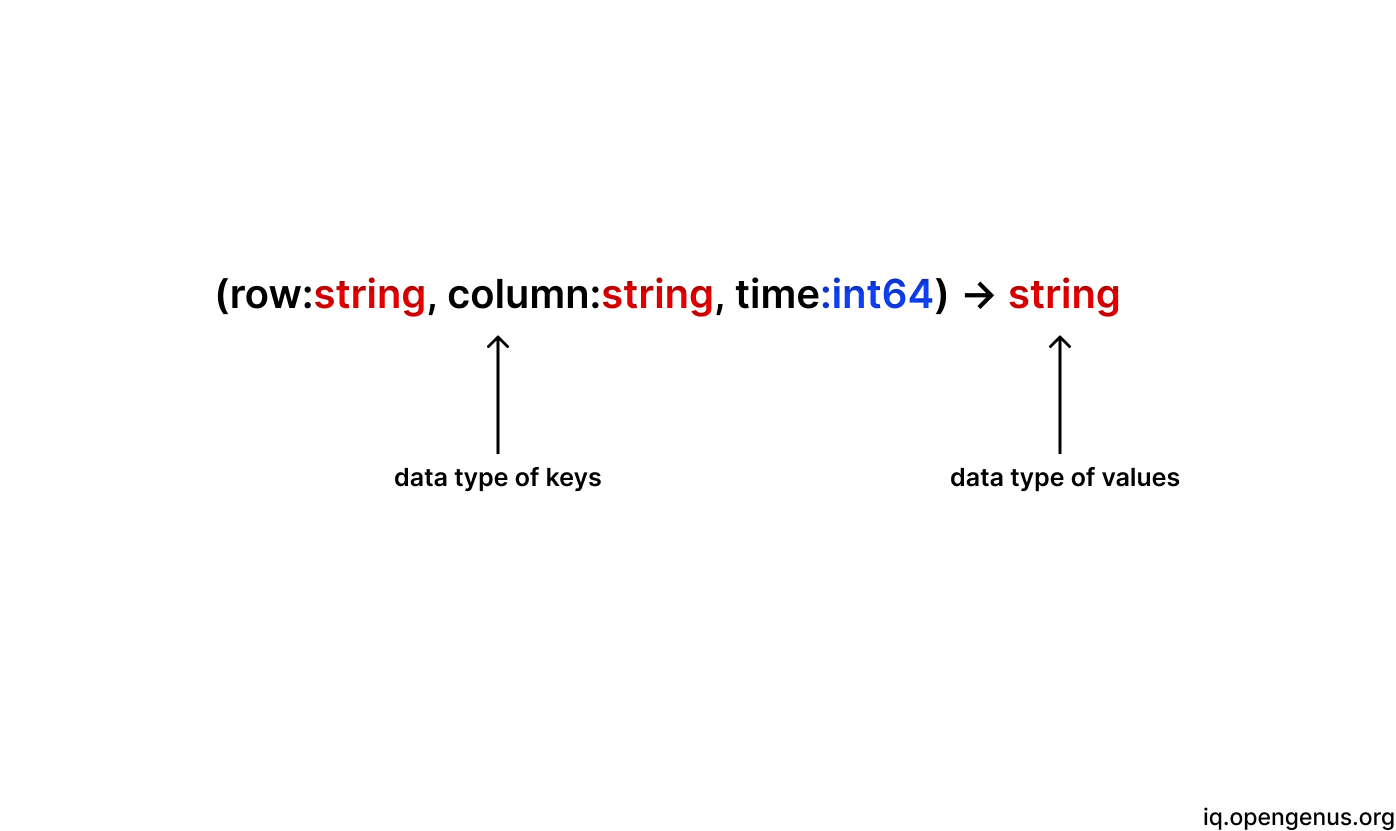
Bigtable is known as distributed and persistent multidimensional sorted map for dealing with sparse data. The map is indexed by:
a row key, a column key and a timestamp.
Sparse data are compact amounts of information captured within a heavy collection of redundant data.
- Rows
- Every read and write query performed on data in a single row is atomic.
- Lexicographic ordering by row key is done to maintain data.
- Each row range is dynamically partitioned and is called a tablet.
- Can be used to select a good locality for data access
- Column family (grouped column keys)
- Basic unit for access control.
- All data stored in a column family are of the same type.
- A family must be created before any column key within the family can be used.
- A table can have a near-unlimited number of columns within column families.
- Access control, disk and memory accounting are carried out at the column family level.
- Timestamps
- Every column cell can contain multiple versions of the same data that are indexed by a timestamp.
- Different versions of a cell are stored in order of decreasing timestamp in order for the most recent version to be read first in a query.
Implementation
Bigtable has three major components that make up its core implementation. These components are:
- A library linked to every client.
- A master server
- Many tablet servers
The library enables clients to communicate directly with tablet servers for queries without relying on the master as a bridge to provide information on tablet location. This invariably lightens the master’s workload.
The master controls the assigning of tablets to tablet servers. It also detects the addition and expiration of tablet servers and balancing of tablet-sever load, as they (tablet servers) can be added or removed dynamically from a cluster in response to changes in workloads. It also handles column family creation in a table.
The tablet server manages a set of tablets as assigned by the master. It also handles read and write queries to the tablets that it manages and downsizes tablets that have grown exponentially large in size.
Use Cases
Wide-column stores works optimally for situations where:
- There are more write queries than read queries.
- Update of data is rarely done.
- there is no need for JOIN or aggregate operations.
Example of use cases like this are:
- Workloads the require OLAP (Online Analytical Processing).
- IoT metrics and sensor data.
- Time-series data.
- Logging data.
Benefits of Wide-column stores
There are several benefits that come with using a wide-column store. Most readers might have already picked up on some these benefits impliclty laid out when explaining Bigtable in the article. Some of the benefits of wide-column stores include:
- Exponential scalability; wide-column stores can scaled to handle data up to the petabyte range. Recent workings on some wide-column stores have seen them theoretically scale up to the exabyte range albeit in single digits.
- Support for data compression; wide-column stores allows for compression of similar attributes which leads to faster query times and less storage space.
- Support for partial operations on column values (ADD and UPDATE).
Drawbacks of Wide-column stores
Wide-column stores too come with thier own drawbacks and disadvantages, some of which are:
- Not optimized for joins or aggregations.
- Not optimized for performing read queries on extremely large datasets.
- Updates are inefficient because they group columns of attributes unlike RDBs (relational databases) that group rows of tuples.
- They perform poorly with OLTP (Online Transactional Processing) workloads.