
Reading time: 30 minutes
XGBoost is short for extreme gradient boosting. It is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. The same code runs on major distributed environment (Hadoop, SGE, MPI) and can solve problems beyond billions of examples.
In this article, we will first look at the reason behind using XGBoost and then deep dive into the inner workings of this popular and powerful technique.
Why use XGBoost?
The main reason why we use XGBoost is that it's library rely on:
- model performance
- execution speed.
As it is proved that XGBoost outperforms several other well-known implementations of gradient tree boosting.
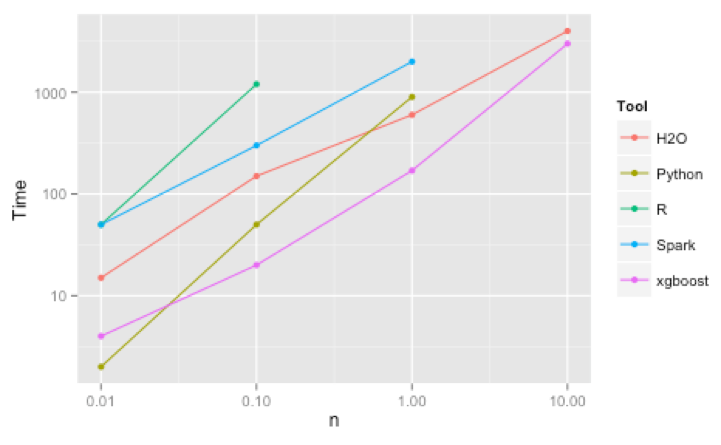
In Figure 1 we can see the power of the different tools and we can find that how well balanced XGBoost tool's benefits are, i.e., it does not seem to sacrifice speed over accuracy or vice versa. It starts to become clear why more people in this field are using it every day, it is a semi-perfect equilibrium of both performance and time-efficiency.
How does it work?
In Gradien Boosting, our main focus is to convert weak model into strong one.
For that purpose, we add models on top of each other iteratively, by doing this the errors of the previous model gets corrected by the next predictor, until the training data is accurately predicted or reproduced by the model.
This method fits the new model to the previous prediction and then minimizes the loss while adding the latest prediction. So, in the end, we are just updating our model using gradient descent and hence the name comes gradient boosting.
This method is used for both regression and classification problems. XGBoost specifically, implements this algorithm for decision tree boosting with an additional custom regularization term in the objective function.
Unique features of XGBoost:
XGBoost is a popular implementation of gradient boosting. Some of the features of XGBoost are as below:
- Regularization: XGBoost corrects complex models through regularization. Regularization also helps in preventing overfitting.
- Handling sparse data: Data processing steps like one-hot encoding make data scattered. XGBoost incorporates a sparsity-aware split finding algorithm to handle different types of sparsity patterns in the data.
- Weighted quantile sketch: Most of the tree based algorithms can find the split points when the data points are of equal weights. However, they are not capable of handling weighted data. XGBoost has a distributed weighted quantile sketch algorithm to effectively handle weighted data.
- Cache awareness: In XGBoost, non-continuous memory access is required to get the gradient statistics by row index. Hence, XGBoost has been designed to make optimal use of hardware. This is done by allocating internal buffers in each thread, where the gradient statistics can be stored.
- Block structure for parallel learning: For faster computing, XGBoost can make use of multiple cores on the CPU. This is possible because of a block structure in its system design. Data is sorted and stored in in-memory units called blocks. Unlike other algorithms, this enables the data layout to be reused by subsequent iterations, instead of computing it again. This feature also serves useful for steps like split finding and column sub-sampling.
- Out-of-core computing: This feature optimizes the available disk space and maximizes its usage when handling huge datasets that do not fit into memory.
Conclusion
So that was all about the popular XGBoost algorithm. It is a very powerful algorithm and while there are other techniques that have origined from it (like CATBoost), still XGBoost remains the lifeline in the machine learning community.