
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Reading time: 30 minutes
AVX512 Vector Neural Network Instructions (AVX512 VNNI) is an x86 extension Instruction set and is a part of the AVX-512 ISA. AVX512 VNNI is designed to accelerate convolutional neural network for INT8 inference.
The key idea is to merge three instructions (which occur consequentively in CNNs) into one instruction and hence, saving 2 clock cycles. The advantage comes from the fact that:
- These three instructions occur frequently in Convolutional Layer
- Convolutional layers are the most computationally expensive layers in a Neural Network
Introduction
In VNNI, there are two instructions that has been introduced which are:
- VPDPBUSD(S)
- VPDPWSSD(S)
Both instructions take:
- Either INT8 or INT16 for both weights and input data
- Does multiplication in INT8 or INT16
- Uses INT32 accumulation
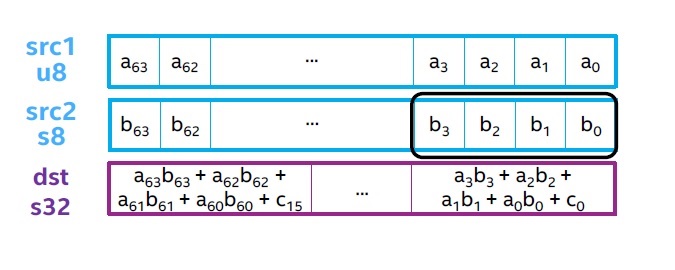
VPDPBUSD
This is the VNNI instruction for INT8.
vpdpbusd zmm0, zmm1, zmm2/m512/m32bcst
s32 <- s32 + Σ u8 ∗ s8
vpdpbusds zmm0, zmm1, zmm2/m512/m32bcst
s32 <- saturate<s32>(s32 + Σ u8 ∗ s8)
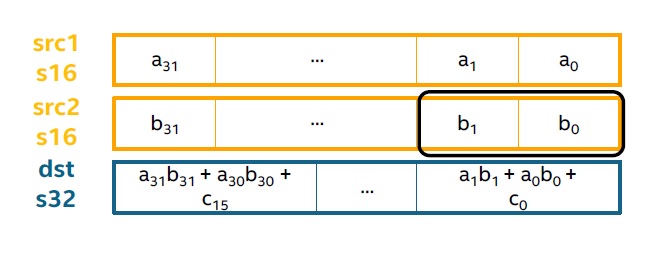
VPDPWSSD
This is the VNNI instruction for FP16.
vpdpwssd zmm0, zmm1, zmm2/m512/m32bcst
s32 <- s32 + Σ s16 ∗ s16
vpdpwssds zmm0, zmm1, zmm2/m512/m32bcst
s32 <- saturate<s32>(s32 + Σ s16 ∗ s16)
Background on INT8:
The most common data types for Convolutional Neural Networks (CNNs) are:
- Training: fp32, fp16, bfloat16 and int16
- Inference: fp32, fp16 and int8
In general, INT8 is preferred to FP32 because of the following reasons:
- Better performance (instruction throughput)
- Lower memory consumption (higher bandwidth and better cache usage)
- Acceptable accuracy loss
INT8 inference means that the input and calculations are done in INT8 but the output produced is in FP32. This gives performance improvements as during calculations we are dealing the smaller data.
AVX512 VNNI improves it further by nearly a factor of 3X.
Note that AVX512 VNNI is applicable for INT8 only.
Key idea in AVX512 VNNI
The basic idea of VNNI is to merge multiple systems calls used in Convolution call to improve the execution performance. A key component of convolution is this code section of multiplication:
for i = 0 to 15 (batch size)
for j = 0 to 3 (channel)
dst32[i] += src1u8[4i + j] * src2s8[4i + j]
src1u8 is data, src2u8 is weight and dst32 is output. Data and weight is INT8 but output is FP32.
If you generate the instructions generated for Convolution, you will find that this set of instructions is repeated several times (> 10000):
pmaddubsw zmms16, src1u8, src2s8
vpmaddwd zmms16, zmms16, [16 x 116]
vpaddd dsts32, dsts32, zmms16
This is for AVX512 only. Note:
- pmaddubsw is for Multiply and Add Packed Signed and Unsigned Bytes
- vpmaddwd is Multiply and Add Packed Integers
- vpaddd is Add Packed Integers
Intel's idea is to merge these 3 calls to one call which will theoretically give 3 times improvement in performance. To put into prespective, think of a task that takes 3 minutes and now, it will take 1 minute.
It is replaced by this VNNI call:
vpdpbusd dsts32, src1u8, src2s8
Note that the input (src1u8, src2s8) and output (dsts32) is same.
This optimization needs to be done at the programming language level or by the compiler. Compilers and most programming languages support AVX512 and the support for VNNI exists at the compiler level.
Intel's Machine Learning library MKL-DNN (also known as DNNL) supports INT8 calls and hence, takes advantage of AVX512 VNNI calls.
Intel's CascadeLake CPU and further releases support AVX512 VNNI. Note that if you try in an earlier version, you will not find such instructions as the system does not support them.
Conclusion
AVX512 VNNI can greatly improve Machine Learning inference times but there are a few catches:
-
Currently, AVX512 VNNI is supported only in latest Intel CPUs. If you want to take advantage of this, you need the latest systems.
-
AVX512 VNNI requires INT8 inference. INT8 inference is in active research but has not been well developed due to which it is not being used in major production systems. The challenge is that moving to INT8 improves performance but decrease accuracy as well.
Do you want a code base to try this?
Use MKLDNN's INT8 inference example and see the instructions you generate. To see AVX512 VNNI instructions, you need latest CPU like Cascade Lake or you can stimulate it using Intel SDE.
With this, you have the complete idea of AVX512 VNNI instructions.