
Reading time: 30 minutes | Coding time: 15 minutes
We come across numerous situations wherein we are required to perform operations on 1D data structures such as strings, integer arrays etc. We may have to find the properties of multiple strings or perform operations like string comparison and so on.
So what is the best way to store all this data?
One method is to store the entire string to compare it with another string.
This will be an O(m+n) comparison.
Some very common data structures that adapt to the string data type pretty easily are Tries, Suffix trees, Binary Trees etc. These data structures have good complexity in theory, but it is not an easy task to optimise them for a given problem per se.
The more efficient way is to store the hash of these strings.
In practice Hashing has one of the best complexities with a fantastic O(1) constant search time.
In this article, we will explore hashing in terms of Bloom Filters and compare it with different data structures.
What are Bloom Filters?
Bloom filters are approximate or probabilistic data structures.
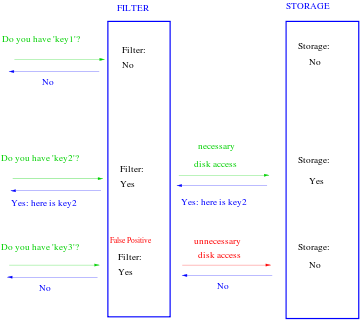
It is a data structure that tells whether an element may be in a set, or definitely isn’t.
The only possible errors are false positives: a search for a nonexistent element can give an incorrect answer.
Bloom filters are both fast and space-efficient. However, elements can only be added, not removed. Probabilistic data structures will give us memory-efficient, faster results with a cost of providing a ‘probable’ result instead of a ‘certain’ one.
Learn about Bloom Filter in detail
Structure
Bloom filters are nothing but an array of 1s and 0s. It gives a probabilistic value for whether a string has been searched earlier. But guarantees when the string has not been searched.
A bloom filter is characterized by the following parameters :
-
N : number of strings
-
M : Length of the bloom filter
-
K : number of Hash functions
Since there are K hash functions => K bits will be set in the bloom filter of size M.
Hash functions
For the hash functions that Bloom filters use, collisions in the outputs don’t really matter too much, as long as they’re reasonably rare. It’s more important for the outputs to be evenly and randomly distributed. And, of course, we want our hash functions to be fast.
Bloom filters can be extended to multiple levels - multilevel bloom filters.
Diagramatic Example
Here is a Bloom filter with three elements x, y and z. It consists of 18 bits and uses 3 hash functions. The colored arrows point to the bits that the elements of the set are mapped to.
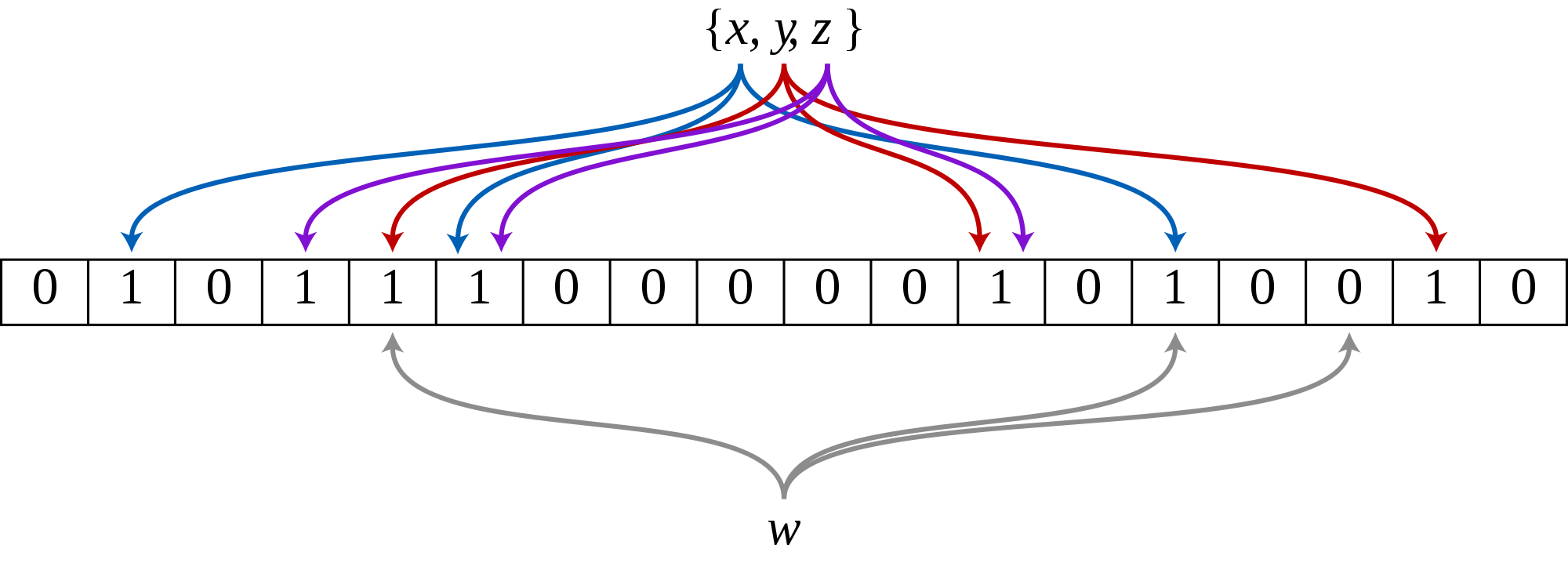
The element w definitely isn’t in the set, since it hashes to a bit position containing 0.
Correctness and Altering the value of K
The probability of reporting a false positive in bloom filters is :
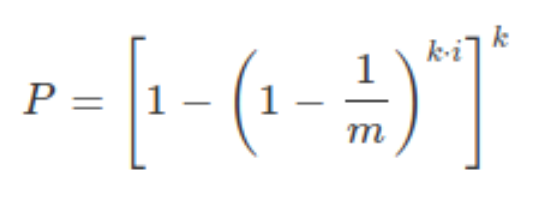
In a bloom filter, K is the number of hash functions that a particular string has to pass through.
The effect of the number of hash functions on the error rate is shown by the following graph
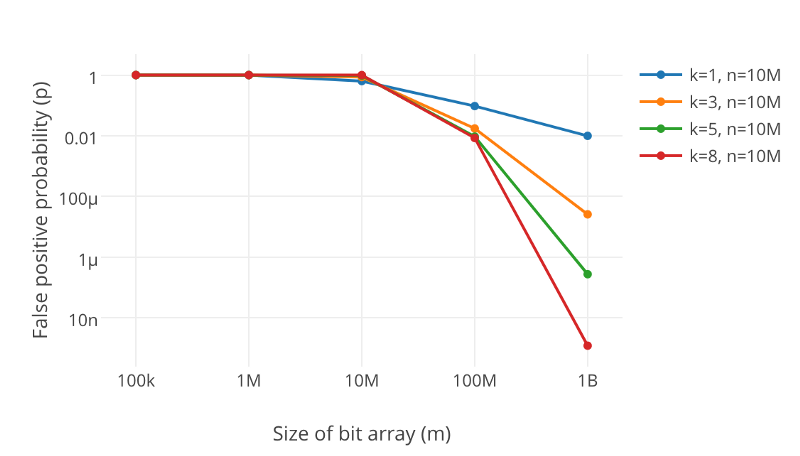
From the above probability equation and the graphs show, we infer that there is an optimal value of K that can be obtained as follows :
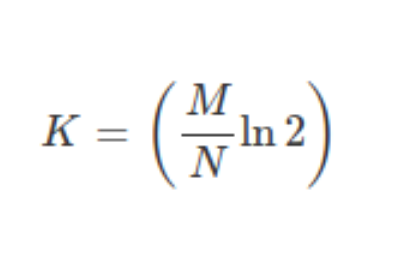
Complexity
For a fixed error rate :
-
Time Complexity : Adding a new element and testing for membership are both Constant Time - O(1) operations,
-
Space Complexity: A bloom filter with room for n elements requires O(n) space.
HashTables vs Bloom Filters - let's hash it out
-
Storage of objects:
- In Hashtables the object gets stored to the bucket(index position in the hashtable) the hash function maps to.
- Bloom filters don’t store the associated object. Just tells the presence or absence of it.
-
Space utilization:
- Hashmaps are less space efficient as all (note: most) of the strings must map to a certain location.
- Bloom filters are more space efficient as it is just an array of 0 and 1s according to the hash functions in the bloom.
-
Deletion operation:
- Hashmaps supports deletion - they can just mark that location of the object as NULL again.
- Bloom filters do not support deletion. We have to reset a bloom filter entirely to restart.
-
Accuracy of results:
- Hash Tables give more accurate results.
- Bloom filters have small false positive probability.
-
Collision handling:
- We have to minimize collisions in hash tables so must choose multiple hashes or a strong hash.
- A bloom filter uses many hash functions. There is no need to handle collisions.
-
Uses
- Hashmaps are used in compiler operations, programming languages(hash table based data structures),password verification, etc
- Bloom filters have application in network routers, in web browsers(to detect the malicious urls),in existing username checkers, in password checkers etc.
Comparing Tries, BSTs and Bloom Filters
-
Tries have the limitation of being useful only for strings. BSTs and Bloom filters can account for various other data types and miscellaneous structs.
-
Complexity for Insertion and Search :
-
Tries:
O(string length) -
BST:
O(string_length * height)[As the entire string is being stored at each node, we must compare the entire string h number of times] -
Bloom:
O(1)orO(hash function)if the hash functions are very complex
-
-
Deletion: Cannot occur in bloom filters but can in the other two
-
Space complexity:
- Tries are better than BST as they do not store overlapping prefixes again and again.
- Bloom filters work with hash functions so they are obviously the best of the lot.
-
Tries and BSTs can store the entire string but the Bloom Filter can only tell the presence / absence of it, not recover it (limitation).
Conclusion
The most significant advantage of Bloom filters over other data structures such as self-balancing tress, tries, HashMaps is in terms of space utilization.
Any data structure implemented in order to store a set of elements (ordered or unordered) stores each element in its enitreity. The storage requirement in this case can range from a few bits to several bytes.
Furthermore, there are overhead costs associated with certain data structures. For eg: linked lists require additional linear space overhead for pointers.
As mentioned earlier, the only caveat with Bloom filters is the possibility of a false positive. However with a relatively small error rate (choosing the optimal value for k), Bloom filters on an average require around 9.6 bits per element irrespective of the size of the elements. This is owed to its compact structure and nature of the approximation data structure.
Therefore, if an error rate of ≤ 2% is acceptable, and a few false postives are not harmful to the result, bloom filters are ideal.
Lastly, in order to avoid expensive search operation over disk or network by checking probabilistically beforehand if the element possibly exists, bloom filter is the way to go!
Applications
Listed below are some cool applications of bloom filters :
- Web browsers follow a 4-hit wonder policy to good browser experience. This is done by using multiple bloom filters thus preventing a poor cache and ensuring a faster response time.
- SignUp endpoints use bloom filters to verify duplicate username entries. It utilises the advantage of extremely quick lookups in bloom filters thus significantly improving performances for huge databases, such as your instagram!
- Bloom filters are also used in spell checkers to track the dictionary words.
- Another awesome application is to determine the strength of a chosen password based on a set of predefined security conditions.
- Websites can track their user traffic classifying them as ‘new user’ or ‘returning user’ by maintaining a bloom filter based on the IP address of the visitor.
Trivia Time
Question 1
If the bloom filter returns True, this always implies that the element being searched is present in the database
Bloom filters have a small false positive error, that is for very rare cases, a search for a nonexistent element can give an incorrect answer. This is the only caveat with bloom filters.
Question 2
The advantage of BSTs and Bloom filters over Tries is :
Tries have the limitation of being useful only for strings. BSTs and Bloom filters can account for various other data types and miscellaneous structs.
Read our in-depth article about the uses of bloom filter here