
Data partitioning in simple terms is a method of distributing data across multiple tables, systems or sites to improve query processing performance and make the data more manageable. Data can be partitioned in many different ways and depending on the type of data it is partitioned in different methods.
Table of contents
- The problem / Why Data Partitioning is needed?
- Types of Data partitioning
2.1. Horizontal Partitioning
2.2. Vertical Paritioning - Partitioning Techniques
3.1. Hash Based partitioning
3.2. List Based partitioning
3.3. Range Based partitioning
3.4. Composite partitioning - When should you partiton your data?
- Advantages of partitoning
- Disadvantages of partitoning
- System Design Example
To cleary understand data partitoning let us first understand the problem and why it is required.
The problem / Why Data Partitioning is needed?
To keep things simple let us assume we have one table on company stocks .
The columns present in the database are as follows
- Company Id (Primary Key)
- Company Name (String)
- Location/HeadQuaters (String)
- Stock Price (Float)
- Percentage Change (Float)
- Average Stock Price (Float)
As we keep adding data into our table the size of the table grows , now lets say the size of the table is around fifty million rows and everyday we are adding new companies , querying the stock prices of old companies and updating the average stock price in real time. The issue with such a system is that it is not scalable , as we add more data the time required to perform a simple query increases drastically.With such a system the time required to insert a new row or updating a row will be very slow. This would definetly cause problems for businesses and managing such a system would be very tough.
Data partitoning can be very helpful for such situations where we essentialy break up a large table into smaller parts (could be within ranges like first 100 thousand , next 100 thousand) through which we can query the required tables which will be relatively more faster and more easily managable compared to the previous system.
Types of Data partitioning
Data Partioning can be performed in different ways , here we are going to discuss the two most common ways of performing data partitoning.
There are two types of Data Partitioning:
- Horizontal Partitioning
- Vertical Paritioning
Horizontal Partitioning
In the above example there is a huge database containing multiple rows which has a slow query time making the overall system slow. The data in the large table is horizontally partitioned into two seperate tables where the first table contains the rows 1 to 3 and the second table has rows 4 to 6.
So if we were to query about the username dallasSGood we would be querying partition one and if we query about the username Mandred we would query partition 2.
Each table is associated with a partition ID so that if we query something ,using the partiton Id the database is able to determine the partition it needs to query to get the data.
This is a example of horizontal partitioning where we split the database table horizontally . The table is divided into multiple smaller manageable parts.
The data are stored in a partition which is a group of rows. Each partition can be used and maintained independently from each other.
The aim of horizontal partitioning is to make sure the time required for a query is as minimum as possible. The tables are partitoned based on a column which will be used and the ranges associated to each partition.
Vertical Paritioning
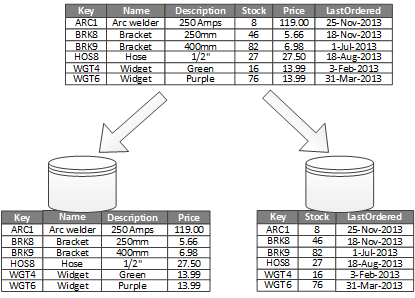
Vertical partitoning we partition the data vertically or based on columns . We divide the tables splitting them on columns and each part is present in a seperate partition.
In the above image we are segragating the the table into two parts where the stock and last ordered are in a seperate partition referenced to the original table by the key.
Vertical partitions can be used in cases where your database is present in SSD and there are a few columns in the database (like in the image above stock and lastordered) there are not frequently queried so the table can be partitoned vertically and the non frequently used columns are moved in some other location.
Vertical partitions can be also be used to restrict access to sensitive data like passwords,salary informations etc.
Partitioning Techniques
Partitioning have many different techniques within by which data can be seperated in different styles and formats.
The different types of Partitioning Techniques are:
- Hash Based partitioning
- List Based partitioning
- Range Based partitioning
- Composite partitioning
Hash Based partitioning
Hashing partition randomly distributes and divides the rows into different partitions based on a hashing algorithm rather than grouping similar rows of the database together.
The data is evenly distributed among the nodes. It is perfect for distributing data among different devices. The partitioning mechanism is quite simple and user friendly when the information to be detached has no set partitioning key.
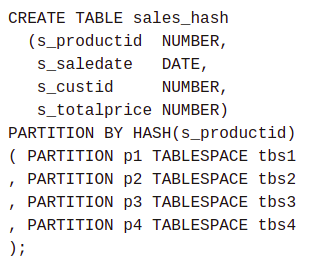
Here is an example where the data is being hash partitioned into four parts based on the product id of the item.
List Based partitioning
List partitioning is used when we need to map rows to partitions based on discrete values. Using this scheme the disimilar or shuffled data can be managed in a comfortable manner.

Here the data is being partitioned based on the region the row belongs to , so that data of each region resides in a single partition .
Range Based partitioning
Range partitioning is used when there is a need to organize similar data especially date and time.It is a convenient method for partitioning historical data.
This partitoning is also used when data is regularly added and there is a need to purge old data from the database.
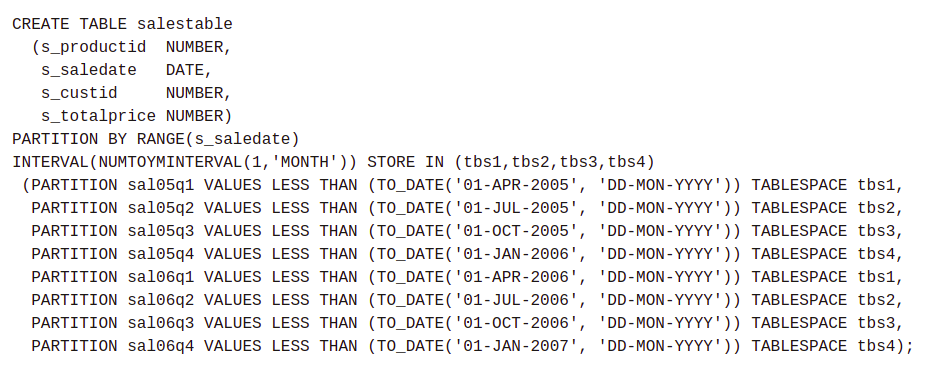
Each parition is divided into date ranges where appropriate rows are moved to and later on becomes easier to purge old data.
Composite partitioning
Composite partitioning combines two or more partitioning techniques for a column. It offeres the benefit of paritioning in multiple dimensions. The data is first paritioned in one way and the output partitions are again partitoned by a procedure.
The various types of composite partitioning are
- Composite Range–Range Partitioning
- Composite Range–Hash Partitioning
- Composite Range–List Partitioning
- Composite List–Range Partitioning
- Composite List–Hash Partitioning
- Composite List–List Partitioning
As the names would suggest the data is first partitioned using the first method and the out partitions undergo the second partiioning procedure. In some cases the same procedure is used for partitions.
When should you partiton your data?
Partitoning might seem useful however not all cases require us to parititon our data. In general partition is useful when
- The data is very large and requires a lot of time for a query to execute
- Tables are too large in size to fit in memory
- The tables contain historical data and new data is added or updated everyday
- If the data is distributed and stored across different servers or systems the querying tasks becomes easier
- Managing and administering the data is time cosuming and difficult
Advantages of partitoning
Data partitoning provides us a number of advantages , some of which are listed below
- Improves query performance
- Easier to manage data
- Allows accessing a large part of a single paritition
- System is highly available and scalable
- Administration tasks are easier
- Maintainance becomes easier
- Flexible index placement
- Smaller index tree or table scan when querying in a single partiton
- Queries can access different paritions parallely.
Disadvantages of partitoning
Data partioning sounds promising however it comes with a set a disadvantages
- Automating changes to a partitoned table can be difficult
- Metadata-only operations can be blocked by DML operations until a schema-modification lock can be obtained.
- Filegroups and files must be managed if the paritions are placed on individual filegroups.
- Multiple DBs or instances cannot be spanned.
- Partitioned tables have bad throughout with ORM related tools.
System Design Example
The diagram below should demonstrate a simple example of how partitions should work.
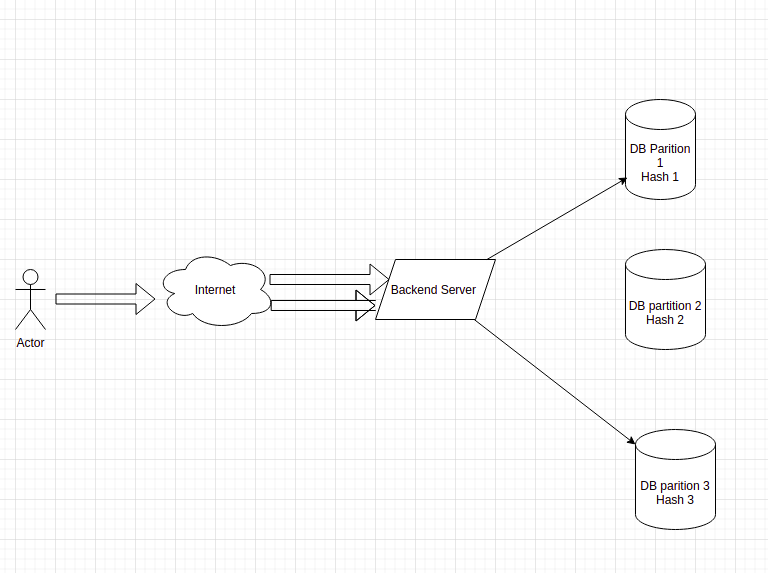
The databases are horizontally paritioned on hash based partitioning technique. DB1 contains rows with resultant hash value as 1 and similarly DB2 of hash value 2 and DB3 of hash value 3.
A user send a request and the request is received by the backend server and saved to the database partitions. As seen above the hash value computed are 1 and 3 (two requests sent) so they are saved to DB1 and DB3.
With this article at OpenGenus, you must have the complete idea of Data Partitioning and how it is applied in real life.