
Reading time: 40 minutes | Coding time: 20 minutes
Face detection is an age old process and is widely used in popular applications like Face ID by Apple, FaceApp, in surveillance cameras in China and many other applications. Today, we have sophisticated machine learning techniques which can perform face detection with near human precision and near real-time performance. What is interesting is that even in 2001, we had algorithms in use for Face detection. Yes, we are going back 2 decades. A time machine learning still was yet to blow up and Face detection's future was uncertain. Viola Jones algorithm is one which was used and which we have forgotten in light of stronger techniques.
Voila Jones Algorithm did the things which became a cool thing after 2 decades
In this post we will look at Face Detection and its widespread applications.
Following that, we will look how face detection can be achieved using Viola-Jones algorithm and how we can detect faces in an image using OpenCV and Python.
What is Face Detection ?
Face detection is a computer technology which is used to identify human faces in digital images. The goal of face detection algorithms is to determine whether there is any face in an image or not. A large number of techniques have been proposed in the field of face detection ranging from Viola-Jones face detector, Region-based Convolutional Network (R-CNN), You Only Look Once (YOLO) and Single Shot Detector (SSD).
Face detection is considered as a particular case of Object Detection. In Object Detection, we are interested to find the locations and sizes of all objects in an image that belongs to a given class. Various objects could be humans, dogs, vehicles etc. Face-detection algorithms focus on the detection of frontal human faces.
Face detection is a complex process since it involves variability among the human faces like pose, expression, position, orientation, skin colour, the presence of glasses or facial hair, lighting conditions etc
Applications of Face Detection
There exists a numerous amounts of applications of face detection, some of which are listed below.
- Facial Recognition
- Marketing
- Emotional Inference
- Criminal identification
- Healthcare
- Photography
Viola-Jones Algorithm
In 2001, two computer vision researchers Paul Viola and Michael Jones proposed a paper titled Rapid Object Detection using a Boosted Cascade of Simple Features. The proposed framework, which is often known as Viola–Jones object detection framework can be trained to detect a variety of objects of different classes. However, it was primarily developed for face detection. This framework was highly accurate and efficient and can be successfully implemented for a real-time face detection application.
The Viola-Jones algorithm consists of 4 main steps which are mainly-
- Selecting Haar-like features
- Creating an Integral image
- Running AdaBoost training
- Creating classifier cascades
In simple words, the whole procedure can be broken down into various steps:
- Train a model to understand what a face is and what a non-face is.
- Once the model is trained, it extracts certain features, and this information is stored in a file.
- Given a new input image, the features from that file are applied to the input image and feature comparision takes place in various stages
- In various stages because the model has to check different positions and scales since an image can contain many faces of various sizes.
- If it passes through each stage of that feature comparison, then a face is detected in the input image.
1. Selecting Haar-like features
Haar-like features are digital image features used in object recognition. All human faces share some similarities, like the eye region, is darker than the bridge of the nose. Similarly, cheeks are also brighter than the eye region. We can use these properties to help us understand if an image contains a human face.
A simpler way to determine which region is lighter or darker, we sum the pixel values of both regions and compare them. The sum of pixel values in the darker region will be smaller than the sum of pixels in the lighter region. This can be achieved using Haar-like features.
After vast amounts of image training data is provided, the classifier proceeds by extracting Haar features from each image. Haar features are a type of convolution kernels which primarily detect whether a suitable feature is present on an image or not. A Haar-like feature is represented by taking a rectangular part of an image and then divide that rectangle into multiple parts. They are depicted as black and white adjacent rectangles. Some examples of Haar features are -
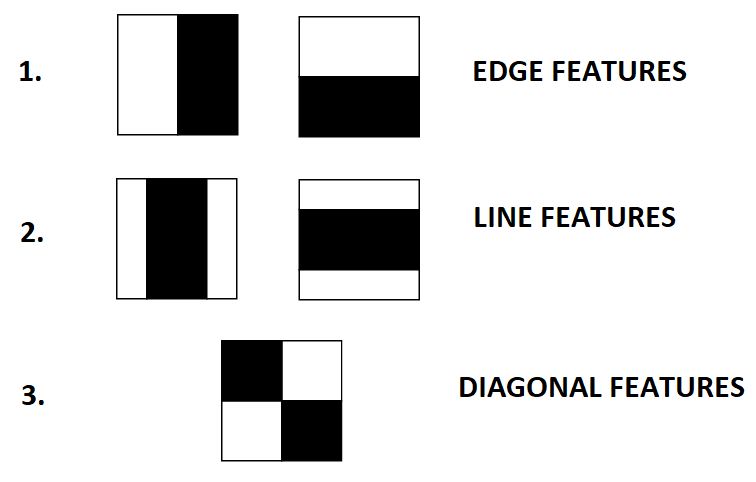
The first one is used for detecting the edges. The second detects the lines while the third is suitable for finding diagonal features. These Haar Features are like windows and are placed upon images to compute a single feature. The feature is essentially a single value obtained by subtracting the sum of the pixels under the white region and that under the black. For a uniform surface(eg-a wall) this value will be close to zero and won't provide any significant information. The process can be easily visualized in the example below.
An effective Haar-like feature should provide a large value which means that area in black and white rectangles will be different. There exist many known features which perform very well to detect human faces.

If we want to extract two features, so for that we'll require only 2 windows. The first feature exploits the fact that eye region is generally darker than the adjacent cheeks and nose region. Now, second feature uses the knowledge that eyes are darker when compared to the bridge of the nose. Now, when feature window moves over the eyes, it will compute a single value which will be compared to some threshold and if it crosses the threshold it will conclude the existence of an edge or a positive feature. Usind a variety of different combinations of these features we can determine whether an image contains a human face or not.
As mentioned, the Viola-Jones algorithm calculates a lot of these features in many subregions of an image which becomes computationally expensive. To tackle this problem, Viola and Jones used concept of Integral Images.
2. Creating an integral image
The framework devised by Viola-Jones uses a base window of size 24X24, which leads to over more than 180,000 features being calculated in this window. It becomes very computationally expensive to calculate the pixel difference for all the features. To avoid such costly computations the concept of an integral image (also known as a summed-area table) was introduced. It uses a quick and efficient way to calculate the sum of pixel values in an image or rectangular part of an image. In the integral image, value at each point is determined by summing all the pixels which are above and the pixels which are to the left and also the target pixel itself. The integral image can be calculated in a single pass over the original image.
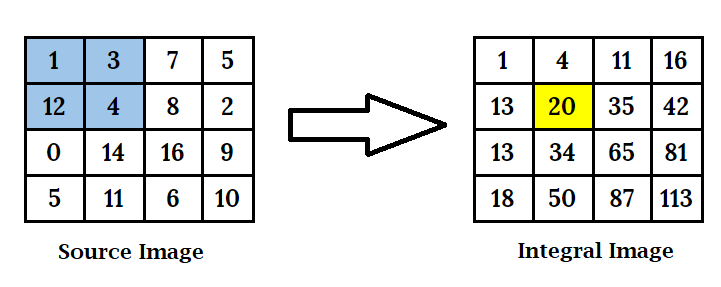
To determine the sum of pixels under any given rectangle, we use the integral image and require only the 4 corner values instead of summing all underlying pixels individually. So, there is a significant reduction in computation as now we only need 3 operations and 4 corner values, regardless of rectangle size.
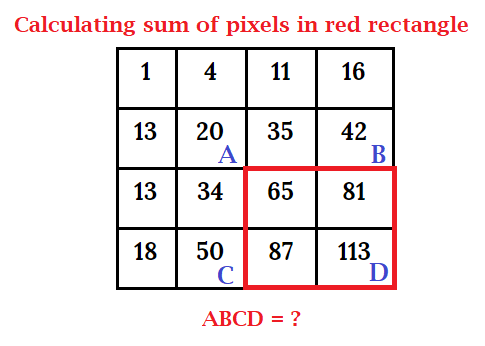
The sum of pixels in the rectangle ABCD can be obtained using values of points A, B, C, and D, and this expression D - B - C + A = 113 - 42 - 50 + 20 = 41
We've added A since when we subtracted B and C, the area defined within A was subtracted twice. Now we've established a simpler way to compute the difference between the sums of pixel values of two rectangles which is perfect for Haar-like features. But how we decide which features to use or not and their appropriate sizes for finding faces in images? This problem is solved by using AdaBoost (Adaptive Boosting).
3. AdaBoost
AdaBoost is a type of ensemble technique (Boosting) in Machine Learning which combines a set of weak learners to form a strong learner. Boosting is a sequential process, wherein each subsequent learner attempts to rectify the errors made by the previous learner in the sequence.
In face detection, the terminology 'weak learner' refers to a model can classify a subregion of an image as a face or not-face only slightly better than a random predictor. In Viola-Jones framework, each Haar-like feature corresponds to a weak learner. To decide the type and the size of a feature that goes into the final classifier, AdaBoost checks the performance of all classifiers which are supplied to it.
To compute the performance of classifier, we evaluate it on all subregions of all the images used for training.
-
Some subregions will produce a strong response in the classifier and will be classified as positives, which means the classifier thinks that it contains a human face.
-
Subregions which do not produce a strong response are assumed to negatives and classifier thinks that they do not contain a human face.
The classifiers whose performance is better are assigned a higher importance or weight. The final classifier obtained is a strong classifier, also called a boosted classifier, which contains the best performing weak classifiers.
This algorithm is called adaptive because, as the training is progressed, it gives more emphasis to those images which were misclassified. The weak classifiers which perform better on these hard examples are assigned a higher weight when compared to others.
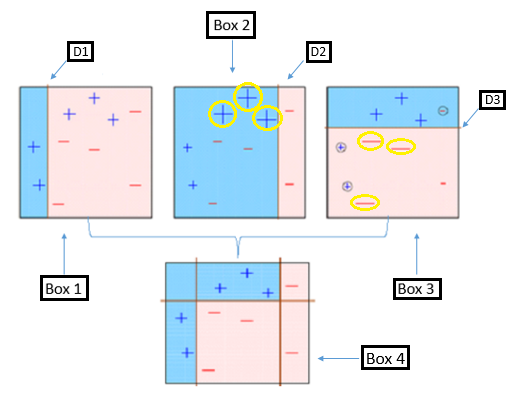
- In Box1, all points are assigned equal weights. A decision stump(parallel to one of the axis) D1 is applied to separate + points from - points.
- In Box2 the points circled in yellow (+) are given higher weights since they were misclassified by D1 and now they correctly classified by D2.
- Similarly in Box3, - points are assigned higher weights since they were misclassified in Box2 by D2.
- Finally, we have Box4 in which all the points are correctly classified. That is why boosting is one of the most powerful ensemble method in Machine Learning.
Since, more than 180,000 features are resulted using a 24X24 window it becomes computationally expensive to use all the features and also not all features are significantly important for identifying a face. To only select the set of best features from all the features, Adaboost is used. It selects only those features that help to improve the classifier accuracy by constructing a strong classifier which is a linear combination of a number of weak classifiers. By using AdaBoost, nearly 6000 features are needed from 180,000 features indicating a significant drop in the amount of features needed to correctly detect a face.
Viola-Jones evaluated thousands of classifiers which specialized in finding faces in images. Since it was computationally expensive to run all these classifiers on every region in every image, so they created and used the Cascading Classifiers.
4. Cascading Classifiers
To reduce the computation cost for every image, Viola-Jones turned their strong classifier (consisting of thousands of weak classifiers) into a cascade where each weak classifier represents one stage. The job of the cascade is to quickly discard non-faces and avoid wasting precious time and computations.
When an image subregion enters the cascade, it's evaluated by the first stage.
If positive response -> possibility of a face -> Output of stage is maybe
If a subregion gets a maybe as output, it is sent to the next stage of the cascade and it is again evaluated. The process is repeated till the image passes through all the stages of the cascade. If all the classifiers approve the image, it is finally classified as a human face.
On the contrary, if the first stage gives a negative response, then the image is immediately discarded since it not contains a human face. Similarly, if it passes the first stage but fails in any later stage, it is instantly discarded. The image can be rejected at any stage of the classifier.
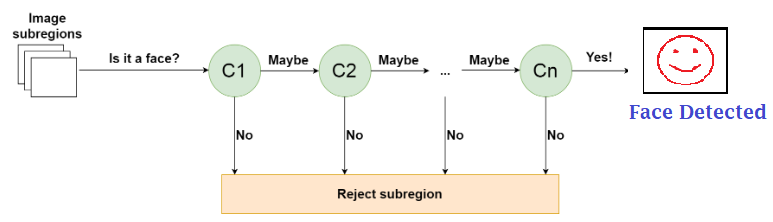
The main idea is that non-faces should be discarded very quickly in order to save time and computations. As every classifier depicts a feature of a human face, a positive detection means that this subregion contains all the features of a human face. However, as soon as even one feature is missing,the entire subregions gets rejected.
To achieve this in an efficient manner, it becomes important to place the best performing classifiers in the starting of the cascade. In the Viola-Jones framework, the eyes and nose bridge classifiers correspond to the examples of best performing weak classifiers.
Implementation in Python
After understanding the Viola-Jones framework, the very first question comes in our mind is that will we have to do all the above process from scratch? The answer is NO, since a pre-trained Viola-Jones classifier comes out-of-the-box with OpenCV. Below, is the code for detecting face/ faces in an image.
import cv2 as cv
# reading the required image
original_image = cv.imread('family.jpg')
# Convert color image to grayscale for Viola-Jones
grayscale_image = cv.cvtColor(original_image, cv.COLOR_BGR2GRAY)
# path to haarcascade_frontalface_alt.xml
# I have placed this xml file in the same directory
face_cascade = cv.CascadeClassifier('haarcascade_frontalface_alt.xml')
detected_faces = face_cascade.detectMultiScale(grayscale_image)
for (column, row, width, height) in detected_faces:
cv.rectangle(original_image,(column, row),(column + width, row + height),(0, 255, 0),2)
cv.imshow('Image', original_image)
cv.waitKey(0)
cv.destroyAllWindows()
Original Image

Detecting Faces in Original Image

Limitations of Viola Jones Algorithm
Although, there are no major downsides of this algorithm that is why it is still very popular for recognizing faces in real-time applications. However as we know, nothing is perfect in this world so some minor limitations of this framework is its inability to detect faces in certain scenarios like-
- If the face of a person is covered with a mask or something else, then Viola-Jones might not work perfectly in that case.
- If the faces are not oriented properly, then there is possibility that this algorithm won't be able to detect those faces.
So, due to these drawbacks it led to the evolution of other algorithms and state of the art approaches like Region-based Convolutional Network (R-CNN), You Only Look Once (YOLO), Single Shot Detector (SSD) and many more!
Conclusion
So, in this post, we looked at what face detection is and its applications in the industry. Then, we went through each of the component of Viola-Jones face detection framework. In the end, we saw the practical implementation of the same using Python and OpenCV.