
Get this book -> Problems on Array: For Interviews and Competitive Programming
Today we cover Generative Adversarial Networks – or GANs for short. GANs are some of the most impressive things that we can do using deep learning (a sub-field of Machine Learning). We shall first see how they work, and then see some interesting and recent applications.
Introductory Machine Learning courses cover basic models that can be used for prediction (like regression), or for clustering and classification. However, GANs are used for generation, a completely different type of problem.
Using these models, if you give them samples from a particular distribution, it learns the underlying structure and then can give you more samples which are also from that distribution. In other words – it can actually generate particular data. This makes them hugely relevant in todays data driven world. GANs have very specific use cases, from applications in medicine, to photo and video generation and editing.
Ian J. Goodfellow and others were the first to describe GANs, in a seminal paper that come out in 2014. It was ground-breaking research from Goodfellow, who was only 27 years old at the time. He has contributed a lot in the field of Deep Learning, and he is the author of what is arguably the best textbook on the subject.
Let’s first appreciate why generative models are kind of tricky and why we only invented them so recently. We will see what makes GANs so unique. Then we will cover some modern applications and changes to the traditional GAN architecture.
A Brief Intro to GANs
Let’s try to create a Generative model based on what we have learnt so far– models that are trained to maximize their fit on a given training dataset.
You give it training samples, and it learns a model that looks like this:
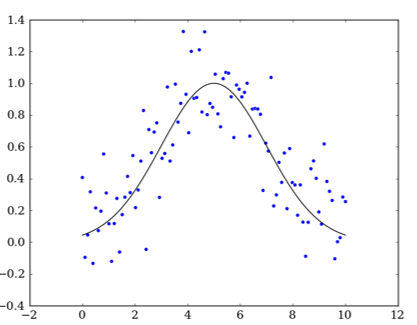
Now you ask the model to make new samples. Since the model is built to find a good fit, in trying to do so it just outputs samples that are on that same line. That is the best place to go to minimize your error – but it doesn’t give us what we want.
Usually, in models such as Neural Networks -
- We train them towards a desired output
- We penalize the network the further away it is from the target
However, in our problem we want to generate realistic, indistinguishable data that looks like it was from the original dataset. In our case, there can be infinite valid outputs and you need a degree of randomness as long as they are still part of the same distribution with the same standard deviation. A normal neural network will average things out and wouldn’t consider all outputs that could be valid. In this situation, there’s not just one right answer.
So, to recap, the problems with generating data are:
- There’s not one right answer
- There can be infinite valid outputs
- We need a degree of randomness
That is generating and the problems we face with it. But what does “adversarial” mean?
Adversarial Training
ML systems can be trained using adversarial techniques. One form of this technique is used in game playing programs – such as DeepBlue or AlphaGo which improve themselves by competing against themselves over and over again and improving their strategies. The focus is to eliminate any weaknesses.
![Game Playing Programs]!(/content/images/2020/06/Annotation-2020-06-09-124745-1.png)
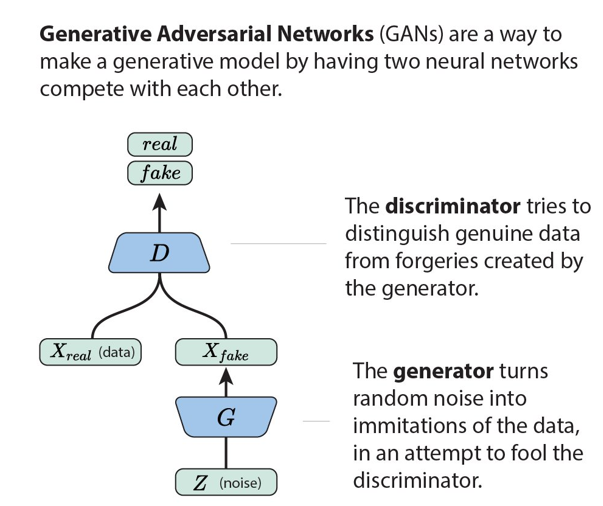
In GANs how this works is - we have 2 networks that are adversaries. The first is the Discriminator, D, which is a straightforward classifier. The second is the Generator, G, and it generates the data. The Discriminator classifies whether a sample is from the dataset or if it was generated by G. G tries to maximize the probability that D is wrong. This is the adversarial part.
Effectively, they are fighting in a game that corresponds to a min/max game. G wants maximize the error rate of the Discriminator, while D wants to minimize it.
For example, if we want to generate pictures of dogs, the Discriminator’s job is to look at an image which could have come from the original dataset or it could have come from the generator and its job is to say “Yes, this is a real image” or “No, this is fake” and output 1 or 0 accordingly.
G gets fed some random noise and it then generates an image from that. This also is where the degree of randomness needed comes from.
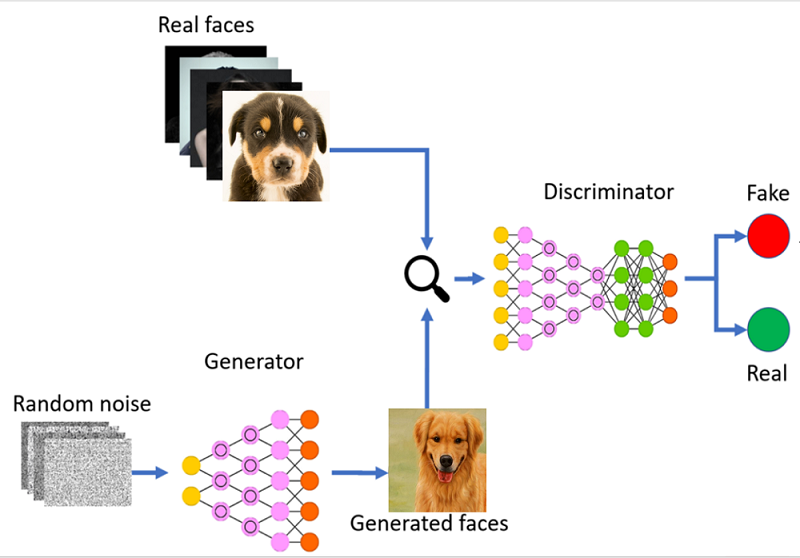
Its reward is negative when the D can tell it is fake, and a positive reward every time it is fooled. It’s like an elegant but weird relationship between enemies that get better with time.
Here is an analogy that is given by Goodfellow himself -
“The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake bank notes and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency. Competition in this game drives both teams to improve their methods until the counterfeits are indistinguishable from the genuine bank notes.”
Applications of GANs
Let’s look at some cool and interesting application of GANs.
Here are two that came out last year in 2019 by NVIDIA AI.
The researchers at NVIDIA AI came up with GauGAN, which creates photorealistic images from segmentation maps.The model is fittingly named after a famous French painter, Paul Gauguin. The tool is like a smart paintbrush, converting segmentation maps into lifelike images. A segmentation map is a 2D representation of the boundaries or segments of an image, that tells the model where to paint the water or the sky or the grass, or any other such environmental features. Using a large dataset of images, the model has learnt how to generate realistic images. So if you draw a lake below a mountain, the model automatically adds a reflection!
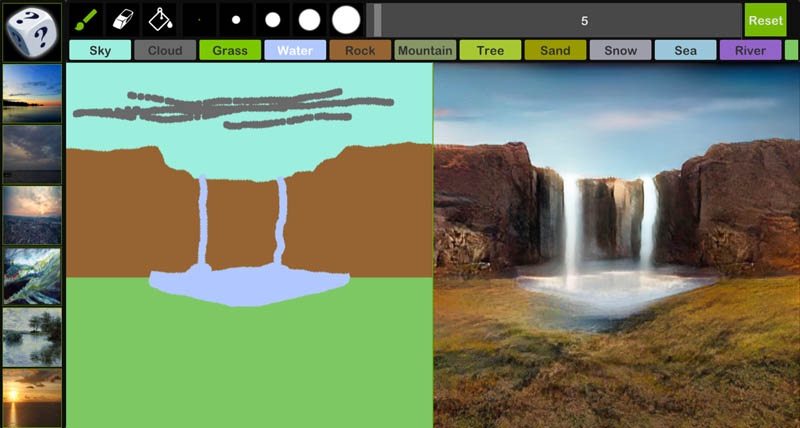
Here is a link to a video that shows a live-demo: GauGAN
NVIDIA researchers also proposed an alternative Generator architecture called StyleGAN that same year. It can be used to create photorealistic images of human faces with a high degree of variation!

Using input images of people to train on, it can even be used to add stochastic features such as freckles or spots, change the hair type, apart from aging and de-aging the facial featues. Just a few tweaks to the Generator and a very interesting development was observed, where there is now a high degree of flexibility and control over the final generated images than before using traditional architectures.
In the field of medicine, it has been used for anomaly detection. For example, a model can be trained with images of healty mammary glands. The discriminator can tell between this dataset of healthy organs with those that have been generated by Z. If it can tell that the image is fake, then there is an anomaly in the image. GANs can also be used to generate new molecular combinations, and thus synthesize and discover new drugs!
Surprisingly, in 2018 researchers applied GANs in the field of steganography, and showed how GANs can be used even in the field of security. Their method tweaks the architecture to use 2 discriminative networks instead of one. Steganography is the practice of concealing a file, message, image, or video within another file, message, image, or video. The discriminators are used to check how foolproof the generated hidden file is.
Finally, we look at CycleGAN, which has been able to transfer entire styles onto images. What does this mean? We take different images - real photos, paintings by Monet, Van Gaugh, etc. and transfer styles like this:

CycleGAN learns the style of his images as a whole and applies it to other types of images. This method uses two generators and a single discriminator. The generators are paired such that ultimately an image is generated that is basically a reconstruction of the original. Then, the discriminator provides the necessary penalties to improve our output. Ultimately, using backpropogation, we can convert images of Monet paintings into Van Gaugh paintings (or between any two styles, really).
Here are some other applications GANs can be used in:
- 3D Object Generation (in the gaming industry)
- High-Resolution Video and Image Generation
- Translation – Image to Image, Text to Image and so on
- Photo and Video Editing – aging and de-aging images, style editing
- Audio (music) Generation - GANSynth
Notice how we have a wide range of fields to use GANs in, but only very specific use cases.
GANs - Reality and Shortcomings
We saw some really cool things we can do with GANs, but to be fair, there are also a few shortcomings. The big disadvantage is that these networks are very hard to train. The function GANs try to optimize is a loss function that essentially has no closed form (unlike traditional squared error functions such as squared error). Optimizing this loss function is very hard and requires a lot of trial-and-error regarding the network structure and training protocol. This is also why very few people have applied GANS on things more complex than images (such as speech). GANs have very limited use cases. Nowadays, people have started using Transformers to do the same things GANs have been doing, especially in the field of Natural Language Processing.
Hopefully, this blog introduced you to GANs and what they really are, showing you what they really can do.
Thanks for reading.