
In this post we will understand one of the most important part of a Neural Network -Hidden Layers. Artificial Neural Network (ANN) is one of the technique in Machine learning. It has input layer, Hidden layer and Output Layer.
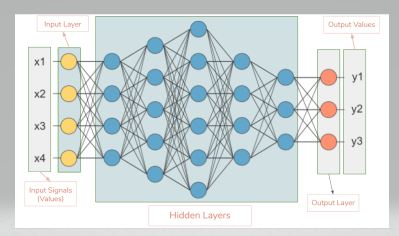
The input layer contains input neurons that send information to the hidden layer. The hidden layer sends data to the output layer. Every neuron has weighted inputs, an activation function, and one output. The input layer takes inputs and passes on its scores to the next hidden layer for further activation and this goes on till the output is reached. Synapses are the adjustable parameters that convert a neural network to a parameterized system.
What is Hidden Layer?
The hidden layer is located between the input layer and output layer. When the hidden layers are increased, it becomes Deep. Deep Learning is extremely useful because it is an unsupervised machine learning approach which means that it does not need labeled data.Hidden layers have neurons(nodes) which apply different transformations to the input data. One hidden layer is a collection of neurons stacked vertically. Each hidden layer’s neuron has a weights array with the same size as the neuron amount from its previous layer. As the number of hidden layers and neurons grows, the required time for the learning process of the ANN and for the evaluation of a new instance grows exponentially.For a really complex and non linear dataset we need several hidden layers.ANN with multiple hidden layers is known as deep neural network.ANN with a single layer is known as shallow network.Not just multiple hidden layers sometimes the type of hidden layer also different.This concept of solving problems with multiple hidden layers is known as deep learning.In our image given above we have 5 hidden layers. In our network, first hidden layer has 4 neurons, 2nd has 5 neurons, 3rd has 6 neurons, 4th has 4 and 5th has 3 neurons. Last hidden layer passes on values to the output layer. All the neurons in a hidden layer are connected to each and every neuron in the next layer, hence we have a fully connected hidden layers.
Difference between Shallow Network(Single Layer) and Deep Neural Network(Multiple hidden layer)
- A single layer might not have the flexibility to capture all the non linear patterns in the data.
- A deep network first learns the primitive features followed by high level features. This helps in building efficient models.
- Lots of experiment have shown that a deep network with less parameters performs better than a shallow network.
- For example deep network with hidden nodes[10,10,10,10] might perform better than shallow network with [80] hidden nodes.
Role of Hidden Layers
The role of the Hidden Layers is to identify features from the input data and use these to correlate between a given input and the correct output.There is a well-known problem of facial recognition, where computer learns to detect human faces. Human face is a complex object, it must have eyes, a nose, a mouth, and to be in a round shape, for computer it means that there are a lot of pixels of different colors that are comprised in different shapes. And in order to decide whether there is a human face on a picture, computer has to detect all those objects.The hidden layers will break down our input image in order to identify features present in the image. The initial layers focus on low-level features such as edges while the later layers progressively get more abstract. At the end of all the layers, we have a fully connected layer with neurons for each of our classification values.
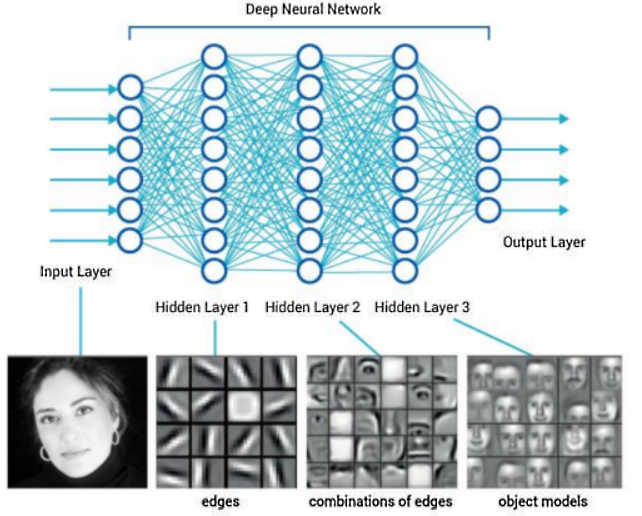
- Layer 1: The computer learns to identify edges and simple shapes.
- Layer 2: The computer learns to identify more complex shapes and objects.
- Layer 3: The computer learns which shapes and objects can be used to define a human face.
How does a Hidden Layer work?
The hidden layers are where the magic happens.The hidden layers perform computations on the weighted inputs and produce net input which is then applied with activation functions to produce the actual output. The computations that the hidden layers perform and the activation functions used depend on the type of neural network used which in turn depends on the application.Hidden layers are layers of mathematical functions each designed to produce an output specific to an intended result. Some forms of hidden layers are known as squashing functions. Squashing functions limit the output to a range between 0 and 1, making these functions useful in the prediction of probabilities. By using a variety of hidden layers, we can extract features from an image and use them to probabilistically guess a classification.
Hidden layers allow for the function of a neural network to be broken down into specific transformations of the data. Each hidden layer function is specialized to produce a defined output. For example, a hidden layer functions that are used to identify human eyes and ears may be used in conjunction by subsequent layers to identify faces in images. While the functions to identify eyes alone are not enough to independently recognize objects, they can function jointly within a neural network.Hidden layers are very common in neural networks, however their use and architecture often varies from case to case. As referenced above, hidden layers can be separated by their functional characteristics.
The Number of Hidden Layers
The number of hidden layers is highly dependent on the problem and the architecture of neural network. There is no concrete rule to choose the right number. We need to choose by trial and error validation.Too few hidden layers might result in imperfect models. The error rate will be high. High number of hidden layers might lead to over-fitting, but it can be identified by using some validation techniques.The final number is based on the number of predictor variables, training data size and the complexity in the target.When we are in doubt, its better to go with many hidden nodes than few. It will ensure higher accuracy. The training process will be slower though.Cross validation and testing error can help us in determining the model with optimal hidden layers.
GoogLeNet
GoogLeNet is a 22‐layer deep CNN is the winner of ILSVRC2014 classification and detection tasks.The basic building block of the GoogLeNet is called an Inception block.The inception block consists of four parallel paths. It design a good local network topology and then stack these modules on top of each other.The Inception module includes several 1 × 1, 3 × 3, and 5 × 5 convolutions, while 1 × 1 convolutions are used to compute reductions before the expensive 3 × 3 and 5 × 5 convolutions.Finally, the outputs along each path are concatenated along the channel dimension and comprise the block’s output. The commonly-tuned parameters of the Inception block are the number of output channels per layer. 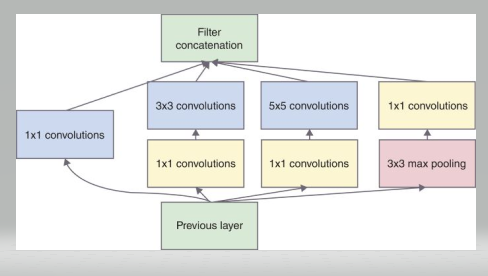 GoogLeNet improved state of-the-art recognition accuracy using a stack of Inception layers.GoogLeNet connects multiple well-designed Inception blocks with other layers in series.The ratio of the number of channels assigned in the Inception block is obtained through a large number of experiments on the ImageNet dataset.GoogLeNet was one of the most efficient models on ImageNet, providing similar test accuracy with lower computational complexity. The difference between the naïve inception layer and final Inception Layer was the addition of 1x1 convolution kernels. These kernels allowed for dimensionality reduction before computationally expensive layers. The GoogLeNet model is computationally complex.GoogLeNet consists of 22 conv-layers in total (the deepest one at that time),and achieves the top-5 errors of 6.7%, which was far greater than any network before it. GoogLeNet had 7M network parameters when AlexNet had 60M and VGG-19 138M. The computations for GoogLeNet also were 1.53G MACs far lower than that of AlexNet .
GoogLeNet improved state of-the-art recognition accuracy using a stack of Inception layers.GoogLeNet connects multiple well-designed Inception blocks with other layers in series.The ratio of the number of channels assigned in the Inception block is obtained through a large number of experiments on the ImageNet dataset.GoogLeNet was one of the most efficient models on ImageNet, providing similar test accuracy with lower computational complexity. The difference between the naïve inception layer and final Inception Layer was the addition of 1x1 convolution kernels. These kernels allowed for dimensionality reduction before computationally expensive layers. The GoogLeNet model is computationally complex.GoogLeNet consists of 22 conv-layers in total (the deepest one at that time),and achieves the top-5 errors of 6.7%, which was far greater than any network before it. GoogLeNet had 7M network parameters when AlexNet had 60M and VGG-19 138M. The computations for GoogLeNet also were 1.53G MACs far lower than that of AlexNet .
With this article at OpenGenus, you must have a complete idea of hidden layers in Machine Learning models. Enjoy.