
In memory Database is a type of Database that is stored in main memory (instead of hard disk) which makes to significantly fast (100X improvement) with some limitations. In this article, we explain everything about in-memory database and present an real system design example where in-memory database is used.
Table of Contents:
- Introduction to Database
- About In Memory DataBases
- Redis (In memory DB)
- Memcached (In memory DB)
- Aerospike (In memory DB)
- HazelCast (In memory DB)
- In memory vs on disk databases
- UseCases of in memory databases
- System Design Example Use Case of in memory Database
Introduction to Database
A Database is a collection of structured data which are generally stored and accessed from systems. There are various types of database that are used by applications, however we are going to focus on in memory databases.
A in memory database primirarily depends on main memory for data storage so all data is stored in memory and so there is no need to perform I/O operations to query or update data which makes in memory databases really fast compared to on disk databases in which data is stored on disk.
Some of the examples of in memory databases are:
- Redis
- Memcached
- Aerospike
About In Memory DataBases
The biggest advantage of in memory databases are that they store data in systems main memory which produces quicker results. As the data is stored in main memory the time required to query anything is faster as there is no need to reach out the hard disk. Data Storage for in memory database relies in the systems random access memory (RAM) instead of the systems disk drives , the data is directly accessible by applications.
Traditional database use disk drives to store data, writing data to the disk is done in a atomic fashion where all the writes are registered.
Data in in memory database are ready to be updated or changed , data in traditonal databases may be encrypted or encoded whereas data in in memory database are in directly usable format.
The structure of in memory databases are independent of disk blocking issues which is advantageous as it allows them to directly navigate from column to column or row to row which allows changes to be implemented by allocating memory blocks and rearranging pointers, hence allowing updating values to be comparatively faster in case of in memory databases.
Just like a on drive database in memory databases allow us to add data , update them or delete them.
Volatile In memory databases support three of the ACID operations that is:
- Atomicity
- Consistency
- Isolation
To add durability, we use file snapshots ,transaction logging or high avalability.
Let us look into detail on some of these in memory databases examples.
Redis (In memory DB)

Redis is one of the most popular in memory database which is a persistent key value based database. It supports multiple forms of datatypes and data structures like list,sets etc.
Redis works by mapping keys to values and supports multiple data models and offers more advanced features compared to other database systems.
Redis works by mapping keys with values and can be used as a primary database or can be used together with other databases like mongodb, mysql etc to improve performance and increase load capacity of a system.
Memcached (In memory DB)
Memcached is an open source distributed memory caching system and is used for speeding up database operations by reducing its load. Everytime a database query comes over memecached helps storing the data objects in dynamic memory.
Similar to redis memcached stores data in key value pairs . It is easy to setup and is highly scalable for use.
Aerospike (In memory DB)
![]()
AeroSpike is a flash optimized in memory open source NoSql database in memory database. Similar to redis it is also a key value operational database and also supports different complex objects. Aerospike however has a better performance than any clustered nosql solutions , aerospike also performs auto-clustering, auto-scaling, auto-rebalancing.
HazelCast (In memory DB)

HazelCast database is also an in memory database based on key value pairs which stores data as a set of unique identifiers. HazelCast is horizontally scalable so we can join hundreds of nodes to form a cluster to combine terabytes of memory to be used. It replicates data across the cluster and provides many ways to tune availabilty and relability.
In memory vs on disk databases
In memory databases are optimized for high performance and use specialized data structures and index structures to ensure data is always in main memory. On disk databases on the other hand stores and retreives data directly from disk drives.
In memory databases are much faster compared to on disk databases as the data is present in the memory itself so it eliminates the time required to access data from the disk.
One of the biggest disadvantage of in memory databases are that if the database reboots or crashes there is no way to recover the data. This is a major concern as the data would not be persistent so a solution for that is to use the charateristics of durability of data of databases like mysql, postgres etc with the in memory databases. This is a common practice that is implemented to use in memory databases along with a on disk database. The advantage of this architecture is that in memory database provides speed whereas in disk database ensures persistence.
UseCases of in memory databases
There are lots of use cases of in memory databases particularly for real time applications which requires high performance technology. Operations which require high velocity, throughput and low latency are a good area of using in memory databases.
Some of the areas where they are being used are
- Processing of streaming data
- Developing embedded systems
- Real time bank applications , advertising , machine learning and billing subscriptions
- Network switches and routers
- E commerce applications
- Social media applications like twitter,instagram etc
System Design Example Use Case of in memory Database
Let us look at a simple example of using in memory database with a on disk database.
Let us consider a very simple social media application where we have just two options for now (right now ignoring authentication, followers and other services) , to view the dashboard and post a image.
Lets say we use on-disk database like mongodb and everytime a user views his dashboard in which the content is retreived from the database and when user posts an image the data is added to database.
Now as users scale the latency or time required for the operation to retreive content from the database will increase which could lead to bad user experience.
To counter this problem that is to scale our application and increase the load level and overall make our application faster we can use an in memory database like redis.
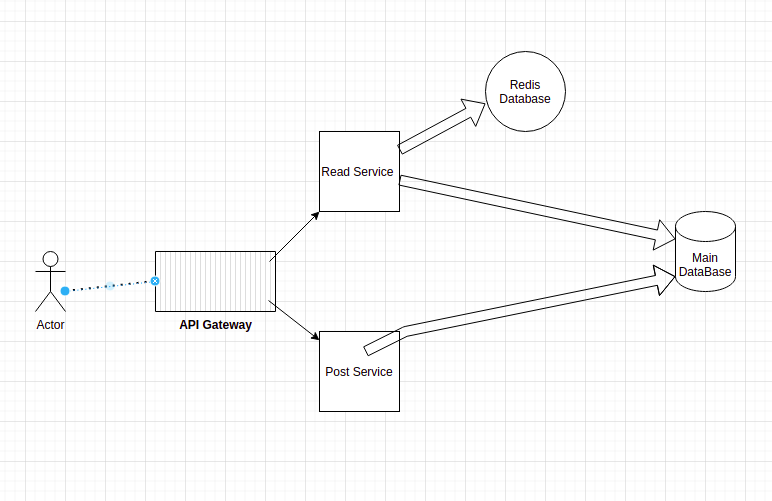
Here there is a user who interacts with our application which has two services one to read data and other to write data , based on the request by a user it is redirected to the required service.
When a user posts his data it directly interacts with mongodb however when a user reads data we first check redis if it is already present there, if it is present we display it to user and the operation is comparetively faster as the data is retreived from memory. If the data is not present in redis we query the main database and display it to user also simulataneously add that data to redis so that we can retreive it faster from redis directly later on.
With this article at OpenGenus, you must have the complete idea of in memory database along with real life system design example.