
Reading time: 25 minutes
In Oct 2018 , Google AI released a pre-trained model for performing various Natural language processing tasks .It instantly started getting attention due to the fact that it attains state of art results on most of the NLP tasks . They even claimed that the model has surpassed human level performance which is generally the benchmark for all the Machine learning Algorithms.
You can find the released paper here in which they talked about the process of training the model , It's architecture , usage etc.
What is BERT?
Bert stands for Bi-directional encoder representations from transformers . I know its lot of high concept terms but they may start getting clear as we progress . Basically for right now ,you can think BERT as a trained model on large unlabeled corpus (which is referred to as unsupervised learning ) which can later be use on a wide range of NLP tasks by applying transfer learning . For understanding bert we have to familiarize ourselves with concepts like Transformers , Self attention .
NLP Task which can be performed by using BERT:
- Sentence Classification or text classification.
- Sentence pair similarity or Semantic Textual similarity.
- Question Answering problem.
- Sentence tagging tasks.
For understanding BERT , first we have to go through a lot of basic concept or some high level concept like transformer , self attention.The basic learning pyramid looks something like this.
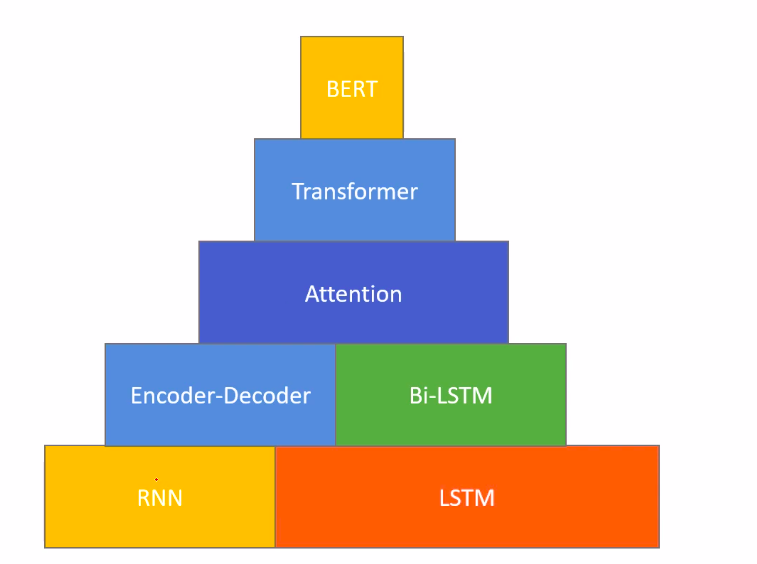
Don’t worry about all these concepts if you are not familiar with them , we will be going slowly through them along with basic terms understanding such tokenization etc. Right now in this article we try to look these things at a high level.
We will deal with it later but let's try to understand the inner workings of BERT at high level.
BERT’s Architecture
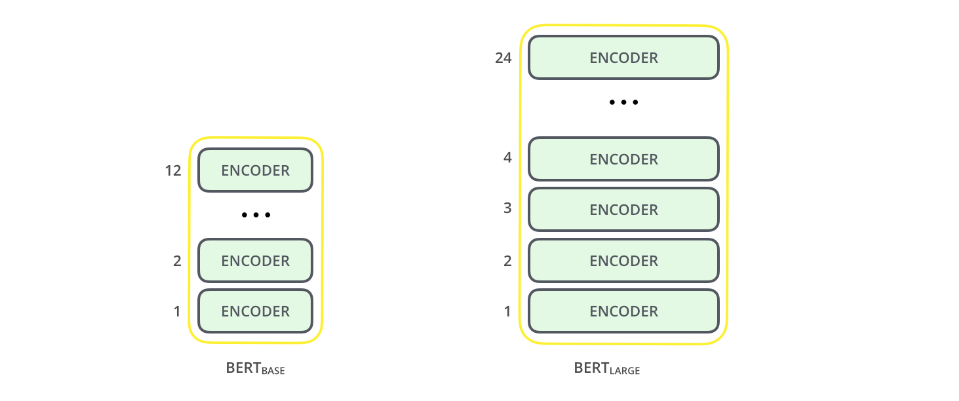
As you can see there a lot of encoder layers stack over each other ,actually in case of BERT base the number of layers are 12 and in BERT large it's 24 . So we are actually feeding the tokenized vector into these layers after getting output. We again feed it to the next layer , this way we are able to get the output .
Bi-directional
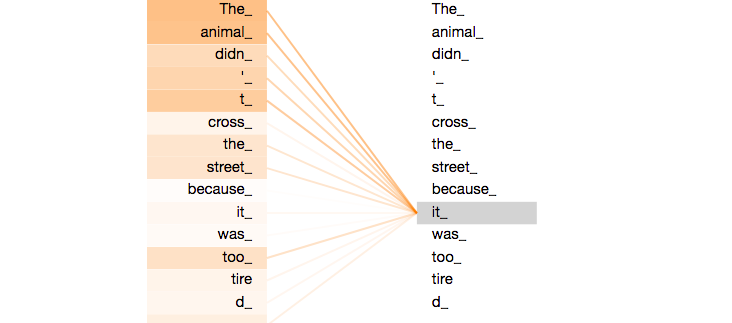
Bert model has the property of capturing the information from both sides from right as well as from left which makes it more susceptible towards errors during guessing the meaning of particular words , It also provides a particular property of autocompleting which you generally see during searching something on google .
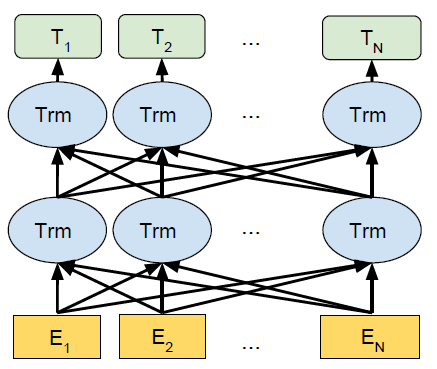
As you can see in above fig that this bidirectional property applied throughout all the layers , After each encoding the its is shared among all the inputs to the next encoders . This type of structure creates synchronization among all the input and the model able interpreters things like semantic information embedded within the sentences . The models that have come before that generally don't discuss the aspect of bi-directionality . Open’s Ai GPT was a well known model before that which only considered the fact of using previous information to predict the current word or future words . Actually this aspect also makes these models stand out on their own because the fact that in this way we were able to predict next words which helps a lot or you can say that basis of Task like Machine translation , generating scripts or sentences which cannot be achieved by BERT .
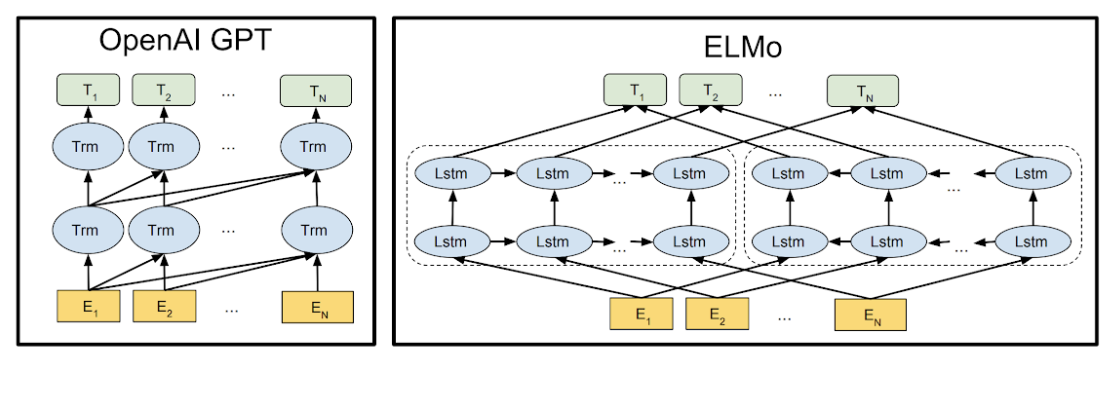
Another model which talks about bi-directionality but not in the same way actually ELMo uses the concatenation of independently trained left-to-right and right-to-left LSTM to generate features for downstream tasks. Among others models , BERT is the only one which representations are jointed from both left and right contextual information from all layers .
Word vector :
You can consider a word vector as a mathematical value representation of some token ( which is some word, n-gram , character , typo) . It values generally in the form of a vector of a given system , which collectively results in word embedding . A bert model have its different word embedding which is obtained by training it.
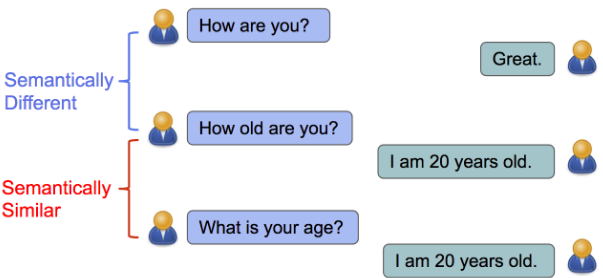
Semantic similarity:
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity.
Attention model:
One of the major problems with RNN’s models is that they are not able to hold the history of the data in simpler words. We can say that they only consider the weight of the previous words. Lets understand by an example:
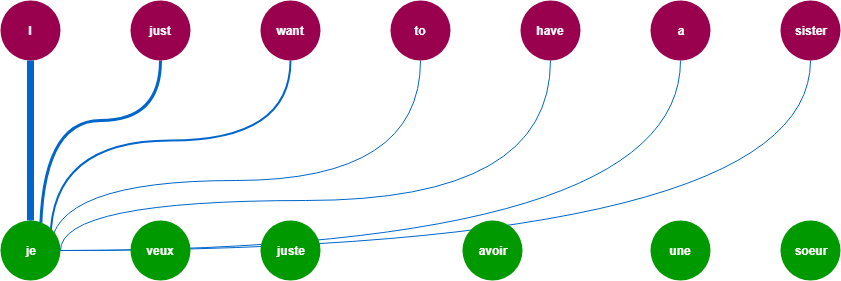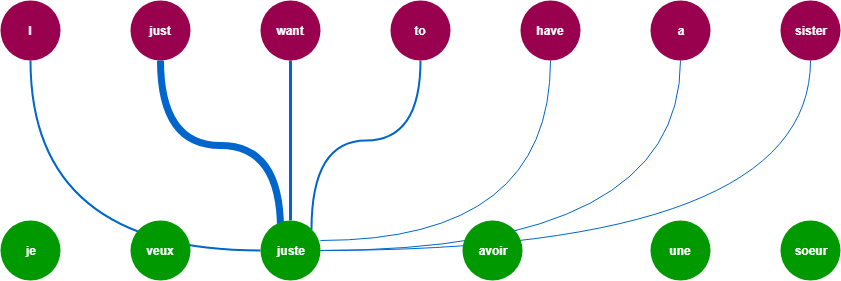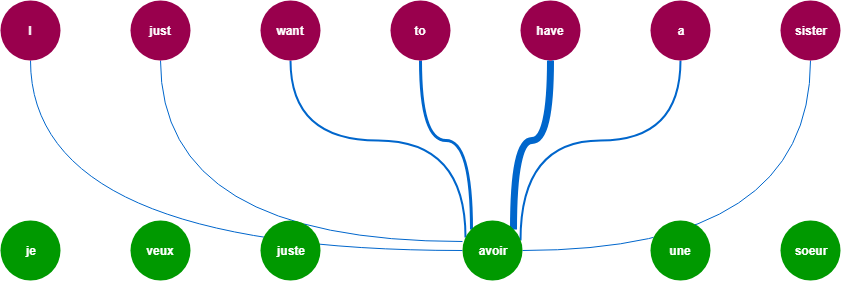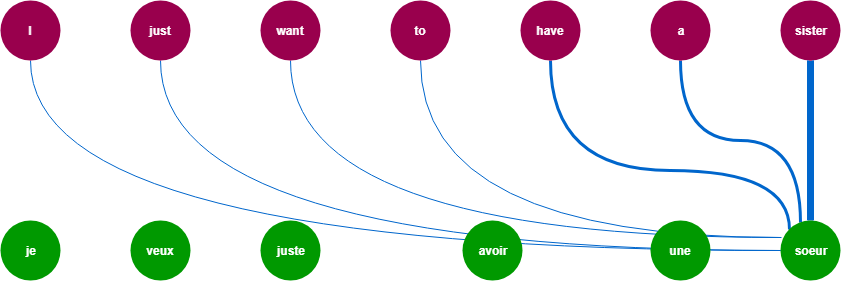
For doing the machine translation the model needs to consider the weights of all the words from both sides left and right .These weight going to be differ a lot but they all are contributing to output .
In the case of BERT we also see some similar model Model which is Know as Multi headed attention but before that let’s proceed with another term which sounds similar to this , self attention which is basically the same thing but used in term contrast rather than in model. Self attention is also known as Intra attention knowing all the vocab is necessary in this field otherwise you instantly get confused.Right now you can simply understand here that this is the basis of **LSTM **(Long short term memory network ) , as you can simply guess bi-Lstm is simply mean bi-directional LSTM . But don’t worry about that we going to discuss it later so you able to fully grasp what it means.
Endnote
As discussed here all about high level interpretation about the BERT model due to the fact there is a need of strong understanding of a lot of basic concepts to fully grasp this topic due to which we are not able to cover topics like Multi headed attention or able to look in the coding side of BERT .By the way, the coding part is not that difficult but the main thing is that you able to understand what's going on inside these things.
Question
Which NLP task can not be performed by using BERT?
With this article at OpenGenus, you must have the complete introductory idea of BERT. Enjoy.