
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article at OpenGenus, we will be looking at the architecture of Kafka and its importance.
Overview of the article,
- Why?
- Event.
- Streaming Platform.
- Kafka.
- Kafka Components.
- Message.
- Topic.
- Partition.
- Cluster.
- ZooKeeper
- Producers.
- Consumers.
- Importance.
- Realtime Usecase.
Why?
Let's start with why?
Here, we have many data sources in our lives, it could range from different devices to stores etc depending on the type of business at hand. Generally, as a business, we take the data to our operational databases and then to our analytical databases. Operational databases contain detailed information on day-to-day activities in an organization. Analytical databases are data warehouses which contain large amounts of historical information which is used for business intelligence(BI) and analytical processing which help in taking management-level decisions.
If we have designed different applications which are our data sources then for communication between the applications we use MOM(Message Oriented Middleware). In this, we pass data across applications. The message is sent and received asynchronously. Some producers and consumers communicate via a channel. They support publish-subscribe and point-point models. In the publish-subscribe model, each subscriber gets zero or one copy. In the case of point-to-point, there are potential receivers who might get zero or one depending on whether the message is intended for them or not.
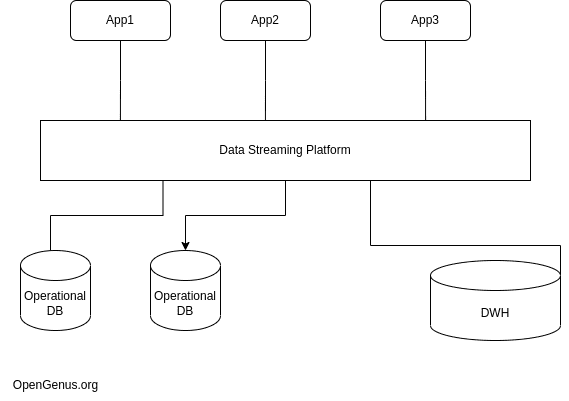
In this evolving world, the architecture is changing but the data flow is the same, to tackle this issue we have streaming platforms. There is a single source of truth to the entire organization. As the organizational size increases traditional methods like ESB, and ETL creates a mess in terms of the connections and may create issues. A streaming platform does it all in a single shot i.e. it is capable of providing publisher-subscriber patterns, storing data temporarily and processing if needed. It’s event-driven. Demand for streaming platforms is increasing due to its various benefits.
Event
An event is any action that may create some change in the way a business operates. Every action that could be recorded is an event.
Streaming Platform
A streaming platform has continuous data flow from different devices and sources.
Kafka
Kafka is an event streaming platform which was created and open-sourced by LinkedIn. It’s capable of handling trillions of events. If there is any need for the storage of messages, Kafka does it.
Kafka also called Apache Kafka is very reliable. Using the confluent Kafka which provides Kafka with additional features we can easily scale and reduce the overall cost of the ownership. We can replicate data on-premises and on the cloud.
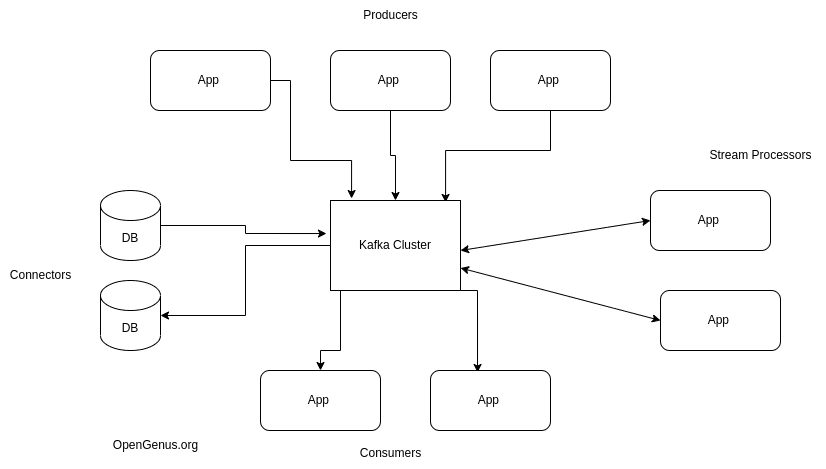
Kafka Components
- Kafka Broker.
- Kafka Client.
- Kafka Connect.
- Kafka Streams.
- KSQL
This picture gives an overall idea of the kafka architecture
Message
This is a primary basic unit of Kafka. Messages may have keys associated with them. The message could be an integer, string, float or JSON and just about anything. They are stored as a byte array.
Topic
Logical category of messages. There can be many topics in a cluster but each one should have a unique name. We can think of it as a relation(table) in the database.
Partition
Every topic is split into streams and these streams are called partitions. Every partition holds a subset of a topic. Order is maintained by partitions, messages with the same keys end up in the same partition. Once data is written into the partition it’s immutable. In a partition, we have an ‘offset’. This offset acts as an identifier within each partition with it starting from 0 as default and incrementing by 1 with every message being received.
Now that you understood the basic terminologies, we’ll dive a little deeper.
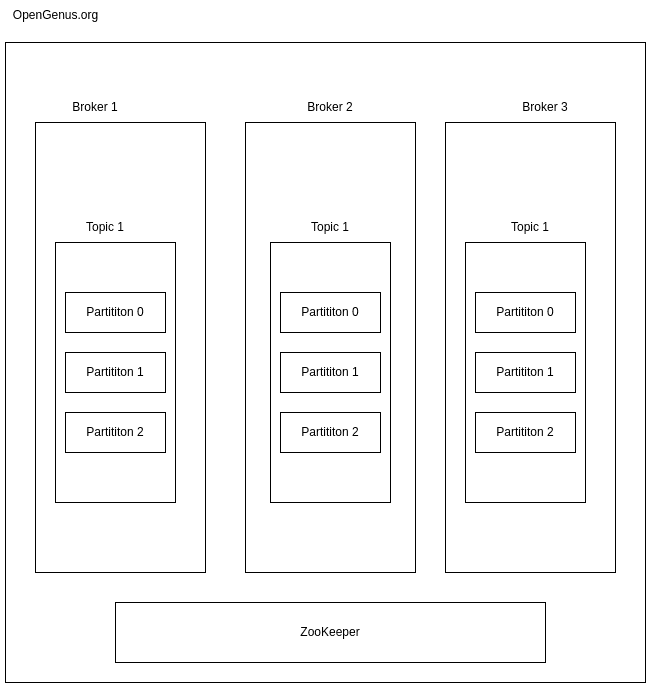
Cluster
Clusters in distributed systems are a collection of computers which are working together to achieve a common goal. A Kafka cluster is a system that has several brokers, topics and partitions. A Kafka sever is also called a broker. A Broker can have one or more topics.
In a cluster, what usually happens is a broker will control and manage replication of topics and partitions inside a cluster. In every topic of a broker we have a leader partition which does active reading and writing of data and the followers passively try to replicate that data. This is so that the cluster is well balanced.
We can connect to a cluster by connecting to a single broker. There is a replication factor which needs to be considered for topics. We cannot exceed the limit of replication factor and it’s dependent on the number of brokers available in the cluster. The replication helps in fault tolerance.
Zookeeper
As the word suggest, it’s the master manager. It has information about the consumers and about the cluster. It’s incharge of managing Kafka brokers, topics and partitions of the cluster. The zookeeper keeps track of the brokers in the clusters and notifies the consumers or producers about the crashed brokers and the state of the cluster. Zookeper also tracks which broker is the partition leader. This information is given to the producers and consumers to read and write easily.
Producers
Several producers inside an application send information or data to the server to store large volume of data. Within the cluster, a producer sends data to a topic. The data is sent to the broker which has a leader partition of the topic.
Zookeeper keeps a meta data of which broker has what topics and which one is the partition leader. This information is critical as producers send data to this parition leader.
Consumers
A consumer is someone who reads the data from the clusters. Typically whenever a producer sends data to a topic’s partition and the offset increases, whenever a consumer tries to read the data we have a choice to start at the default offset index which is 0 or to start at whatever they would like.
There are two types of consumers they are:
- low-level consumers
- high-level consumers
The low-level consumers are the one’s which know from which broker, which topic and which partition leader and the offset to consume from. The high-level consumers are the one’s which are a collection of one or more consumers.
Importance
- Realtime Analytics: Using kafka we can gain realtime data stream and can give business intelligence almost instantly than the old method of data processing which would take lot of time.
- Speed: Due to the brokers, topics and API's we can horizontally scale the resources.
- Highly reliable: Because of the replication across the brokers in the cluster, we are sure that our consumers get access to data irrespective of the state of the cluster.
- Scalable: As and when we need to store and process data we can quickly scale using kafka. Horizontally scaling by adding more brokers or Vertically scaling a single broker with resources.
Realtime Usecase
Consider an inventory management system at any retail coorperation, using kafka we can avoid the cases of low inventory. This can be done by managing various services and establishing consistent data stream which could be used to provide services without delay.
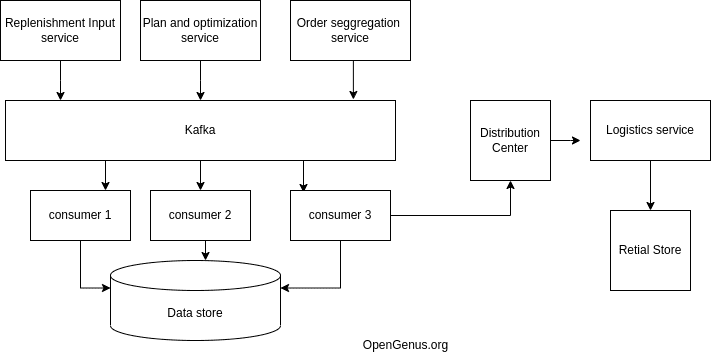
In retail replenishment of items should be done without any discrepancy. To understand, plan and deliver goods big retail cooperations use kafka as their data streaming platform to perform next steps of actions and communicate with other services effectively.
The single source makes sure that every component in the System architecture has good understanding of requirements and fulfill their services as and when needed. This saves them from a lot of trouble of having a case where demand and supply are inversly proportional. Organizations can achieve scale and process data if needed and hire logistic services on demand. The database capacity should also be handled in big retail organisation so that there is no choke from the huge amount of data.