
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Let me give you a rough idea of containerization metaphoricaly. Imagine living in a house with no rooms, utter chaos and no privacy, where everything blends together. Horrible right! Now, picture introducing rooms: suddenly, life feels organized and beautiful!(yes privacy too!) Similarly, containerization brings order to software development, creating isolated environments for applications. This way, chaos transforms into efficiency and clarity, making it easier to manage, deploy, and scale applications.
In a general computing environment, processes share the same set of resources, creating potential conflicts and challenges in resource management. In this scenario, processes share a common namespace, leading to a lack of isolation and independence. Resource conflicts, such as two processes trying to access the same memory address or conflicting file access, can result in unstable and unpredictable behavior.
Containerization is essential in modern software development and deployment due to its benefits: isolation, portability, resource efficiency, scalability, faster deployment, enhanced security, and more. In this article, we will explore the core technologies behind popular containerization software like Docker, Kubernetes, and Podman, as well as notable cloud providers.
How does containerization work?
Containerization uses specific features of the Linux kernel to create isolated environments for running applications. For eg this is what Docker states on their website:-
Docker uses a technology called namespaces to provide the isolated workspace called the container. When you run a container, Docker creates a set of namespaces for that container.
Docker employs Linux namespaces, cgroups, and seccomp Linux features, and this is also true for other well-known container technologies. The core concepts and components involved are namespaces, control groups (cgroups), chroot, and union file systems. In this article, we will focus on Linux namespaces.
Linux Namespaces: What are they?
Linux namespace is a fundamental linux kernel feature that enables the isolation of resources within a system. Currently, Linux implements six different types of namespaces. The purpose of each namespace is to wrap a particular global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource. Here’s what the man pages say about namespaces:
A namespace wraps a global system resource in an abstraction that
makes it appear to the processes within the namespace that they
have their own isolated instance of the global resource. Changes
to the global resource are visible to other processes that are
members of the namespace, but are invisible to other processes.
One use of namespaces is to implement containers.
Linux supports six distinct namespace types. By wrapping a specific global system resource in an abstraction, each namespace aims to provide the impression that the processes running inside it have their own isolated instance of the global resource. Process IDs, file system mount points, network interfaces, IP addresses, routing tables, firewall rules, hostnames, NIS domain names, and so forth are examples of global resources.
Given below is the table from man pages of namespaces showing the types:-

Understanding PID Namespaces
I will delve further into pid namespaces and provide a basic code output in this post to help readers grasp isolation and gain a clear idea of how namespaces function.
According to the manpages:-
PID namespaces isolate the process ID number space, meaning that
processes in different PID namespaces can have the same PID. PID
namespaces allow containers to provide functionality such as
suspending/resuming the set of processes in the container and
migrating the container to a new host while the processes inside
the container maintain the same PIDs.
PIDs in a new PID namespace start at 1, somewhat like a
standalone system, and calls to fork(2), vfork(2), or clone(2)
will produce processes with PIDs that are unique within the
namespace.
To explain this better I have attached a picture:
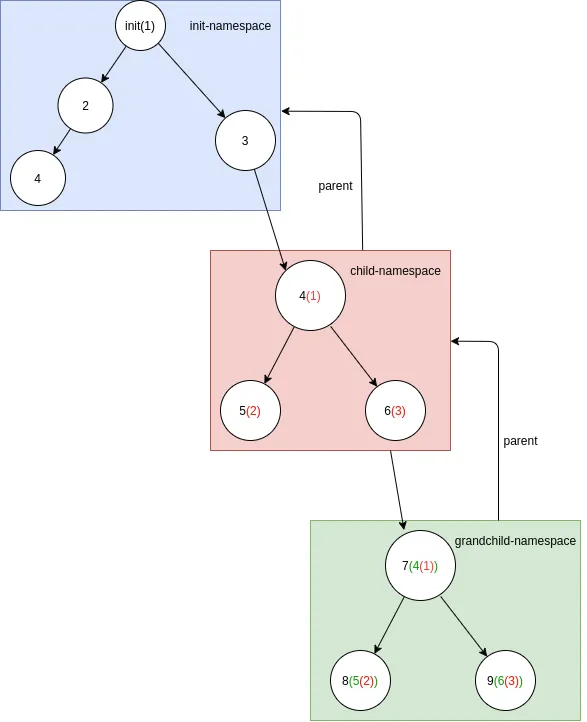
A Process ID (PID) is a unique numerical identifier assigned by the operating system to each running process. It allows the system to distinguish between different processes, hence manage and track processes effectively. Linux establishes a single init pid_namespace by default, and all processes live inside of it. It is possible for processes to generate a new pid_namespace and assign their child processes to it. The new pid_namespace inherits the parent pid_namespace as a child. In a new pid_namespace, the PID number begins with 1.
- Processes are assigned unique numbers in the parent (init) namespace.
- In a child namespace, processes have PID as 1, 2, 3, while the parent sees them as PID 4, 5, 6.
- If a grandchild namespace is created from a process(in fig process ID 1) in the child namespace, processes there will also see their PIDs starting from 1, while the parent namespaces see them as higher-numbered PIDs.
Experiment
To demonstrate the above concept here is the code in C below. This C program illustrates how to create a new PID namespace and run a child process within that namespace. :-
#define _GNU_SOURCE
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <signal.h>
#include <stdio.h>
/* A simple error-handling function: print an error message based
on the value in 'errno' and terminate the calling process */
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); \
} while (0)
static int /* Start function for cloned child */
childFunc(void *arg)
{
printf("childFunc(): PID = %ld\n", (long) getpid());
printf("childFunc(): PPID = %ld\n", (long) getppid());
char *mount_point = arg;
printf("Programme done");
execlp("sleep", "sleep", "600", (char *) NULL);
errExit("execlp"); /* Only reached if execlp() fails */
}
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE]; /* Space for child's stack */
int
main(int argc, char *argv[])
{
pid_t child_pid;
printf("Parent Process: PID = %ld\n", (long) getpid());
printf("Parent Process: PPID = %ld\n", (long) getppid());
child_pid = clone(childFunc,
child_stack + STACK_SIZE, /* Points to start of
downwardly growing stack */
CLONE_NEWPID | SIGCHLD, argv[1]);
if (child_pid == -1)
errExit("clone");
printf("PID returned by clone(): %ld\n", (long) child_pid);
if (waitpid(child_pid, NULL, 0) == -1) /* Wait for child */
errExit("waitpid");
exit(EXIT_SUCCESS);
}
Code explanation
In the above code, the childFunc() is the function executed by the child process created in the new PID namespace. It does following work:-
- It prints the child’s PID and parent PID (PPID).
- It calls execlp to run the sleep command for 600 seconds. This replaces the current process image with the sleep program.
- If execlp fails, it calls errExit.
The parent process prints its own PID and PPID (main function). The clone function is called to create a new child process in a new PID namespace. The clone() system call creates a new process in a new PID namespace, taking following parameters:-
- childFunc: The function to run in the child process.
- child_stack + STACK_SIZE: Specifies the top of the stack pointer for the child (since the stack grows downwards). Stack and its size provided above main() function
- CLONE_NEWPID: flag to ensure the child gets its own PID namespace.
SIGCHLD: Sends a signal to the parent when the child terminates.
If clone() succeeds, it returns the child's PID, which is then printed. The parent process waits for the child to complete using waitpid, ensuring proper cleanup before exiting.
Output
Compiling and running the program in bash gives:-
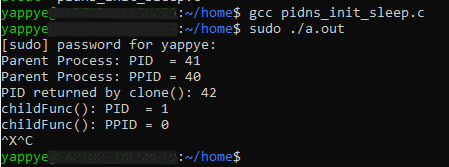
(yappye?? Yeah that's me 😁)
When the program runs, the parent process PID(process ID) ie 41 and PPID(parent process ID) ie 40 is printed initially in main() function. Next, after the child process is created using the clone function, the child process prints its own PID and PPID. From parent's namespace perspective child process ID appears as 42.
However, within the child namespace, the child process sees its PID as 1 and its PPID as 0.
This output demonstrates how PID namespaces provide isolation by allowing the same process to have distinct PIDs based on the namespace from which it is viewed. In the child namespace, the process ID begins at 1, similar to the behavior of a standalone system, yet the parent process sees it as 42 in its own namespace.
Additional Commands Run
- The ps -ef command is a common way to display information about currently running processes in a Linux system.
ps -ef
Output

When we run ps -ef after executing the "pidns_init_sleep.c" program, you will see a list of all running processes, including the parent and child processes created by the program (shown by arrows).
We can observe in the output that the child process with PID 42 and PPID as 41, showing that it was spawned by the main program(./a.out). It runs the "sleep 600" command for 600 seconds.
- The pstree -n command provides a visual representation of the process tree on a Linux system, showing the hierarchical relationship between processes.
pstree -n
Output
The output for above command before running the program.
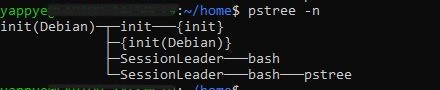
The output for above command after running the program. We can observe the ./a.out program creating process "sleep"(child process).

Conclusion
To summarize, Linux namespaces, particularly PID namespaces, play an important role in containerization by isolating and independent processes. This allows numerous processes to coexist without interference, with the same PID in various namespaces. In this article we have covered only PID namespaces. In iupcomming article we will discover other namespaces too. Stay tuned!✌