
This article explains the conference paper "Show and tell: A neural image caption generator" by Vinyals and others. Here we try to explain its concepts and details in a simplified manner and in a easy to understand way. This paper showcases how it approached state of art results using neural networks and provided a new path for the automatic captioning task.
Task
In a very simplified manner we can transform this task to automatically describe the contents of the image. This may sound simple as per a human task but when it comes for machine to be able to perform this task seems fascinating. It connects the two facets of artificial intelligence i.e computer vision and natural language processing. This paper presents a deep recurrent based neural architecture to perform this task and achieve state-of-art results.
Introduction
- To detect the contents of the image and converting them into meaningful English sentences is a humongous task in itself but would be a great boon for visually impared people. But for that not only the program should be able to capture the contents but also their relation to the environment and it's contents.
Earlier approach attempted to merge the solutions to the subproblems for providing a solution whereas this paper provides and end-to-end single joint solution which aims at maximizing the likelihoood of P(S/I), I = input image,
and S = {S1 ,S2 , S3 ,....} a sequence of words contributing to its description. - Advancements in machine translation (converting a sentence in language S to target language T) forms the main motivation for this paper. Earlier work in this field included translating word by word, reordering, aligning etc but recent studies shows it can be performed effeciently by using a simple Recurrent Neural Networks (RNN).
- Convolutional Neural Networks is used as image encoder for providing a rich vector representation of the image to be fed to RNN which acts as a Decoder. This Encoder-Decoder architecture forms the basis for the task.
- Hence, this paper contributes in the following manner. It provides an end-to-end network trainable using Stochastic Gradient Descent, combining the vision and language sub models producing state-of-art results and finally training them in large corporas and comparing the results to previous ones. On PASCAL dataset it improves the BELU score to 59 (previos best was 25) while human performce shows a score of 69. On FLIKR it improves from 56 to 66, and on SBU, from 19 to 28.
Related Works
Earlier work shows that rule based systems formed the basis of language modelling which were realtively brittle and could only be demonstrated for limited domains like sports, traffic ets.
- Farhadi et al. used to detect scenes in triplets and converted to text using templates. Li et al. used detection of objects followed by combining them in phrases containing those detected elements. But these works were hand-designed and rigid when it comes to text generation.
- Another set of work included ranking descriptions of images (based on co-embedding the image and descriptions in the same vector space). Now for a query image, a set of descriptions are retrieved form the vector space which are in close range to the image. But these failed miserably when it came to describing unseen objects and also didn't attempted at generating captions rather picking from the available ones.
Model
Statistical Machine translation has shown way for achieving state-of-arts results by simply maximizing the probability of correct translation given the input sequence. What actually happens is, a simple RNN network is fed the input sequence which encodes it into a vectorized representation of fixed dimensions and using this representation to decode the fixed dimensional vector to produce the required result. This architecture is adopted in this paper where in the image is given as input instead of input sentence.
Thus, we need to find the probability of the correct caption given only the input image.
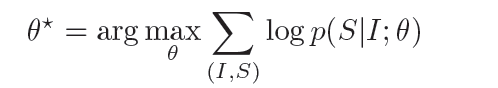
where theta is our model's parameter, I = image, S = correct description.
Since S is our dexcription which can be of any length, we will convert it into joint probability via chain rule over S0 , ..... , Sn (n=length of the sentence).
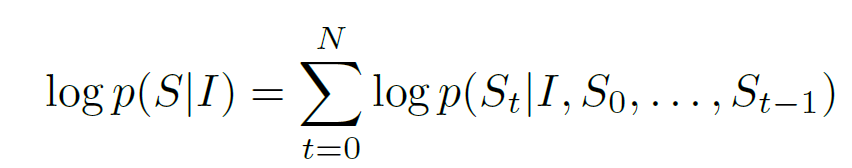
Now instead of considering joint probability of all the previous words till t-1, using RNN, it can be replaced by a fixed length hidden state memory ht. This memory gets updated after seeing a new input xt using some non-linear function(f) :
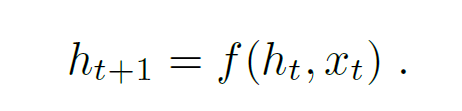
LSTM is used for the function f and CNN is opted as image encoder as both have proven themselves in their respective fields.
LSTM based Sentence Generator
RNN faces the common problem of Vanishing and Exploding gradients, and to handle this LSTM was used. LSTM has achieved great success in sequence generation and translation.
LSTM is basically a memory block c which encodes the knowledge learnt up untill the currrent time step. It's behaviour is controlled by the gate-layers which provides value 1 if needed to keep the entire value at the layer or 0 if needed to forget the value at the layer.
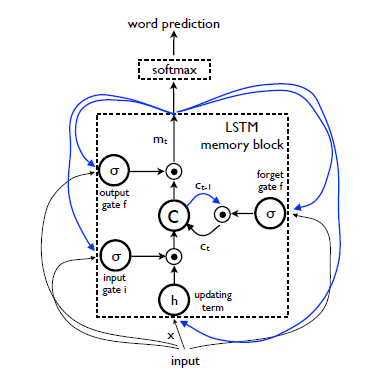
In it's architecture we get to see 3 gates:
- forget gate : whether to forget the current cell value or not
- input gate : whether to read input or not
- output gate : whether to output the new cell value
The output at time t-1 is fed back using all the 3 gates, cell value using forget gate and predicted output of previous layer if fed to output gate.
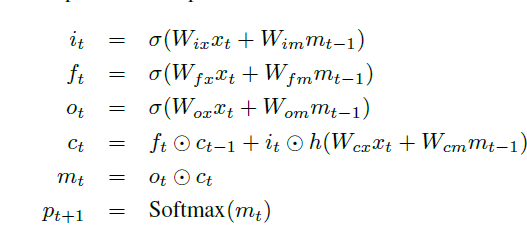
The last equation m(t) is what is used to obtain a probability distribution over all words.
Unrolled LSTM
LSTM predicts output word after word thus it can be modeled as P(S(t)/I ,S0,S1,...,St-1).
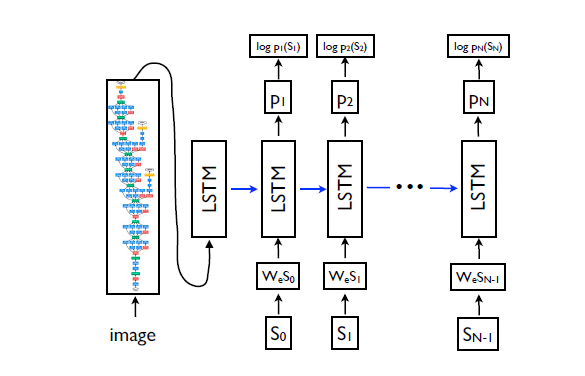
We can infer that it seems as if a copy of a LSTM cell is created for the image as well as for each time step for producing words, each of those cells has shared parameters, and the output at time t-1 is fed back the time step t.
The unrolled LSTM can be observed as
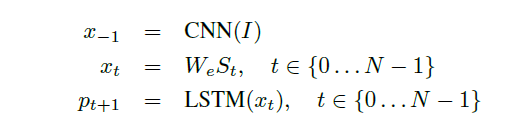
Each word is represented in one-hot format with dimension equal to dictionary size.
S0 and SN are special tokens added at beginning and end of each description to mark the beginning and the end of each sentence. Stop token signals the network to stop further predictions as it marks the end of the sentence.
Now to embed the image and the words into the same vector space CNN (for the image) and word embedding layer is used.
We can have two architectures where we feed the input image at each time step with the previous timestep knowledge or feed the image only at the beginning. The first architecture poses a vulnerability that the model could potentially exploit the noise present in the image if fed at each timestep and might result in overfitting our model yielding inferior results.
Loss
For loss, the sum of the negative likelihood of the correct word at each step is computed and minimized.
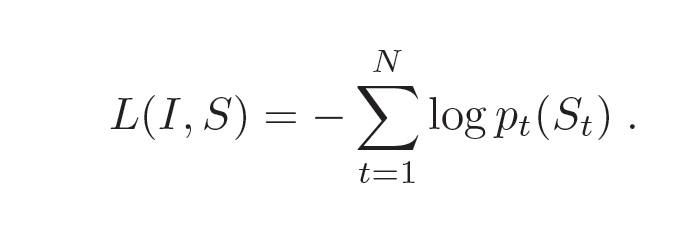
This loss function can now be minimized w.r.t Image, all parameters of LSTM, and word embeddings W(e).
Inference
The various approaches for generating the captions are as follows:
- Sampling : Here we just obtain the best output given the embeddings of the previous layer and go on obtaining till we obtain the end token or reach max length (best first approach).
- Beam Search : This is breadth first search approach where we keep track of k best sentences upto time step t as candidate for generating sentence at time t+1 and again keeping top k sentences.
Beam Search better approximated for the task and hence was appointed for all the further experiments with a beam size of 20. Beam size = 1 yielded pretty bad results.
Experiments
Many experiments were performed on different datasets, using diiferent model architectures, using several metrics in order to compare results.
Evaluation Metrics
- The most reliable but also the most time taking metric for evaluation was to make raters rate each image manually. Each image was rated by 2 workers on the scale of 1-4. Aggrement level was observed to be 65%, and in case of disaggrements the scores were averaged out. Bootstrapping was performed for variance analysis.
- Rest of the metrics can be computed automatically (assuming they have access to ground-truth i.e human generated captions in this case). BELU score was the metric representing this domain. In this method, precision of sentences upto n-grams is calculated between generated sentence and the ground-truth. n=1 meant each word in generated sentence was compared with each word of the ground-truth sentence and precision was calculated as per the number of hits(matches).
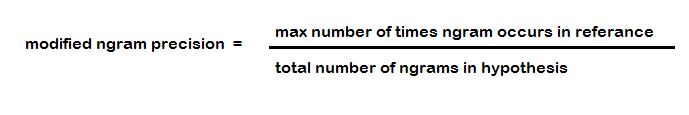
Hence BELU-1 calculates precision at unigram level whereas BELU-n is the average of precision over 1 to n grams. Even with its obvious drawbacks it manages to correlate with the human evaluation.
Datasets
A number of datasets are available having an image and its corresponding description writte in English language.
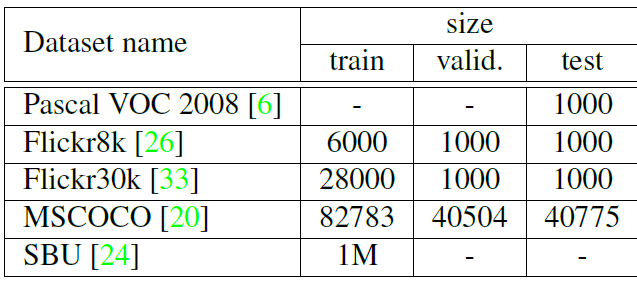
Each dataset has been labelled by 5 different individuals and thus has 5 captions except SBU which is a collection of images uploaded by owners and descriptions were given by them, so it might not be unbiased and related to image and hence contains more noise.
PASCAL dataset is only provided for testing purpose after the model is trained on other dataset.
Training Details
The most dominant problem faced was related to overfitting of the model. Since this task is purely supervised, just like all other supervised learning tasks huge datasets were required. But the quality datasets that were available had less than 100000 images (except SBU which was noisy). Data driven approaches recently gained lots of attention (thanks to IMAGE_NET dataset having almost 10 times more images than what is used for this paper). Still our NIC approach managed to produce quite good results and these are only expected to improve in the upcoming years with the training set sizes.
Several methods for dealing with the overfitting were explored and experimented upon.
- The very first and important technique adopted was initializing the weights of the CNN model to a pretrained model (ex on IMAGENET). It helped a lot in terms of generalization and thus was used in all further experiments.
- Another scope for initializing the weights were for the embedding layer W(e). Attempt was made to initialize it's weight from a large news corpus but no significant gain was observed. So the layer was left randomly initialized.
- Model level overfitting avoiding techniques were also appointed. Dropouts along with ensemble learning were adopted which gained BELU points.
Stochastic gradient was used for the training the uninitialized weights with fixed learning weight and no momentum. Only CNN had fixed weights as varying them produced negative effect. Embedding size and size of LSTM memory had size of 512 units.
Basic tokenization was appointed for descriptions preprocesing and keeping all the words in the dictionary that appeared at least 5 times in training set.
Generation Results
Previous state of art results for PASCAL and SOB didn't used image features based on deep learning, hence a big improvement was observed in these datasets. PASCAL didn't had its own training set so model trained on MSCOCO dataset was used for evaluating over the PASCAL test set.
Human scores were also computed by comparing against the other 4 descriptions available for all 5 descriptions and the BELU score was averaged out. As per the sgnificant improvements in the field of machine translation, it showed that BELU-4 scores was more meaningful to report.
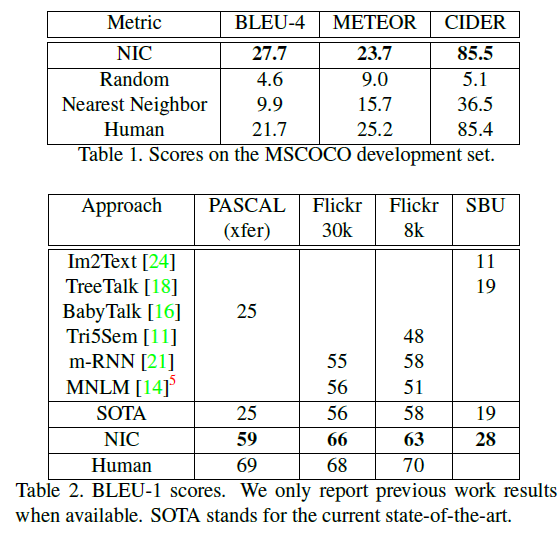
Results shows that the model competed fairly with human descriptions but when evaluated using human raters results were not as promising. This suggests that more work needs to be done towards a better evaluation metric.
Transfer Learning, Data Size and Label Quality
Many models were trained on several datasets which led to the question whether a model trained over one dataset can be transferred to a different dataset and how the mismatch could be handled via increasing the dataset or improving the quality.
The very first case if observed between Flikr8k and Flikr30k dataset as they were similarly labelled and had considerable size difference. We witnessed a improvement of 4 BELU points over switching from 8k to 30k. But when compared for MSCOCO data set, even though size increased by over 5 times because of different process of collection, led to large difference in the vocab and thus larger mismatches. BELU points degraded by over 10 points. However, the descriptions were still not out of context.
On SBU, even though it had a very large dataset but it's weak labelling made task with this dataset much harder because of the noise in it. MSCOCO model on SBU observed BELU point degradation from 28 to 16.
Generation Diversity Discussion
As reported earlier, our model used BEAM search for implementing the end-to-end model. Below figure shows our model returning K best-list form the BEAM search instead of the best result.

The bold descriptions are the one ones which were not present in the training example. We can observe that the different descriptions showcase different acpects of the same image. Thus our model showcases diversity in its descriptions. Around 80% of the times the best caption was present in the training set. But if we observe the top 15 samples, 50% of these were not present in the training set and showcased differnet aspects with similar BELU scores. Hence, it can be concluded that our model has healthy diversity and enough quality.
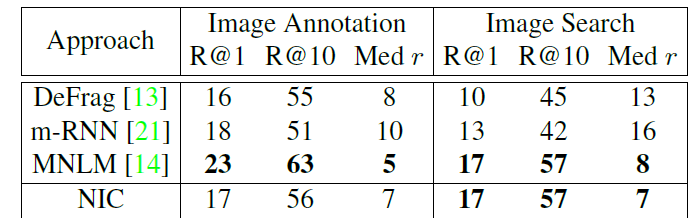
Ranking Results
Even though we can infer that this is not the best of the metric and also a unsatisfactory metric for evaluating a model's performance, earlier papers reported results via this metric. Surprisingly NIC held it's ground in both of the testing meaures (ranking descriptions given image and ranking image given descriptions). Below table shows results over Flikr30k dataset.
Human Evaluation
We had earlier dicussed that NIC performed better than the reference system but significantly worse than the ground truth (as expected). This concludes the need of a better metric for evaluation as BELU fails at capturing the difference between NIC and the human raters.
Examples of rated descriptions

Analysis of Embeddings
Word embeddings were used in the LSTM network for converting the words to reduced dimensional space giving us independence from the dictionary size which can be very large. In our model the word embedding layer is trained with the model itself.
Having objects like "horse", "pony" , "donkey" close to each other in the vectorized space after passing through the word embeddings encourages the CNN model to extract more details and features distinguishing the similar objects. Also in extreme cases, the closeness of objects like "unicorn"(having less examples) to more common similar object like "horse" would provide more details about the "unicorn" too and thus these derived features would ultimately help the model which would have been lost while using the traditional bag-of-words models.
CONCLUSION
With this we have developed an end-to-end NIC model that can generate a description provided an image in plain English. This model was based on a CNN encoding the image into compact space followed by RNN to produce a description. Model was based on a simple statistical phenomena where it tried to maximize the liklihood of generating the sentence given an input image. Experiments on several datasets shows our model performed well both quantitatively (BELU score , ranking approaches) and qualitatively (diversity in sentences and related to the context). We also infered that the performance of approaches like NIC increases with the size of the dataset.
References
- SHOW and TELL: A neural image generatoy by VINYALS
- Text generation using LSTM
- BELU SCORING
- Machine Learning topics at OPENGENUS.
Hope you enjoyed reading this paper analysis at OPENGENUS
THANK You