
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
This article serves as an introduction to data science life cycle and gives an overview on the various phases.
Table of contents
- Introduction
- Data science life cycle
- Discovery
- Understanding data
- Data preparation
- Data analysis
- Model planning
- Model building and deployment
- Communication of results
Introduction
Data science deals with huge amounts of data - extracting useful and meaningful insights from structured or unstructured data using different scientific methods and algorithms to find solution to a real-world problem. From start to finish, it involves a number of steps and is a lengthy procedure. Hence, it becomes important to have a generic structured way in which each step is executed in an orderly manner.
The different phases in data science life cycle are: discovery, understanding data, data preparation, data analysis, model planning, model building and deployment, communication of results. These steps allows us to solve the problem at hand in a systematic way which in turn reduces complications and difficulties in arriving at the solution.
Data science life cycle
The data science life cycle consists of the following phases:
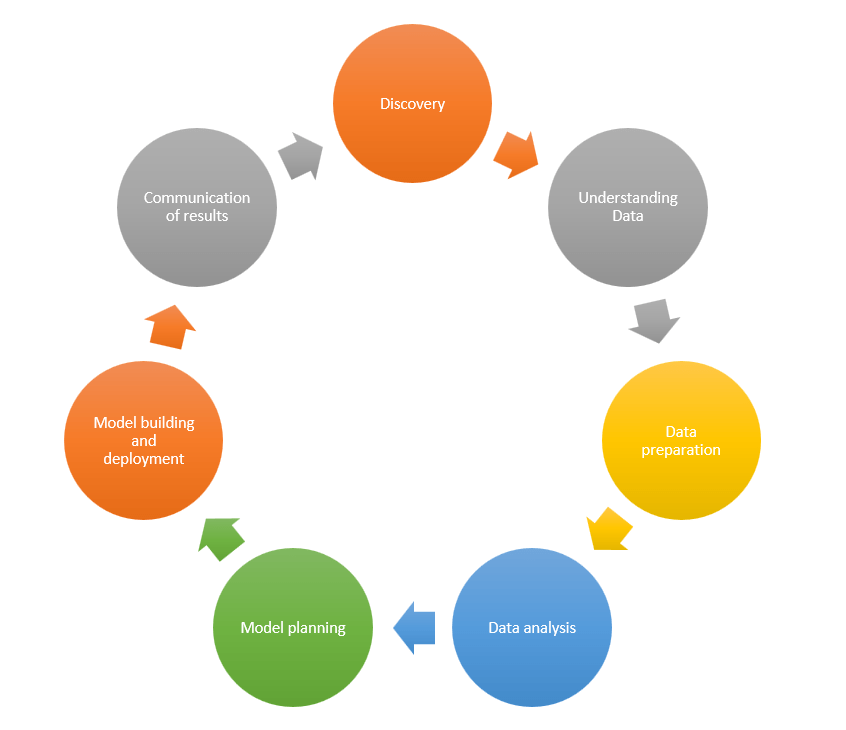
The different phases in Data Science are:
- Discovery
- Understanding data
- Data preparation
- Data analysis
- Model planning
- Model building and deployment
- Communication of results
Let us now see what is done in each phase.
Discovery
The first phase is discovery. This is where we define and understand the problem. This involves asking the right questions and determining all the required factors such as technology required, number of people, data, budget and also decide on estimated deadlines. This is the most essential phase as the whole data science life cycle revolves around solving the business problem. So it is necessary that the business problem is defined on the first hypothesis level before proceeding further.
Understanding data
After defining the business problem, the next step is understanding the data. This includes a wide array of data that can be accessed. Enterprises usually store their data in data warehouses. We need to closely work with our peers to understand what information is stored and what is the required information to be used. This step involves describing what data is needed, how relevant are they and finally extracting the required data.
Data preparation
Next step is data preparation. Here we filter out the data applicable for the problem, merge different datasets, clean the data - eliminating inaccurate data, treating missing values and outliers. This phase is also known as data munging. Here, we also convert the data into desired format, eliminate columns that are not needed and derive new elements from the data acquired. This is arguably the most time consuming step but is also essential as our model will only be as accurate as our data. After this step, we can easily use data for the further phases.
Data analysis
This is the part where exploratory data analysis is done. Here, we analyze our data, look at possible relations between various features and get an understanding of how much effect each variable has over our final prediction or target. We make use of graphs like bar graphs to visualize the distribution of data, pie charts to describe the parts of a whole and scatter plots to visualize relationship between two or more variables. In this step, we get an idea of what features to consider for building our machine learning model.
Model planning
In this phase, we decide on our machine learning model based on the business problem. We select the suitable model - classification, clustering or regression. Once the model family is decided, we carefully choose one algorithm to implement amongst the wide range of algorithms present in each model family. Often this step is done while performing data analysis.
Model building and deployment
In this phase, we create our machine learning model. We split the dataset into train and test data. We fit the train data values in the chosen algorithm and allow the machine to learn. We tune the hyperparameters of the models, adjust weights to improve the results. We additionally need to make sure that there is no generalization error and that the model performs well with other similar datasets too. The model is evaluated by feeding unseen data into it. If we are not happy with the results, we need to go back and make changes to our model until preferred metrics are achieved.
After going through rigorous tests, the model is finally deployed in the preferred environment.
Communication of results
In this phase, we reflect back to our original goal that we set in the first phase. We check if we reached our goal and the extent to which the results have been obtained. We communicate our findings to the stakeholders. This is where presentation plays a key role. Data visualization is used to convey the information in an easy way so that others could also understand the story the data told us and understand the performance of the proposed solution. This helps them in making informed decisions. This is the final step in the data science life cycle.