
There are several techniques which can be used to fool any Machine Learning model without having any information regarding the model like model architecture or training dataset. We have explored an influential research regarding this topic.
In this article, we will be exploring a paper named “Practical Black box attacks against Machine Learning” by Nicolas Papernot, Patric McDaniel, Ian Goodfellow, Somesh Jha, Z. Berkay Celik and Ananthram Swami.
For adversarial examples to work, prior knowledge of either model internals or its training data. But this paper shows demonstration of an attacker controlling a remotely hosted deep neural network (DNN) with no such knowledge. The strategy involves training a local model to replace the target DNN using inputs synthetically generated by an adversary and labeled by the target DNN. The assumptions involved are that (1) the adversary has no information about the structure or parameters of DNN, and (2) no access to any large training dataset. The adversary can only observe labels assigned by the DNN for selected inputs.
Black-Box Attack Strategy
The main aim is to learn a substitute for the target model using a synthetic dataset generated by the adversary and labeled by observing target model output. After that the adversarial examples are generated and the expectations are that the target DNN misclassify them. The strategy involves the following two important steps:
- Substitute Model Training: the attacker queries the oracle with the synthetic inputs selected by a Jacobian-based heuristic to build a model F approximating the oracle models O’s decision boundaries.
- Adversarial Sample Crafting: the attacker uses substitute network F to craft adversarial samples, which are then misclassified by the oracle O due to transfer-ability of adversarial examples.
{I} Substitute Model Training
Training a model F approximating Oracle O is a difficult task because there is no prior knowledge of the architecture of the model and also limiting number of queries made to oracle such that the approach is tractable.
To tackle these challenges synthetic data generation technique is involved called the Jacobian-based Dataset Augmentation.
Substitute Architecture: The adversary can involve architecture that is basically adapted to input-output relations. That means some knowledge regarding inputs like images, texts etc. and output i.e. classification is known.
Generating synthetic dataset: For synthetic data generation, a heuristic in involved which helps in efficiently exploring the input domain. The heuristic is based on identifying directions in which the model’s output is varying, around the initial set of training points. Such directions intuitively require more input-output pairs to capture the output variations of target DNN O. The heuristic prioritizes these samples in order to get the approximation of the DNN i.e. the substitute. Jacobian matrix of substitute DNN helps in identifying these directions. This is evaluated at several input points x. The adversary evaluates the sign of the Jacobian matrix dimension corresponding to the label assigned to the input x by the oracle:
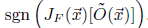 .
.
For getting new synthetic training point a term 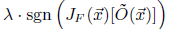
is added to the original point x.
This technique is called Jacobian-based Dataset Augmentation.
Substitute DNN Training Algorithm: The algorithm used is:

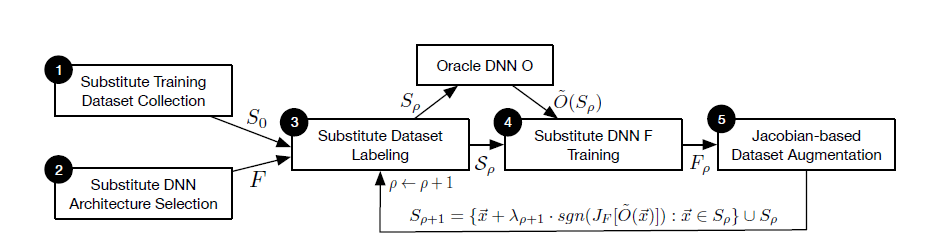
Five steps are involved in the substitute DNN training algorithm. The first step in the Initial collection where the adversary collects set of data representing the input domain. The next step is the Architecture selection step where the adversary selects an architecture to be trained as the substitute F. Then substitute training is done. The third step is Labeling where the adversary labels the substitute training set. The fourth step is Training in which the adversary trains the substitute DNN using substitute training set in conjunction with classical training technique. Final step is Augmentation in which the adversary applies augmentation technique on the initial substitute training set to produce larger substitute training set.
The following diagram shows the training of the substitute DNN:
{2} Adversarial Sample Crafting
Once the adversary trained a substitute DNN, it uses it to craft adversarial samples.
Two approaches are shown in the paper. These are Goodfellow algorithm and Papernot algorithm.
Goodfellow algorithm: It is also known fast gradient sign method. Given a model F with cost function 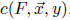 , the adversary crafts an adversarial sample
, the adversary crafts an adversarial sample 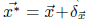 for a given legitimate sample by computing the following perturbation:
for a given legitimate sample by computing the following perturbation:
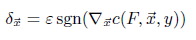
Papernot algorithm: This algorithm is suitable for source-target misclassification attacks where adversaries seek to take samples from any legitimate source class to ant chosen target. For a model F, perturbation is added to a subset of the input component for crafting adversarial sample. To choose input components forming perturbations, components are sorted by decreasing adversarial saliency value. The adversarial saliency value is defined as follows:
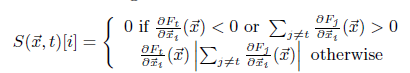
Where Jf is model’s Jacobian matrix.
Both of these algorithms evaluate model’s sensitivity to input modifications in order to select a small perturbation achieving misclassification goal.
Validation of the attack
In the paper, the validation of the attack was done against remote and local classifiers. For each classifier details refer the paper mentioned in the beginning. The following observations were made:
- For target DNN remotely provided by MetaMind, 84.24% adversarial examples crafted were misclassified with a perturbation not affecting human recognition.
- A second oracle trained locally with the German Traffic Signs Recognition Benchmark (GTSRB) can be forced to misclassify more than 64.24% of altered inputs without affecting human recognition.
Attack Algorithm Calibration
Now observing that adversary can force DNN to misclassify, two important questions arises.
(1) How can substitute training be fine-tuned to improve adversarial sample transferability?
(2) For each adversarial sample crafting strategies, which parameters optimize transferability?
The following observations were made:
- It was observed that choice of DNN architecture i.e. number of layers, size etc. have a limited impact on adversarial sample transferability. Increasing the number of epochs, after the substitute DNN has reached an asymptotic accuracy, does not improve adversarial sample transferability.
- At comparable input perturbation magnitude, the Goodfellow and Papernot algorithms have similar transferability rates.
For the practical details and analysis of above questions, please refer the paper.
Generalization of the attack
All substitutes and oracles are considered learned with the DNNs so far. But part of the attack limits its applicability to other Machine learning techniques. It is possible and proved that the attack was generalized to non-differentiable target oracles like the Decision trees. The limitation was just placed on the substitute. It must model a differentiable function that allows for synthetic data to be generated with the Jacobian matrix.
It was observed that the substitutes can also be learned with logistic regression. The attack generalizes to additional ML models by learning substitutes of 4 classifiers (logistic regression, SVM, decision tree, nearest neighbor) in addition to DNNs, and targeting remote models hosted by Amazon web services and Google cloud Prediction with success rates of 96.19% and 88.94% after 800 queries to train the substitutes.
Defense Strategies
When it comes to defending against the attacks, there are two types of strategies. One, reactive where on seeks to detect adversarial examples and two, proactive where one makes the model itself more robust.
What is gradient masking?
It is a technique in which a model is constructed in such a way that it does not have useful gradients, e.g. by using nearest neighbor classifier instead if DNN. This type of method makes it difficult to form adversarial examples because of the absence of gradient.
The paper shows that the black-box attack based on transfer learning from substitute model overcomes gradient masking defenses.
Conclusion
In the nutshell, the paper presented a novel substitute algorithm using synthetic data generation to craft the adversarial examples. The assumption was that the adversary was only capable of observing labels assigned by the model to inputs of its choice. The attack was validated on remote and local DNNs and force them to misclassify. Extensive calibration and generalization of the algorithm was performed. The attack evades a category of defenses, which is called gradient masking. Finally, the paper provided an intuition for adversarial sample transferability across DNNs.
With this article at OpenGenus, you must have a complete idea of this influential paper "Practical Black box Attacks against Machine Learning". Enjoy.