
Reading time: 30 minutes
After the celebrated victory of AlexNet at the ILSVRC2012 classification contest, deep Residual Network was arguably the most groundbreaking work in the computer vision/deep learning community in the last few years. ResNet makes it possible to train up to hundreds or even thousands of layers and still achieves compelling performance.Thanks to this technique they were able to train a network with 152 layers while still having lower complexity than VGGNet. It achieves a top-5 error rate of 3.57% which beats human-level performance on this dataset.
What is the need for Residual Learning?
Deep convolutional neural networks have led to a series of breakthroughs for image classification. Many other visual recognition tasks have also greatly benefited from very deep models. So, over the years there is a trend to go more deeper, to solve more complex tasks and to also increase /improve the classification/recognition accuracy. But, as we go deeper; the training of neural network becomes difficult and also the accuracy starts saturating and then degrades also. Residual Learning tries to solve both these problems.
Fundamental concept of ResNet:
In general, in a deep convolutional neural network, several layers are stacked and are trained to the task at hand. The network learns several low/mid/high level features at the end of its layers. In residual learning, instead of trying to learn some features, we try to learn some residual. Residual can be simply understood as subtraction of feature learned from input of that layer. ResNet does this using shortcut connections (directly connecting input of nth layer to some (n+x)th layer. It has proved that training this form of networks is easier than training simple deep convolutional neural networks and also the problem of degrading accuracy is resolved.
Brief discussion on Identity mappings in Deep Residual Networks
Residual Network Equation:
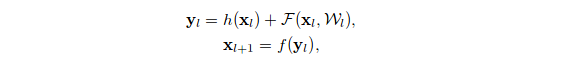
F is a stacked non-linear layer and f is a Relu activation function.
They found that when both f(y1) and h(x1) are identity mappings, the signal could be directly propagated from one unit to any other units, in both forward and backward direction. Also, both achieve minimum error rate when they are identity mappings.
ResNet Architecture specifcations:
As per what we have seen so far, increasing the depth should increase the accuracy of the network, as long as over-fitting is taken care of. But the problem with increased depth is that the signal required to change the weights, which arises from the end of the network by comparing ground-truth and prediction becomes very small at the earlier layers, because of increased depth. It essentially means that earlier layers are almost negligible learned. This is called vanishing gradient. The second problem with training the deeper networks is, performing the optimization on huge parameter space and therefore naively adding the layers leading to higher training error. Residual networks allow training of such deep networks by constructing the network through modules called residual models as shown in the figure. This is called degradation problem. The intuition around why it works can be seen as follows:
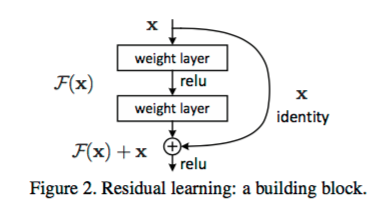
Imagine a network, A which produces x amount of training error. Construct a network B by adding few layers on top of A and put parameter values in those layers in such a way that they do nothing to the outputs from A. Let’s call the additional layer as C. This would mean the same x amount of training error for the new network. So while training network B, the training error should not be above the training error of A. And since it DOES happen, the only reason is that learning the identity mapping(doing nothing to inputs and just copying as it is) with the added layers-C is not a trivial problem, which the solver does not achieve. To solve this, the module shown above creates a direct path between the input and output to the module implying an identity mapping and the added layer-C just need to learn the features on top of already available input. Since C is learning only the residual, the whole module is called residual module.
Also, similar to GoogLeNet, it uses a global average pooling followed by the classification layer. Through the changes mentioned, ResNets were learned with network depth of as large as 152. It achieves better accuracy than VGGNet and GoogLeNet while being computationally more efficient than VGGNet. ResNet-152 achieves 95.51 top-5 accuracies.
The architecture is similar to the VGGNet consisting mostly of 3X3 filters. From the VGGNet, shortcut connection as described above is inserted to form a residual network. This can be seen in the figure which shows a small snippet of earlier layer synthesis from VGG-19.
The plain 34 layer network had higher validation error than the 18 layers plain network. This is where we realize the degradation problem. And the same 34 layer network when converted into the residual network has much lesser training error than the 18 layer residual network.
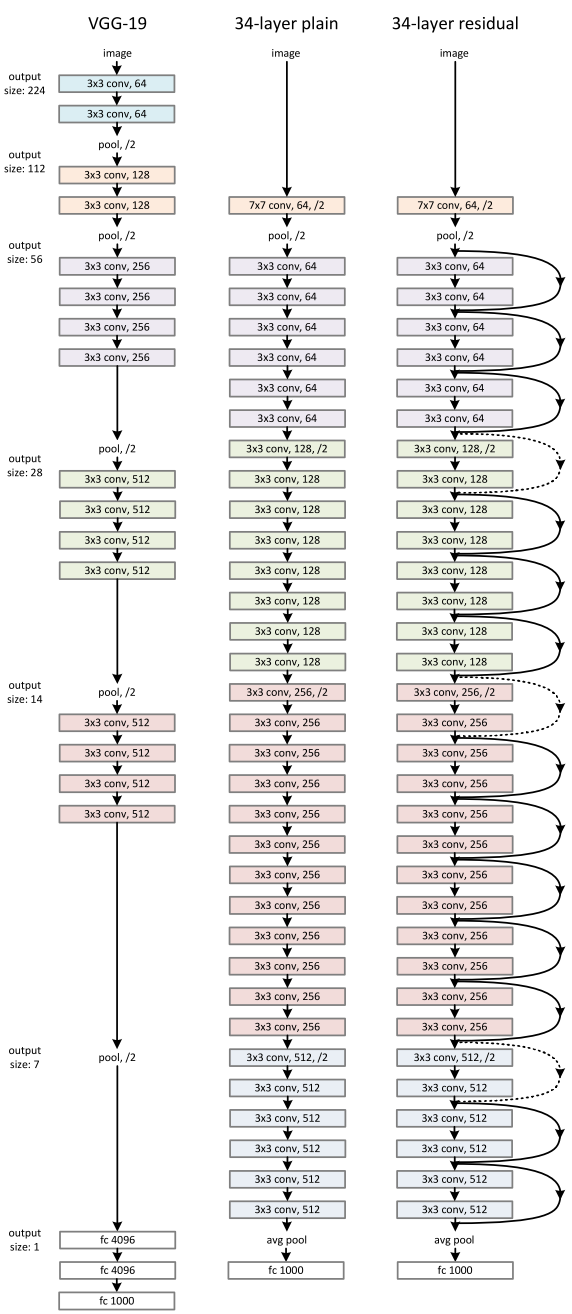
Difference between different models:
The difference is tabulated below:
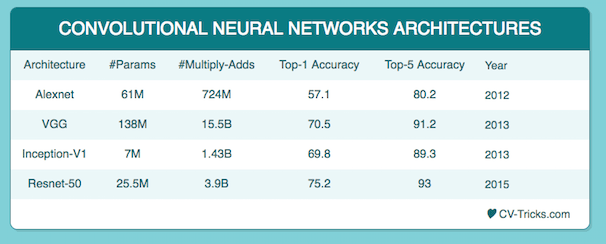
ResNet-50:
ResNet-50 is a convolutional neural network that is trained on more than a million images from the ImageNet database. The network is 50 layers deep and can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals. As a result, the network has learned rich feature representations for a wide range of images. The network has an image input size of 224-by-224.
There are other variants like ResNet18, ResNet101 and ResNet152 also.
If you want to see the ResNet-50 architecture in detail, this is the best page. I use this page very often,here is the link:
http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006