
Run Length encoding (RLE) is a lossless data compression algorithm, supported by many bitmap file formats, like BMP, TIFF and PCX.
Run Length encoding follows a straightforward logic, it just picks the next unique character and appends the character and it’s count of subsequent occurrences in the encoded string. Runs here refer to the consecutive occurences of the same character. The idea is to reduce the physical total size of repeating characters in the data.

Variants of RLE
- Sequencial RLE: The data is processed line by line from left to right direction. This technique is usually used in compression of images. In some other variations, data can also be scanned vertically, diagonally or in blocks.
- Lossy RLE: Some of the bits are discarded during the process of compression (usually by converting one or two significant bits of each pixel to 0). This results in greater compression without changing the appearance of the image to a great extent.

Efficiency
- For the string “WWWWWWWWWWWWWBBWWBBBBBBBBBBB” , the code is “W13B2W3B11” . The Length reduces from 29 bytes characters to 10 bytes.
- This algorithm can prove highly useful for files with a high number of runs and large string lengths. For example a black and white image, as there are large amount of pixels with the same colour value.
- The algorithm is also very quick and easy to implement.
- Since the data is scanned line by line, the whole data is not required at once. Hence, can easily be used for very large sizes of data.
Limitations
RLE will prove to be ineffective for the following cases:
- ABCD gets converted to 1A1B1C1D, which takes more space than before. Hence the compression ratio of the algorithm depends on the data.
- 6666666666655 gets converted to 11625 which can be decompressed to 1-"1",62-"5", and hence is ambiguous for strings with numerical characters.
- Since the algorithm can even double the size of the input, it can't be imlemented in place.
Understanding the Algorithm
Let's take the input string as "wwwwbbbwwwwwbbbbb". At each step we identify the next character, count it's subsequent occurences and append the character followed by it's number of occurances to the code.
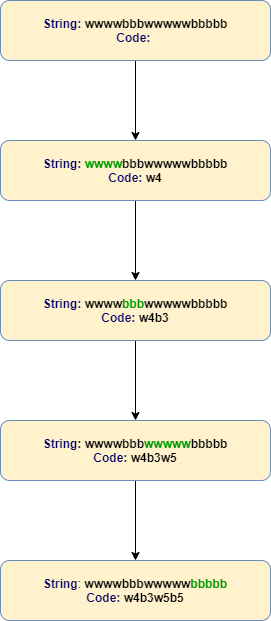
Psuedo Code
- Start with an empty string for the code, and start traversing the string.
- Pick the first character and append it to the code.
- Now count the number of subsequent occurances of the currently chosen character and append it to the code.
- When you encounter a different character, repeat the above steps.
- In a similar manner, traverse the entire string and generate the code.
Encoding Implementation
# Part of OpenGenus IQ
def RunLengthEncoding(s):
code=""
i=0
while i<len(s):
w=s[i]
count=0
while i<len(s) and s[i]==w:
i+=1
count+=1
code=code+w+str(count)
return code
Decoding
Even decoding the output is quite straightforward. Whenever you encounter a number, add the character preceeding it that many number of times in your final string.
For example, A3D5G7 gets decoded to AAADDDDDGGGGGGG.
Complexity
Time Complexity: O(n)
Space Complexity: In the wort case, the algorithm will double the size of the input. Hence space complexity is O(n).
Applications
- Run Length Encoding has been used in the transmission of Analog Television Signals.
- It is supported by many bitmap file formats, like BMP, TIFF and PCX.
Question
Encode the string using RLE
"Bookkeeper of Mississippi is happy"
RLE is which type of compression
With this article at OpenGenus, you must have the complete idea of Run Length Encoding. Enjoy.