
In this article, we will learn and explore about the topic of System Design of distributed cache. Distributed Cache is the core sub-system to make any system scalable.
Table of content -
- Introduction
- Functional Requirements
- Non-Functional Requirements
- LRU cache algorithm explanation
- LRU cache algorithm implementation
- Stepping into the distributed world
- Cache Client
- Maintaining a list of cache servers
Introduction
Caching is a technique of storing most frequent data used in application in small and fast memory which makes our data retrieval process fast and increase the efficiency of our application.
Web Applications Work and backed by data stores in form of databases .when a client makes a call to web application it then makes a call to data stores and client gets the desired results.So in this process there are some drawbacks first calls to databases may take a long time to find and retrieve data and use a lot more system resources and second if data stores are down due to some technical fault our site will not work at all. So to overcome these drawbacks we should store some of the most used data in cache memoey through which retrieval of requird data is faster also first our application will search for data in cache and if it doesn't find in it then calls the data stores for data and if data stores fail our application will work fine for quiet a small time.
- Distributed cache
Since we are dealing with huge amounts of data it is impossible to store this magnitude of data in a single machine so we need to split the data and store it across several machines.
Functional Requirements
put(key, value) -
This function will store object or data in cache under unique key.
get(key) -
retrieve the data or object from cache by matching key value .
Non-Functional Requirements
Scalable-
scalability means our system cache must be able to handle and scales out according to increasing number of data and requests. high scalability assures us that our cache can handle large no. of puts and gets request according to the requirement .It also means we can store large no. of data in our cache for faster access.
Highly Available -
It means that our system must be Resistant to network and hardware failures.It assures us that in case of hardware failures or network partitions our data stored in cache is safe and available for use. So that we will minimize cache miss and reduce the number of calls to databases.
Highly Performant -
It is solely related to the cache access time i.e our cache must be fast as it is called for every request.
LRU cache algorithm explanation -
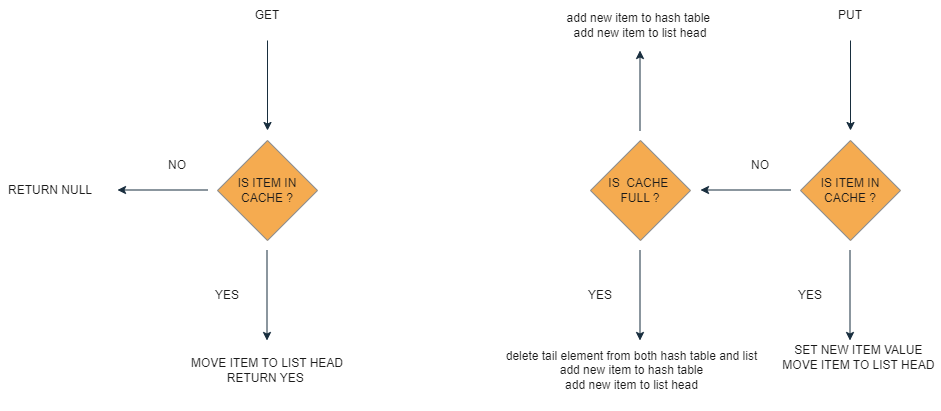
GET -
when this operation is called we check if item is in cache (hash table) if item is not found in cache we return null if it is found we first move item to head of list and then return it to caller . It is so because by moving item to head of list we preserve its order as it is most recently used and item at tail is least recently used so when we have to add new item to list we remove item from tail.
Put -
When this operation is called we check if item is in cache (hash table) if it is found we first move item to head of list and then return it to caller. If we did not found item in cache we check the size of cache if it is not full we just add this item to hash table and add it to head of list whereas if cache is full we remove the element which is at the tale of the list from hash table and list and then we add a new element in hash table and in list head.
LRU cache algorithm implementation -
#include<bits/stdc++.h>
using namespace std;
class LRUCache {
public:
unordered_map<int, list<pair<int, int>>::iterator> Map;
list<pair<int, int>> cache;
int capacity;
LRUCache(int capacity) {
this->capacity = capacity;
cache.clear();
}
bool isKeyExist(int key) {
return Map.count(key) > 0;
}
int get(int key) {
if (!isKeyExist(key)) return -1;
int oldValue = (*Map[key]).second;
put(key, oldValue);
return oldValue;
}
void removeExistingKey(int key) {
cache.erase(Map[key]);
Map.erase(key);
}
void put(int key, int value) {
if (isKeyExist(key)) {
removeExistingKey(key);
}
cache.push_front({key, value});
Map[key] = cache.begin();
if (capacity < (int)cache.size()) {
int lruKey = cache.back().first;
Map.erase(lruKey);
cache.pop_back();
}
return ;
}
};
int main()
{
LRUCache* lRUCache = new LRUCache(3);
lRUCache->put(1, 1);
lRUCache->put(2, 2);
cout<<lRUCache->get(1)<<" ";
lRUCache->put(3, 3);
cout<<lRUCache->get(2)<<" ";
lRUCache->put(4, 4);
lRUCache->put(5, 11);
lRUCache->put(7, 14);
lRUCache->put(8, 42);
cout<<lRUCache->get(1)<<" ";
cout<<lRUCache->get(3)<<" ";
cout<<lRUCache->get(4)<<" ";
cout<<lRUCache->get(7)<<" ";
cout<<lRUCache->get(5)<<" ";
cout<<lRUCache->get(8)<<" ";
return 0;
}
Output -
1 2 -1 -1 -1 14 11 42
-
Here we have defined class LRUcache where we created hashmap and store key value pair for storing data in cache. we also create list for new pairs of key and values.
-
When get method is called we check if value related to key exist in our cache and if we find we update its position to head in the list.
-
When put is called we check if item is already present or not if it is already present we simply just update its position and move it to head. if it is not present we check if cache is full if yes we remove least recently used item and add this itme in both hash table and list.-
Stepping into the distributed world -
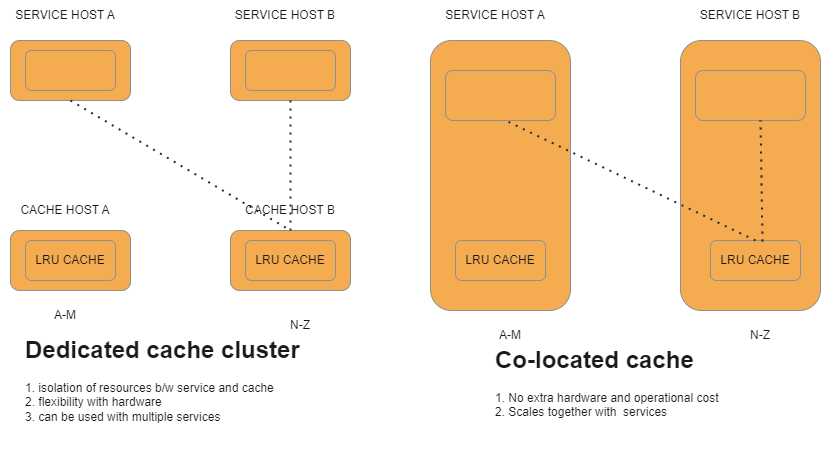
Different ways of making distributed caches
-
We can begin with a simple idea of implementing Least recently used cache to its own host when we move it from service host by doing so we can make each host to store only a little amount of data known as shard.since data is splitted across several host we can now store much more data. Service host keep track of all shards and forward put and get request to a particular shard.
-
second approach is to use service host for cache .here also data is splitted into shrads and we treat or run cache on service host as a separate process and similar to first approach Service host keep track of all shards and forward put and get request to a particular shard.
-
In Dedicated cluster cache and service do not share same memory or CPU i.e cache and service resources are isolated from each other and can be scale up on their own.Dedicated clusters give us flexibility in choosing hardware moreover they can be used by multiple services.here we can choose hardware which can provide us much more memory and high network bandwidth.
-
Whereas in Co-located cache we do not need a separate cluster resulting in saving hardware cost.In Co-location both service and cache hosts scale out at same time so we need to add more hosts to service cluster when needed.
Cache Client -
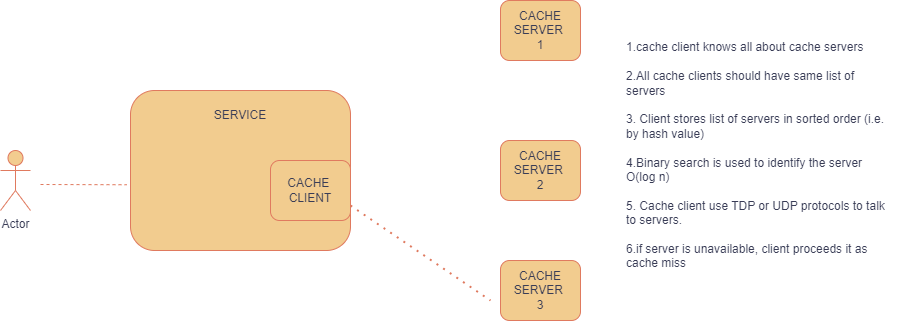
-
In consistent hashing we need less re-hashing as compared to MOD hashing when we need to add or remove new host from cache cluster.
-
cache client is a small and lightweight library which is integrated with service code and responsible for cache host selection moreover it knows about all cache servers additionally All clients should have same list else different clients have different view of consistent hashing values and same key will be routed to different hosts .
-
We use binary search for finding cache servers that owns the key because client stores the list of cache hosts in sorted order so as to facilitate fast host lookup.
-
TCP and UDP protocols are used for talking between cache client and cache host.If cache host is unavailable for some request it will be taken by client as a cache miss .
Maintaining a list of cache servers -
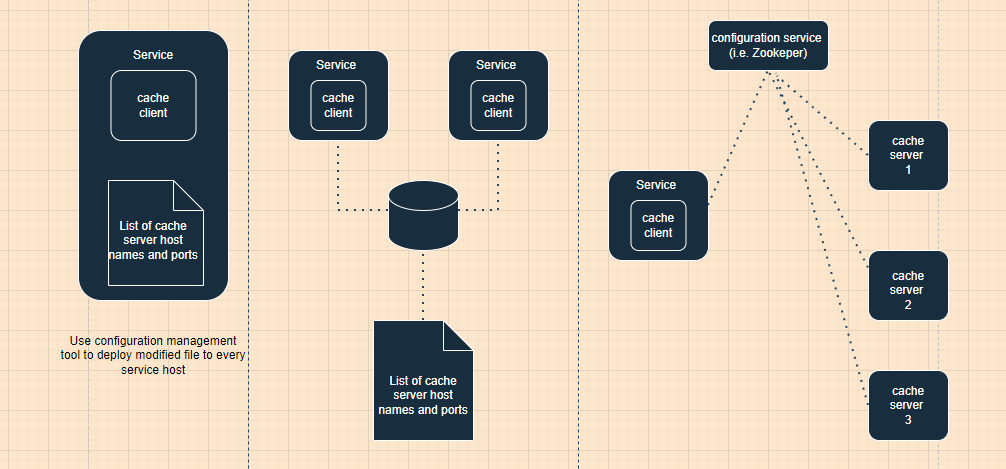
So from above we get a rough idea tha the list of cache hosts is the most important knowledge for clients. below we will discuss how this list is created,shared and maintained.
-
First one is to store a list of cache hosts in a file and deploy this file to service hosts using some continuous deployment piipeline.major drawback of this is that each time the list changes we need to make code change and deploy it to every service host.
-
In second option we put the file at a shared storage and make service host poll for the file periodically.In this case all service hosts try to retrieve the file from some common location e.g S3 storage service.here the process runs on each service host and polls for data from storage after a couple of minutes.The drawback of this is we still have to maintain the file manually and have to make changes to deploy it to the shared storage every time cache host dies or a new cache host added.
-
Third option is using configuration service for a distributed cache.In this case our configuration service monitors the health of our cache servers and if something is not working on cache servers it will notify all service hosts to stop sending request to this unavailable cache server and if a new cache server is added all service host are notified to send request to this cache server. here each cache server registers itself with configuration service and they snd heartbeats to configuration service periodiically.as long as hearbeats come to our configuration service cache server remains registered if heartbeats stops coming configuration service unregisters that faulty cache servers and every cache client gets list of registered cache servers from configuration service.This option is harder to implement its operational cost is high but it fully automated the list maintenance task and worth the cost.
With this article at OpenGenus, you must have the complete idea of System Design of Distributed Cache.