
VGG means Visual Geometry Group. But before diving straight into VGG-11 and its specifications, it is of utmost important to have a glimpse of AlexNet (just the basic part). AlexNet is primarily capable of object-detection.It takes into acccount overfitting by using data augmentation and dropout. It replaces tanh activation function with ReLU by encapsulating its distinct features for over-pooling. VGG came into picture as it addresses the depth of CNNs.
It is a pre-trained model, on a dataset and contains the weights that represent the features of whichever dataset it was trained on. Using a pre-trained model one is saving time. Already an ample amount of the time and computation resources has been spent to learn a lot of features and the model will likely benefit from it.
The numeral after the keyword signifies the number of weighted layers in the model. VGG models takes as input 224 x 224 pixel image, this image should be in RGB format. If the reader wonders why only 224 out of 0 to 255 pixel range of RGB this was taken into account to deal with a constant image size. Now coming and listing out the layers of VGG model that also form the base of VGG-11 as well.
Convolutional Layer: The kernel size here is 3 x 3. This 3 x 3 signifies the size of the convolutional filter. Matrix elements are taken one at a time to perform the respective operation. Here ReLU activation function is taken into consideration.
The max pooling layer returns the pixel with maximum value from a set of pixels within a kernel.The convolution stride is fixed to 1 pixel. The keyword stride here means the step of convolutional network. One important thing here is the choice of activation function, this is a non-linear transformation that defines the output of a neural network). ReLU is chosen due to the following advantages:
- Simpler Computation
- Highly suitable for big neural networks as it reduces the training and evaluation times.
- ReLUs only saturate when the input is less than 0 which is preventable by leaky ReLU
- ReLU reduces the computational cost for training a network. This allows the training of larger nets with more parameters at the same computational cost.
This was the detailed explanation of the various elements and aspects present in Convolutional Layer.
Fully-Connected Layers : VGG-11 has three fully connected nodes.
- The upper two fully-connected has 4096 channels, the diagramatic representation of the same has been provided in the image below.
- The third fully-connected layer has 1000 channels this is because each corresponds to one class.
The significance of Softmax Activation function:
In simple terms, this Activation function is used for the conversion of numbers into respective probabilities. In mathematics, the sum of probabilities is equal to 1, likewise here also the probablities that are output by the softmax activation functino sums up to 1.
Softmax turn logits (numeric output of the last linear layer of a multi-class classification neural network) into probabilities by take the exponents of each output and then normalize each number by the sum of those exponents so the entire output vector adds up to one — all probabilities should add up to one.
Like any other function in Python, Softmax function also is composed of two major entitites, e rasie to a power divide by a sum of some sort.It is implemented in the last, in order to obtain the probablities that could be used to identify which feature is predicted and further make decisions on the accuracy of the model.
Key takeaways from Softmax Activation Function:
- Used for multi-classification in logistic regression model.
- The probabilities sum will be 1
- Used in the different layers of neural networks.
- The high value will have the higher probability than other values.
Talking about VGG-11, it attributes to 11 weighted layers, Weights represent the strength of connections between units in adjacent network layers,are used to connect the each neurons in one layer to the every neurons in the next layer, weights near zero mean changing this input will not change the output. Note the Max-Pooling layer is not counted as weighted layer as its a feature map containing the most prominent features. Maximum pooling, or max pooling, is a pooling operation that calculates the maximum, or largest, value in each patch of each feature map.The results are down sampled or pooled feature maps that highlight the most present feature in the patch, not the average presence of the feature in the case of average pooling. This has been found to work better in practice than average pooling for computer vision tasks like image classification
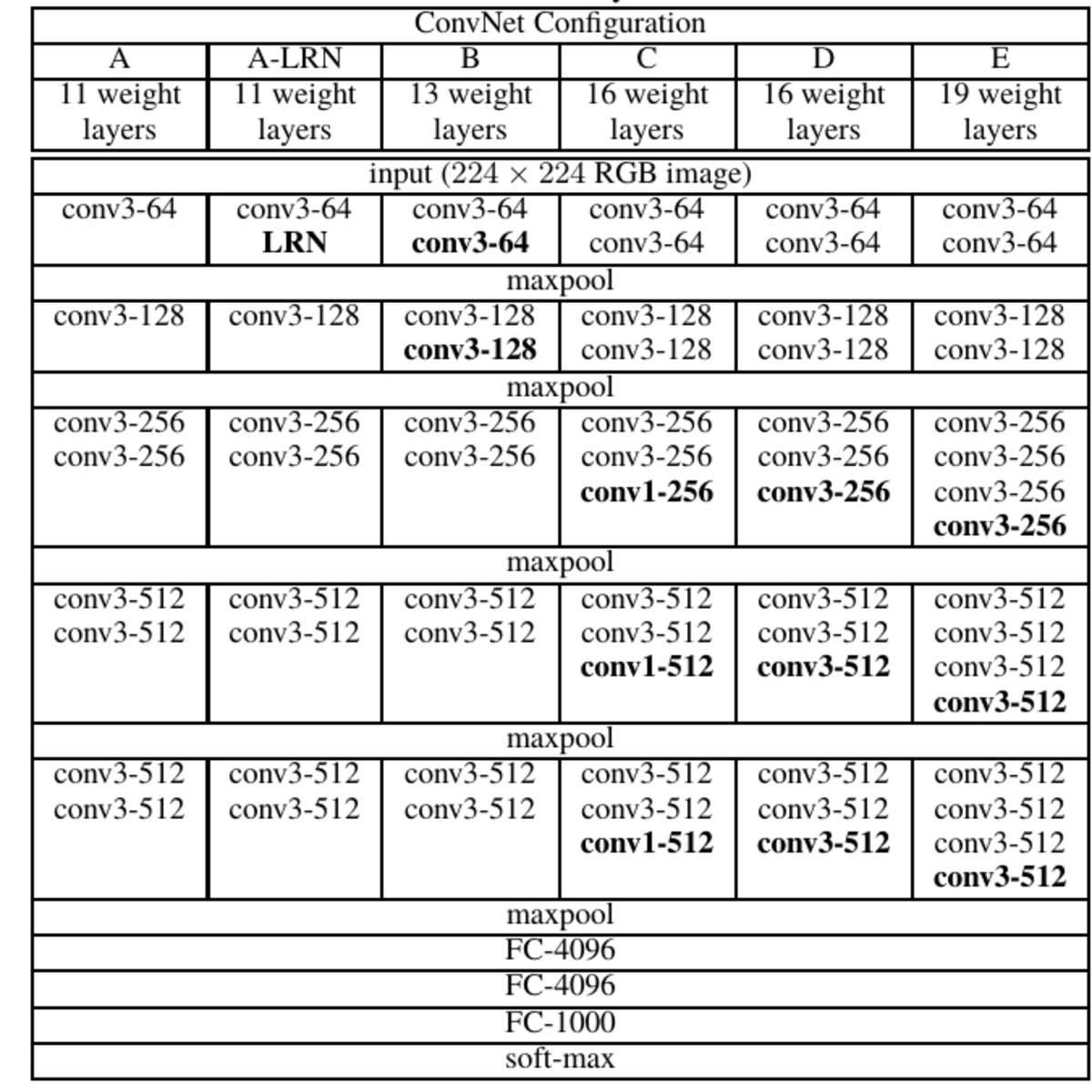
The 11 layers of VGG-11
- Convolution using 64 filters + Max Pooling
- Convolution using 128 filters + Max Pooling
- Convolution using 256 filters
- Convolution using 256 filters + Max Pooling
- Convolution using 512 filters
- Convolution using 512 filters + Max Pooling
- Convolution using 512 filters
- Convolution using 512 filters + Max Pooling
- Fully connected with 4096 nodes
- Fully connected with 4096 nodes
- Output layer with Softmax activation with 1000 nodes.
Note: Here the max-pooling layer that is shown in the image is not counted among the 11 layers of VGG, the reason for which is listed above. In accordance with the Softmax Activation function, it can be easily verified from the VGG-11 architecture.
One major conclusion that can be drawn from the whole study is VGG-11 prospers with an appreciable number of layers due to small size of convolution filter. This accounts for good accuracy of the model and decent performance outcomes.
VGG incorporates 1x1 convolutional layers to make the decision function more non-linear without changing the receptive fields.Labeled as deep CNN, VGG surpasses datasets outside of ImageNet.
So, this was the detailed account of VGG-11, this article at OpenGenus covers various important aspects that should be known while implementing the same. Different layers, the architecture of VGG-11, activation functions have been made sure to cover in this specific article.
Learn more: