
The Inception model is an important breakthrough in development of Convolutional Neural Network (CNN) classifiers. It has a complex(heavily engineered) architecture and uses many tricks to push performance in terms of both speed and accuracy.
The popular versions on the Inception model are:
- Inception V1
- Inception V2 & Inception V3
- Inception V4 and Inception-Resnet
Each version shows an iterative improvement over the previous one
Now let's dive deeper into each of these versions and explore into depths!
Inception V1 Model
The reason why this model came into existence was that the striking parts in an image can have a large variation in size. For instance, an image with a car can be either of the following, as shown below. The area occupied by the car is different in each image. Due to this, choosing the right kernel size becomes tough.

- A kernel(filter) is effectively an operator applied to the whole image so that the information encoded in the pixels is transformed
- A larger kernel gives a more global distribution, whereas a shorter one gives a local distribution
- Very deep networks are prone to overfitting. It is also hard to pass gradient updates through the entire network
- Gradient descent is an iterative optimization algorithm of the first order for finding a local minimum of a differentiable function
The solution that came up with this model was that filters with multiple sizes would be operating on the same level.The network essentially would get a bit “wider” rather than “deeper”. The inception module was designed to reflect the same.
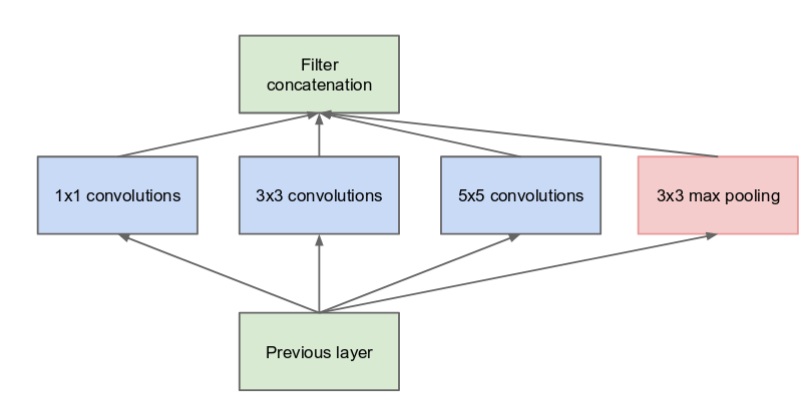
The below image is the “naive” inception module. It performs convolution on an input, with 3 different sizes of filters (1x1, 3x3, 5x5). Along with this, max pooling is also performed. The outputs are concatenated and sent to the next inception module
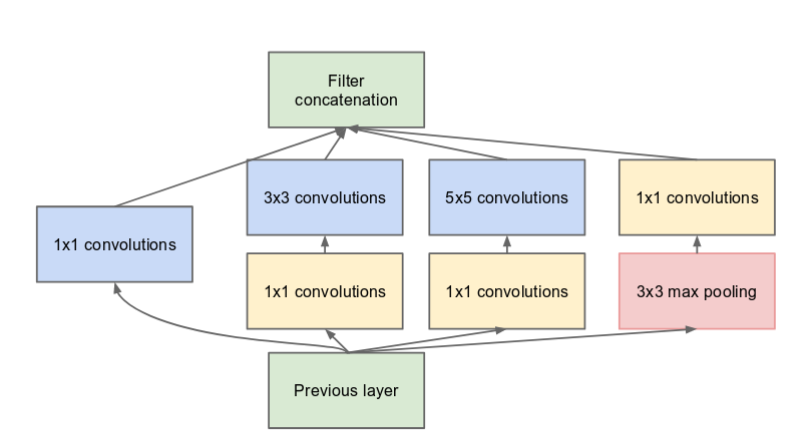
As the deep networks are computationally expensive, the number of input channels by adding an extra 1x1 convolution before the 3x3 and 5x5 convolutions are limited.Though adding an extra operation seems implausible, 1x1 convolutions are far more cheaper than 5x5 convolutions, and the reduced number of input channels also help
Using the dimension shortened inception module, a neural network architecture was built. This was known as GoogLeNet (Inception v1)
Inception V2 & Inception V3
The proposed upgrades which increased the accuracy and reduced the computation complexity were present in these versions.
The concept of smart factorization was used to gain more efficiency in terms of computational power
- The solution that was put forth was to factorize 5x5 convolution to two 3x3 convolution operations to improve computational speed. Although this seems unreasonable, a 5x5 convolution is 2.78 times more expensive than a 3x3 convolution. So stacking two 3x3 convolutions infact leads to a hike in performance
The goal of factorizing convolutions is to reduce the number of connections / parameters without reducing the efficiency of the network
-
Moreover, factorizing convolutions of filter size nxn to a combination of 1xn and nx1 convolutions was 33% cheaper
-
The filter banks inside the module were extended to eliminate the conceptual barrier (made wider rather than deeper). Alternatively, if the module was reduced in size, the measurements would be unnecessarily reduced, and hence the details would be lost
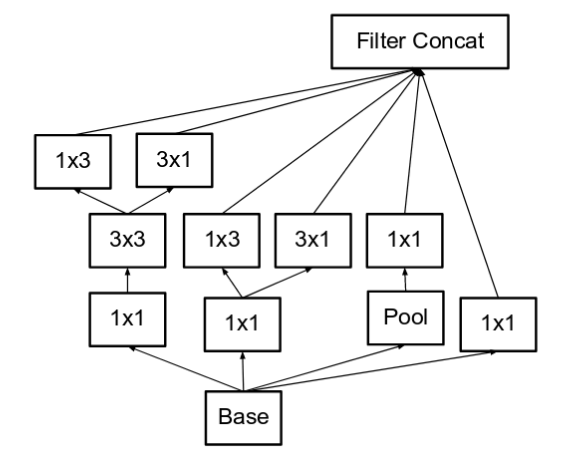
Inception Net V3 incorporated all of the above upgrades stated for Inception V2, and in addition used the following:
- RMSProp Optimizer.
- Factorized 7x7 convolutions.
- BatchNorm in the Auxillary Classifiers.
- Label Smoothing (A type of regularizing component added to the formula of loss which prevents the network from becoming overly confident about a class, inhibits overfitting)
Inception V4 and Inception ResNet
They were added to make the modules more homogeneous. It was also noticed that some of the modules were more complicated than necessary. This enabled hiking performance by adding more of these uniform modules
- The solution provided by this version was that the Inception v4 "stem" was modified. The stem refers to the initial set of actions performed before the Inception blocks are incorporated. This is a complete version of Inception, without any residual relations. It can be trained to backpropagate without partitioning the replicas, with memory optimization
Backpropagation is about knowing how weight shifts and biases affect the cost function in a network
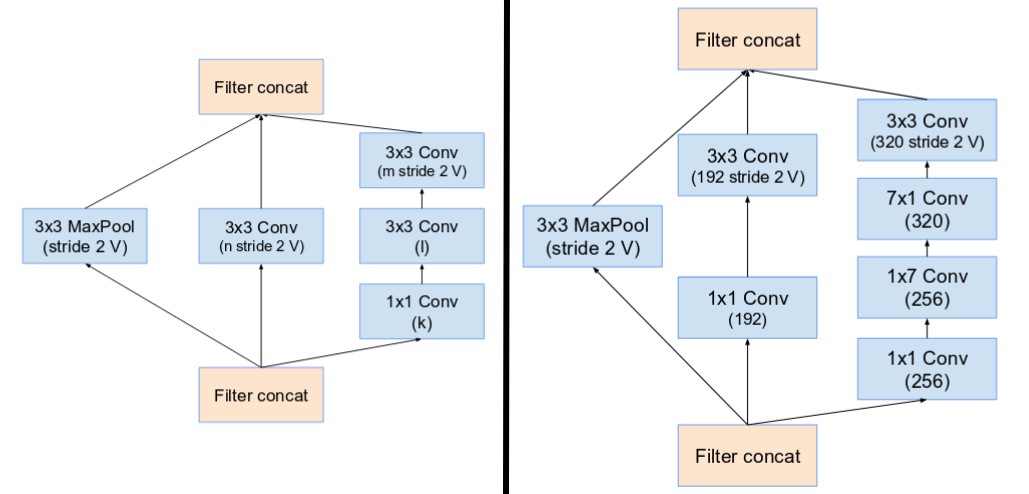
Specialized Reduction Blocks introduced by Inception v4, which were used to adjust the grid width and height. The earlier versions did not specifically include reduction blocks but they incorporated the feature
Inspired by the performance of the ResNet, a hybrid inception module was proposed. There are two sub-versions of Inception ResNet, namely v1 and v2
The problem it solved was to introduce residual connections to the input which added the output of the inception module's convolution operation
The solution was :
- Input and output after convolution have to have the same dimensions for residual addition to function. Therefore, we use 1x1 convolutions to suit the depth sizes after the initial convolutions (Depth increases after convolution)
*Inside the main starting modules the pooling operation was replaced in furtherance of the residual connections. However, such operations can still be contained in the reduction blocks - Residual unit networks deeper in the architecture have caused the network to "die" if the number of filters exceeded 1000. Therefore, the residual activations were scaled by a value around 0.1 to 0.3 to increase stability
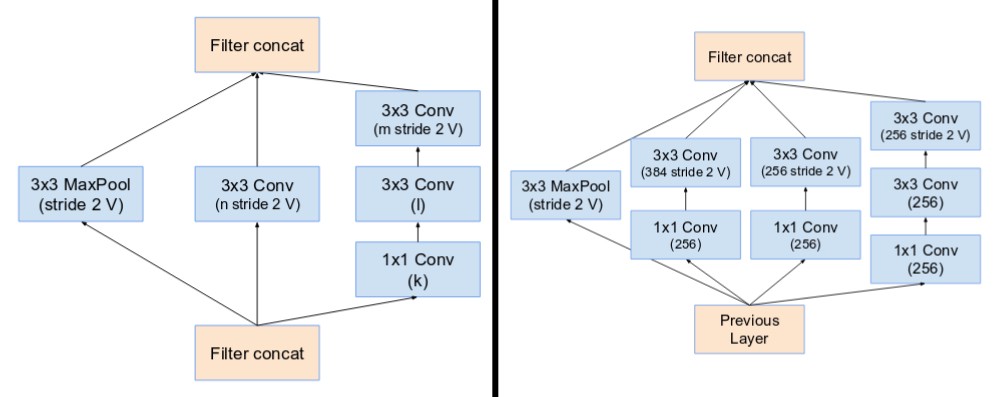
The final network layout for both Inception v4 and Inception-ResNet are as follows:
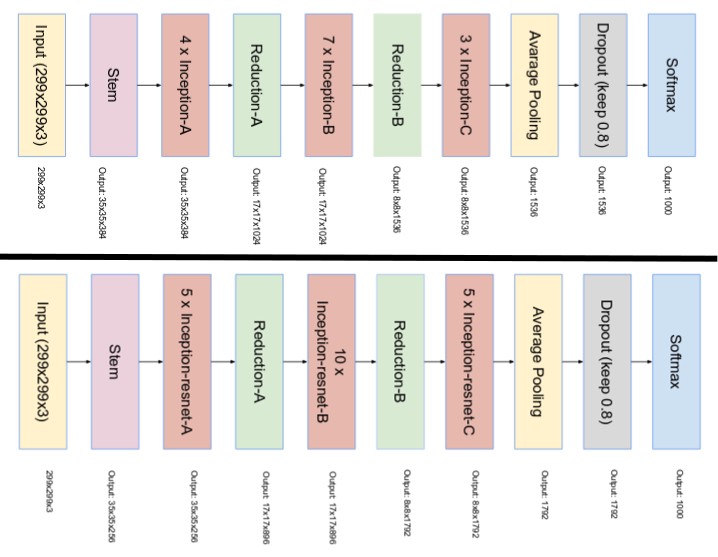
So, this article gave us an entire overview of the Inception pre-trained CNN model along with a detailed description about its versions and network architectures
For more interesting articles on Machine Learning and CNNs, refer the following links below: