
In this article, we have solved the problem of Water distribution using Minimum Spanning Tree, Union Find and Sorting Algorithms.
Pre-requisites:
Problem Statement
You are given n houses in a village. Here you have to supply water to all the houses. Either you can build a well at a house, or else construct a pipeline from another well to it. To build a well directly in a house, it will cost wells[i] and cost to lay pipes between houses are given by the array pipes, where each pipes[i]=[House1, House2, Cost] represents the cost to connect two houses together using a pipe. All pipe connections made are bidirectional.
Print the minimum total cost to supply water to all houses.
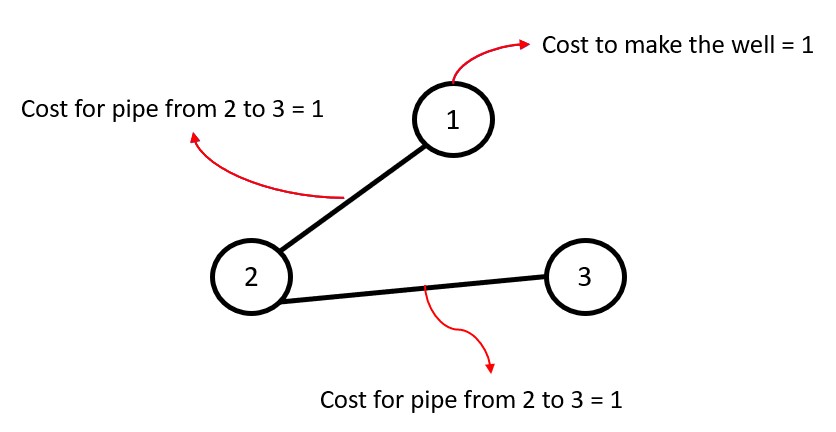
Input: n = 3, wells = [1,2,2], pipes = [[1,2,1],[2,3,1]]
Output: 3
Explanation: Here the best way to build a well in the first house with cost 1 and connectthe other houses to it with cost 2, and hence the total is 3.
Observation
- Here the cost of building a well in a house is a fixed cost, ie, there are no way to reduce or influence it. Where as, the cost to lay pipes differ, since it depends in what path we consider.
- The graph formed by the houses and pipes is undirected, which means that the cost of laying a pipe between two houses is the same in both directions. Therefore, we can represent the graph using an adjacency list or an adjacency matrix.
- To find the minimum total cost, of supplying water to all the houses, we need to find a minimum spanning tree of the graph, which is a subset of the edges that connects all the vertices with the minimum possible total edge weight.
- Kruskal's algorithm is an efficient algorithm for finding a minimum spanning tree, which works by adding the edges in non-decreasing order of their weights and checking if they form a cycle in the graph. If they don't form a cycle, the edge is added to the minimum spanning tree.
- To implement Kruskal's algorithm, we need a data structure to maintain a set of disjoint subsets of the vertices. The Union-Find data structure is a commonly used data structure for this purpose.
- Once we have found the minimum spanning tree, we can calculate the total cost of supplying water to all the houses by adding up the weights of the edges in the minimum spanning tree.
Approach
Intuitive steps
- Create vector
costsofEdgeCostobject to represent connections . - Push data in wells vector and pipes vector into costs.
- Sort the costs vector in increasing order of costs.
- Create
UnionFindobject with thenumber of nodes (wells and pipes) + 1. - Check if each nodes are connected or not using
find(). If not, connect usingunionSets(). - While connecting add the cost to
minCostand reduce number of nodes by1. - Return the
minCostwhenn == 0.
Explained
- First we will create a vector of
EdgeCostobjects called costs insideminCostToSupplyWater()to store the edges in the graph. We push it in the form0, i, wells[i-1]. When adding the cost of building wells, the costs list is initialized with edges from node0to each of the houses, with the cost being the corresponding well cost from the input wells array. This is why0is used as the first node. The houses are numbered from1tonbut the wells vector is0indexed, thats why we pushwells[i-1]. - After that we will add the costs of connecting pipes between houses into the
costslist. Thepipesvector is a2Dvector wherep[x][0]is the index of house one,p[x][1]is the index of house two andp[x][2]is the cost to connect these houses. We will add the contents in thepipesvector into thecostvector. Now we will sort thecostvector. The purpose of sorting is to ensure that we always consider the edges with lowest possible. Here we will sort the objects based on thecostmember variable of each object. - Now we will call the
UnionFind uf(n + 1)to initialize an instances of theUnionFindclass withn + 1elements. By initializingufwithn+1, we are creatingnelements numbered from1tonand an additional element numbered0, which represents the index corresponding to the well at house1. - The
UnionFindclass has two operations:find(x): The find operation returns the root element of the set to which a given element belongs. In this implementation, the find method takes an elementxas input and returns its root element by recursively following the parent pointers ofxuntil it reaches an element whose parent is itself.unionSet(x,y): TheunionSetsoperation is used to merge two disjoint sets into a single set. Here theunionSetsmethod takes two elementsxandyas input and merges the sets to which they belong by setting the parent of the root element of one set to the root element of the other set, and updating the rank of the root element accordingly to maintain a balanced tree structure.
- Now we will create & initialize the
minCosts = 0. The next step is to iterate through the sorted vectorcosts. Each of the edges present inside the vector represents a pipe or a wall. For each edge, we will find the roots of the tree to which the two nodes, connected by the edge, belong to using thefind()method present inUnionFinddata structure. If the roots are same it means that both the nodes are already connected and we will continue to the next edge. - If the roots are different, it means that they are not connected and we need to connect them. To connect them we will use
unionSets()method of theUnionFinddata structure, which merges the trees to which the two nodes belong to. At this time we will add the cost of the edge tominCostvariable. After each union of two sets, we connect one node, so we will decrease the node countnby one.We will return theminCostonce we have connected all the nodes(n = 0). In this way we make sure that we have the minimum cost.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class OptimizeWaterDistribution {
public:
int minCostToSupplyWater(int n, vector<int>& wells, vector<vector<int>>& pipes) {
// Construct a list of all edges with their costs
vector<EdgeCost> costs;
for (int i = 1; i <= n; i++) {
costs.push_back(EdgeCost(0, i, wells[i - 1]));
}
for (auto p : pipes) {
costs.push_back(EdgeCost(p[0], p[1], p[2]));
}
sort(costs.begin(), costs.end());
// Initialize Union-Find data structure
UnionFind uf(n + 1);
// Iterate over edges and connect nodes using Union-Find
int minCosts = 0;
for (auto edge : costs) {
int rootX = uf.find(edge.node1);
int rootY = uf.find(edge.node2);
if (rootX == rootY) continue;
minCosts += edge.cost;
uf.unionSets(rootX, rootY);
// For each union, we connect one node
n--;
// If all nodes are already connected, terminate early
if (n == 0) {
return minCosts;
}
}
return minCosts;
}
private:
struct EdgeCost {
int node1;
int node2;
int cost;
EdgeCost(int n1, int n2, int c) : node1(n1), node2(n2), cost(c) {}
bool operator<(const EdgeCost& other) const {
return cost < other.cost;
}
};
class UnionFind {
public:
UnionFind(int size) {
parent.resize(size);
rank.resize(size);
for (int i = 0; i < size; i++) {
parent[i] = i;
rank[i] = 0;
}
}
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
void unionSets(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootX] = rootY;
if (rank[rootX] == rank[rootY]) {
rank[rootY]++;
}
}
}
private:
vector<int> parent;
vector<int> rank;
};
};
int main() {
OptimizeWaterDistribution solution;
int n = 3;
vector<int> wells = {1, 2, 2};
vector<vector<int>> pipes = {{1, 2, 1}, {2, 3, 1}};
int minCost = solution.minCostToSupplyWater(n, wells, pipes);
cout << "Minimum cost to supply water to all houses: " << minCost << endl;
return 0;
}
Output
Minimum cost to supply water to all houses: 3
Complexities
It takes O(n) time when we iterate through the loop first time where n is the total wells possible. The second loop takes O(m) time, where m is the number of pipes.
So the sorting will take around O((n+m)log(n+m)) time since we will have n + m edges. In the end we will perform at most n-1 unions, each of which takes O(log n) time in the worst case, so it would take O((n+m)log(n)) time. Hence we can say that the overall time complexity is O((n+m)log(n+m)).
Here we are using vector of size n+1 for the parent and rank arrays, which will take O(n) space. For the costs vector we have m elements then it will take O(m) space. Hence the overall space complexity is O(max(n,m)).
With this article at OpenGenus, you must have the complete idea of solving this problem of Minimum Spanning Tree.