
In this article, we have presented good implementation designs considering there are multiple sorting algorithms and different datatypes.
Introduction
What is Sorting?
Sorting algorithms are an essential part of computer science and are used to arrange data in a particular order.
The concept of sorting has applications in various fields, including databases, operating systems, computer graphics, and scientific computing. Sorting algorithms are used to arrange data in ascending or descending order based on a given criterion.
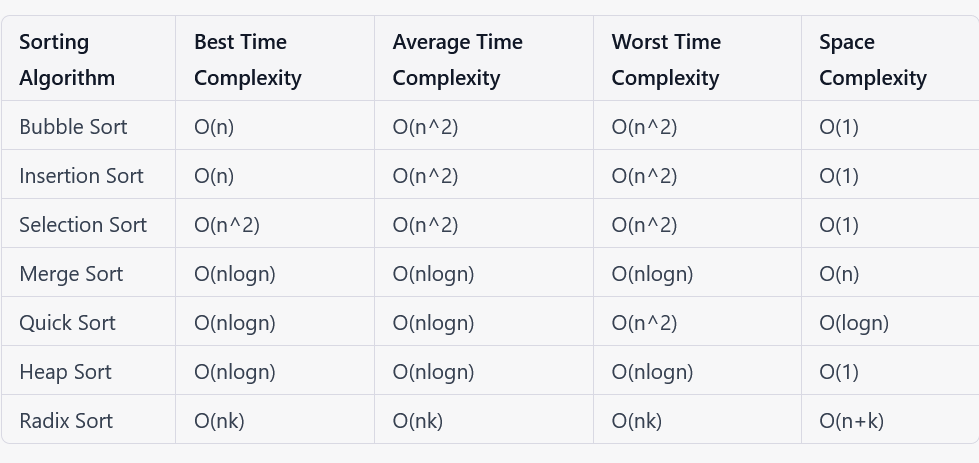
Sorting algorithms can be classified based on their complexity, efficiency, and the types of data they can sort. Commonly used sorting algorithms include Bubble Sort, Insertion Sort, Selection Sort, Merge Sort, Quick Sort, and Heap Sort. In addition to the algorithm's efficiency, the design of the algorithm is also essential.
What is Object-Oriented Programming (OOP)?
Object-Oriented Programming (OOP) is a popular paradigm used in software development that focuses on the design and organization of code into classes and objects. OOP design is essential in the implementation of sorting algorithms because it allows for the creation of modular, reusable, and maintainable code.
OOP design provides a way to encapsulate data and behavior, allowing developers to create reusable code that can be easily extended and modified. It also enables the use of interfaces, inheritance, and polymorphism, which can improve the flexibility and scalability of the code.
Overview of Sorting Algorithms
Sorting algorithms are used to arrange data in a particular order based on a given criterion. There are several popular sorting algorithms that differ in their complexity, efficiency, and the types of data they can sort. Here is an overview of some of the most commonly used sorting algorithms:
Bubble Sort:
Bubble Sort is a simple sorting algorithm that repeatedly compares adjacent elements and swaps them if they are in the wrong order. The algorithm has a time complexity of O(n^2) and is efficient for small datasets but becomes inefficient for larger ones.
Pros: Simple and easy to implement.
Cons: Inefficient for larger datasets and has a time complexity of O(n^2).
Approach:
Bubble Sort is a simple and intuitive sorting algorithm that works by repeatedly swapping adjacent elements in an array that are out of order until the entire array is sorted. It starts by comparing the first two elements of the array, swapping them if necessary, and then moving on to the next pair of adjacent elements. This process is repeated until all pairs of adjacent elements have been compared.
Insertion Sort:
Insertion Sort is another simple sorting algorithm that works by iterating through the list and inserting each element into its proper position in the sorted array. The algorithm has a time complexity of O(n^2) and is efficient for small datasets.
Pros: Simple and easy to implement, efficient for small datasets.
Cons: Inefficient for larger datasets and has a time complexity of O(n^2).
Approach
Insertion Sort is a sorting algorithm that works by iteratively building a sorted subarray at the beginning of an array. Starting with the second element, it compares the current element with its predecessor and shifts the predecessor subarray until the current element is in its correct location. This process is repeated for each element in the array until the entire array is sorted.
Selection Sort:
Selection Sort works by selecting the smallest element in the unsorted portion of the array and swapping it with the first element. The algorithm has a time complexity of O(n^2) and is not efficient for large datasets.
Pros: Simple and easy to implement.
Cons: Inefficient for larger datasets and has a time complexity of O(n^2).
Approach
Selection Sort is a simple and intuitive sorting algorithm that works by repeatedly selecting the minimum element from an unsorted subarray and swapping it with the element at the beginning of the subarray. This process is repeated for each element in the array until the entire array is sorted. At each iteration, Selection Sort finds the minimum element in the remaining unsorted subarray and swaps it with the element at the current index.
Merge Sort:
Merge Sort is a divide-and-conquer algorithm that works by dividing the array into smaller sub-arrays, sorting them, and then merging them back together. The algorithm has a time complexity of O(nlogn) and is efficient for large datasets.
Pros: Efficient for large datasets, has a time complexity of O(nlogn).
Cons: Requires additional memory to merge the sub-arrays.
Approach
Merge Sort is a popular and efficient sorting algorithm that works by dividing the unsorted array into smaller subarrays recursively until each subarray contains only one element. Then, the algorithm merges adjacent pairs of subarrays in a way that ensures that the merged subarray is sorted. This process is repeated for each pair of subarrays until the entire array is sorted.
Quick Sort:
Quick Sort is another divide-and-conquer algorithm that works by selecting a pivot element and partitioning the array around it. The algorithm has a time complexity of O(nlogn) and is efficient for large datasets.
Pros: Efficient for large datasets, has a time complexity of O(nlogn).
Cons: Worst-case time complexity can be O(n^2).
Approach
Quick sort is a divide-and-conquer algorithm that works by selecting a pivot element from the array and partitioning the other elements into two sub-arrays, according to whether they are less than or greater than the pivot. The sub-arrays are then recursively sorted using the same process until the entire array is sorted. In practice, the pivot is usually chosen as the last element of the sub-array, and the partitioning process is performed using two pointers that move towards each other until they identify elements that are in the wrong order, which are then swapped.
Heap Sort:
Heap Sort works by building a binary heap and repeatedly removing the maximum element from it. The algorithm has a time complexity of O(nlogn) and is efficient for large datasets.
Pros: Efficient for large datasets, has a time complexity of O(nlogn).
Cons: Not as easy to implement as other sorting algorithms.
Approach
Heap Sort is a comparison-based sorting algorithm that works by first building a binary heap from the unsorted array. The heap is structured as a complete binary tree, where each parent node is greater (or less) than its children nodes. Once the heap is built, Heap Sort repeatedly extracts the maximum (or minimum) element from the root of the heap, sends it to the end of the heap, and decrements the heap size. This process is repeated until the heap has only one node.
Radix Sort:
Radix Sort is a non-comparative sorting algorithm that works by grouping elements by their digits or bytes. The algorithm has a time complexity of O(nk) where k is the number of digits or bytes.
Pros: Efficient for sorting numbers with a fixed number of digits.
Cons: Not suitable for sorting arbitrary data types, may require additional memory.
Approach
Radix Sort is a non-comparative sorting algorithm that sorts elements by comparing their individual digits. The algorithm first finds the maximum element in the array and then sorts the elements based on their least significant digit, then their second least significant digit, and so on, until all digits have been considered. Radix Sort uses a helper method called Counting Sort to sort the elements based on each digit.
In summary, the choice of sorting algorithm depends on the size and type of the dataset being sorted, as well as the desired efficiency and memory usage.
Bubble Sort, Insertion Sort, and Selection Sort are simple and easy to implement but are inefficient for large datasets. Merge Sort, Quick Sort, and Heap Sort are more efficient for larger datasets, but may require additional memory or have a worst-case time complexity of O(n^2). Radix Sort is efficient for sorting numbers with a fixed number of digits but is not suitable for arbitrary data types.
CHOOSING THE BEST SORTING ALGORITHM ACCORDING TO ARRAY
| Length of Input | Preferred Sorting Algorithm | Reasoning |
|---|---|---|
| (<= 10) | Insertion Sort | Insertion sort is simple and efficient for small inputs |
| (> 10 and <= 100) | Quicksort | Quicksort has good average-case performance for mid-sized inputs |
| (> 100 and <= 1000) | Mergesort | Mergesort has good worst-case performance for larger inputs |
| (> 1000) | Heap sort | Heap sort has good worst-case performance and is space efficient |
DESIGN PRINCIPLE OF INBUILT SORTING ALGORITHM
We know from the official documentation of Java(jdk11):
For Arrays.sort (primitives):
The sorting algorithm is a Dual-Pivot Quicksort by Vladimir Yaroslavskiy, Jon Bentley, and Joshua Bloch.
This algorithm
* offers O(n log(n)) performance on many data sets and
* is typically faster than traditional (one-pivot) Quicksort implementations.
For Collections.sort (objects):
This implementation is a stable, adaptive, iterative mergesort
This implementation dumps the specified list into an array, sorts the array, and iterates over the list resetting each element from the corresponding position in the array.
Idea:
Arrays are a low-level construct in Java, and their size is fixed once they are initialized. This means that the sorting algorithm used for arrays needs to be efficient in terms of both time and space complexity, and it should also be able to work in-place (i.e., without using additional memory). For this reason, Arrays.sort() uses a variant of quicksort, which is an efficient in-place sorting algorithm.
On the other hand, the Collections.sort() method works on objects that implement the List interface, which is a high-level construct in Java. Unlike arrays, lists can grow and shrink dynamically, and they provide many operations for manipulating their contents, such as adding, removing, and searching for elements. This means that the sorting algorithm used for lists can afford to use more memory and may not need to be in-place.
**Implementing Dual Pivot Quick sort **
static void swap(int[] arr, int i, int j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
static void dualPivotQuickSort(int[] arr,int low, int high)
{
if (low < high)
{
int[] piv;
piv = partition(arr, low, high);
dualPivotQuickSort(arr, low, piv[0] - 1);
dualPivotQuickSort(arr, piv[0] + 1, piv[1] - 1);
dualPivotQuickSort(arr, piv[1] + 1, high);
}
}
static int[] partition(int[] arr, int low, int high)
{
if (arr[low] > arr[high])
swap(arr, low, high);
int j = low + 1;
int g = high - 1, k = low + 1,
p = arr[low], q = arr[high];
while (k <= g)
{
if (arr[k] < p)
{
swap(arr, k, j);
j++;
}
else if (arr[k] >= q)
{
while (arr[g] > q && k < g)
g--;
swap(arr, k, g);
g--;
if (arr[k] < p)
{
swap(arr, k, j);
j++;
}
}
k++;
}
j--;
g++;
swap(arr, low, j);
swap(arr, high, g);
return new int[] { j, g };
}
Difference between Dual pivot quicksort and quicksort:
Dual pivot quicksort:
• Chooses two pivot elements, usually the first and last elements of the array.
• Partitions the array into three subarrays: elements smaller than the first pivot, elements between the first and second pivot, and elements greater than the second pivot.
• Places the pivot elements in their final positions in the array.
• Recursively applies the algorithm to the subarrays.
• Has been shown to be faster than regular quicksort in some cases, particularly when sorting arrays with many duplicate elements.
Quicksort:
• Chooses a single pivot element, usually the last element of the array.
• Partitions the array into two subarrays: elements smaller than the pivot and elements greater than or equal to the pivot.
• Places the pivot element in its final position in the array.
• Recursively applies the algorithm to the subarrays.
• Is a widely-used and efficient sorting algorithm, but can have poor performance in some cases, such as when sorting already sorted or nearly sorted arrays.
OOP Design for Sorting Algorithms with Java Implementation using a Generic Array Class
import java.util.*;
public class Array {
// Encapsulate the array sorting methods in a private inner class.
private static class Sorter {
public static <T> void quickSort(T[] array, Comparator<T> comparator) {
quickSort(array, 0, array.length - 1, comparator);
}
private static <T> void quickSort(T[] array, int low, int high, Comparator<T> comparator) {
// Implementation of quickSort for generic array
}
private static void quickSort(Integer[] array, int low, int high) {
// Implementation of quickSort for Integer array
}
private static void quickSort(String[] array, int low, int high) {
// Implementation of quickSort for String array
}
}
// Inherit from the private Sorter class to make the sort methods public.
public static class Sort extends Sorter {
// Empty constructor since all methods are static.
}
public static <T> void sort(T[] array) {
if (array == null || array.length <= 1) {
return;
}
// Choose sorting algorithm based on the size of the array.
if (array.length < 1000) {
Sort.quickSort(array, 0, array.length - 1, null);
} else {
Arrays.sort(array);
}
}
public static <T> void sort(T[] array, Comparator<T> comparator) {
if (array == null || array.length <= 1) {
return;
}
// Choose sorting algorithm based on the size of the array.
if (array.length < 1000) {
Sort.quickSort(array, comparator);
} else {
Arrays.sort(array, comparator);
}
}
public static void main(String[] args) {
List<Integer> intArr = new ArrayList<>();
intArr.add(3);
intArr.add(1);
intArr.add(5);
Integer[] intArray = intArr.toArray(new Integer[0]);
Array.sort(intArray);
System.out.println(Arrays.toString(intArray)); // [1, 3, 5]
List<String> strArr = new ArrayList<>();
strArr.add("banana");
strArr.add("apple");
strArr.add("cherry");
String[] strArray = strArr.toArray(new String[0]);
Array.sort(strArray);
System.out.println(Arrays.toString(strArray)); // [apple, banana, cherry]
List<MyObject> customArr = new ArrayList<>();
customArr.add(new MyObject(1, "one"));
customArr.add(new MyObject(2, "two"));
customArr.add(new MyObject(3, "three"));
MyObject[] customArray = customArr.toArray(new MyObject[0]);
Array.sort(customArray, Comparator.comparing(MyObject::getId));
System.out.println(Arrays.toString(customArray)); // [{1, "one"}, {2, "two"}, {3, "three"}]
}
}
Output:
[1, 3, 5]
[apple, banana, cherry]
[{1, "one"}, {2, "two"}, {3, "three"}]
Idea:
The code uses an algorithm called "quicksort" to sort the arrays. Quicksort is a popular and efficient sorting algorithm that works by recursively dividing the array into smaller subarrays based on a "pivot" element, and then rearranging the elements such that all the elements less than the pivot come before it and all the elements greater than the pivot come after it. This process continues until the entire array is sorted.
The code also provides a way to sort arrays of objects based on a custom ordering. This is done using "comparators", which are objects that compare two objects to determine their relative ordering. For example, if you have an array of strings and you want to sort them in alphabetical order, you can use a comparator that compares the strings based on their lexicographic order.
The code provides two methods for sorting arrays - one that takes an array and sorts it in ascending order, and another that takes an array and a comparator and sorts it based on the ordering specified by the comparator. The code checks the size of the array and chooses the appropriate sorting method to use - if the array is small enough, it uses the quicksort algorithm, otherwise, it uses the built-in "Arrays.sort" method.
Understanding the OOP design
Determining by Array size : The sort method now checks if the length of the array is less than the threshold, and if so, it calls the corresponding insertionSort method instead of quickSort. We also modified the main method to convert the List objects to arrays before passing them to the sort method.
OOP principles:
Encapsulation: The sorting methods are encapsulated within a private inner class called Sorter. This way, they are not visible or accessible from outside the Array class, but can still be used within the class. The Sort class inherits from Sorter and makes the sorting methods public.
Inheritance: The Sort class inherits from Sorter to make the sorting methods public.
Other concepts: The main additional concept used is the idea of choosing the sorting algorithm based on the size of the array.
Polymorphism : is already being used in this code through method overloading. The sort method is overloaded to handle different types of arrays and to accept a Comparator as an optional argument. The specific implementation of quickSort method to be called is determined based on the type of array passed in as an argument.
Abstraction: By using abstraction, we can achieve a more flexible and extensible design. Any custom object can implement the Sortable interface and be sorted using the sort method without having to pass a separate Comparator object. This improves the maintainability of the code and also makes it easier to understand and modify in the future.
Object-Oriented Design Principles
Object-Oriented Design Principles are essential guidelines for creating robust and maintainable software systems.
These principles are based on the concept of Objects, which represent entities in the real world and interact with each other to achieve a specific goal. In the context of Sorting Algorithms, applying OOP design principles helps in creating flexible, scalable, and reusable code.
**Encapsulation: **
Encapsulation is the practice of hiding the internal workings of an object and only exposing a set of public interfaces for other objects to interact with. This principle ensures that the internal state of an object is protected from outside interference and maintains data integrity.
In the context of sorting algorithms, encapsulation ensures that the internal state of the sorting algorithm is not modified directly by external objects, which may cause undesirable results. Encapsulation also enables the sorting algorithm to be easily integrated into larger software systems without affecting the existing code.
Inheritance:
Inheritance is the mechanism of creating a new class from an existing one, inheriting its properties and methods. This principle promotes code reuse and enables the creation of more specialized classes by inheriting from a more general one.
In the context of sorting algorithms, inheritance can be used to create specialized sorting algorithms based on a more general sorting algorithm. For example, a specialized sorting algorithm can be created by inheriting from a basic sorting algorithm and adding additional functionality to handle specific data types or optimize for specific use cases.
Polymorphism:
Polymorphism is the ability of an object to take on multiple forms. This principle enables objects to behave differently depending on the context in which they are used.
In the context of sorting algorithms, polymorphism allows the sorting algorithm to be applied to different data types, such as integers, strings, or objects. This enables the sorting algorithm to be reused across different software systems without requiring modifications to the underlying code.
**Abstraction: **
Abstraction is the process of defining a simplified interface to complex functionality. This principle promotes modular design and enables the creation of complex systems by breaking them down into smaller, more manageable components.
In the context of sorting algorithms, abstraction enables the sorting algorithm to be used as a black box, where the implementation details are hidden, and only the inputs and outputs are exposed. This simplifies the integration of the sorting algorithm into larger software systems and makes it easier to test and maintain.
In conclusion, applying OOP design principles in the implementation of sorting algorithms enables the creation of more flexible, scalable, and reusable code. By applying these principles, sorting algorithms can be designed to handle different data types and use cases, making them suitable for use in a wide range of software systems.

OOP Design for Sorting Algorithms
Object-Oriented Programming (OOP) can be used to create well-organized and maintainable sorting algorithms. Here are some key points to consider when applying OOP design to sorting algorithms:
*1. Design Patterns: *
Design patterns are reusable solutions to common programming problems. Three commonly used design patterns for sorting algorithms are the Template Method, Strategy, and Factory patterns.
- The Template Method pattern defines a skeleton of an algorithm and allows subclasses to provide their own implementation for certain steps.
- The Strategy pattern allows for flexible selection of an algorithm at runtime by encapsulating a family of algorithms and allowing them to be interchangeable.
- The Factory pattern provides an interface for creating objects without specifying the exact class of object that will be created.
Using these patterns can make sorting algorithms more modular, extensible, and reusable.
2. OOP Design Principles:
Encapsulation, inheritance, polymorphism, and abstraction are essential OOP design principles that can be applied to sorting algorithms to improve their performance.
- Encapsulation can be used to protect the internal state of the sorting algorithm and ensure that it is not modified by external objects.
- Inheritance can be used to create specialized sorting algorithms that build upon more general sorting algorithms.
- Polymorphism can be used to enable sorting algorithms to handle different data types or optimize for specific use cases.
- Abstraction can be used to define a simplified interface to the sorting algorithm, making it easier to integrate into larger software systems.
By applying these principles, sorting algorithms can be designed to be more flexible, scalable, and maintainable.
OOP Design for Different Datatypes
Object-Oriented Programming (OOP) design for sorting algorithms must be able to handle different data types to make the algorithm more flexible and scalable. Here are some key points to consider when designing sorting algorithms for different data types:
1. Implementation for Various Data Types:
Sorting algorithms can be implemented for various data types, such as integers, strings, and custom objects. The algorithm should be able to sort data in a specific data type and preserve the integrity of the data.
- Sorting integers is straightforward, as they can be compared using the usual comparison operators.
- Sorting strings can be done by comparing each character in the string, which can be done using the Unicode value of each character.
- Sorting custom objects requires defining how the objects should be compared.
Importance of Flexibility:
Sorting algorithms must be designed to be flexible enough to work with various data types. By using OOP principles, sorting algorithms can be designed to work with different data types without having to rewrite the entire algorithm for each data type.
- Encapsulation can be used to define a set of methods for comparing objects, which can be implemented differently for each data type.
- Inheritance can be used to define a base sorting algorithm that can be specialized for each data type.
- Polymorphism can be used to handle different data types and to optimize for specific use cases.
- Abstraction can be used to define a simplified interface to the sorting algorithm that hides the details of the implementation from external objects.
Conclusion
In conclusion of this article at OpenGenus, OOP design is essential for the implementation of efficient and scalable sorting algorithms. By applying OOP principles such as encapsulation, inheritance, polymorphism, and abstraction, sorting algorithms can be designed to be more flexible, maintainable, and optimized for specific use cases.
Compared to traditional implementations, OOP-designed sorting algorithms have several benefits. They are more modular, reusable, and easier to maintain. OOP design allows sorting algorithms to be easily extended to handle different data types and to be optimized for specific use cases. Moreover, OOP-designed sorting algorithms are better suited for use in large-scale applications, where performance and efficiency are critical.