
Adversarial Machine learning is the technique which involves applying different methods in order to construct or generate examples that are meant to fool the machine learning model. These types of examples are called adversarial examples.
In this article, we will explore how an adversary can exploit the machine learning model i.e. methods to generate adversarial examples and we will also talk about some defense strategies against these adversarial examples.
What is an adversarial example?
An adversarial example is an item or input which is slightly modified but in such a way that it does not look different from the original example but the machine learning model misclassifies it. The modifications to the original examples are done in such a way that the user is unable to tell the difference but the model produces incorrect output.

The image (b) is the clean image. Image (c) and (d) are adversarial images. Images (c) and (d) have adversarial perturbation 4 and 8 respectively.
Adversarial perturbation is basically a parameter or metric which shows how much the original image is changed.
Importance of Adversarial machine learning
It is really important to understand why do we need adversarial machine learning. Why do we need to talk about faulting a model we created for some specific purpose?
When it comes to applying machine learning to help the humans in real world tasks, there are possibilities that the model might perform in incorrect way and that can turn out to be quite dangerous. Let us talk about some real-world examples. Consider the self-driving cars that are being developed by big companies such as Tesla. Now if the car was on roads with real people around and some minor changes in some road signs or something leads to wrong decision analysis by the model, then it could turn out to be dangerous for the life of the people. Like if the model misclassifies the stop sign, that car could be a threat to people’s lives.
A study at MIT showed that the SOTA classifier misclassified a turtle made from a 3D printer to be a rifle. Another example can be from security cameras. Some changes and it could lead to the camera not detecting the human and that kind of manipulations can be used by intruders to break into places with valuable thing or do some wrong things.
Methods to generate adversarial examples
X- an image, typically a 3D tensor.
Ytrue- true class for the image X
J(X,y)- cross entropy cost function of the neural network.
Clip{}- function which performs per pixel clipping if image X' so the result will be in Linf neighbourhood of source image X.
Fast Method
- Fast Method: This is one of the simplest methods to generate adversarial example. In this method, the cost function is linearized and solving for the perturbation is done that maximizes the cost subject to Linf constraint. This may be done in closed form, for the cost of one call to back-propagation:
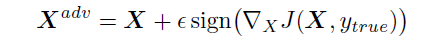
This method is called fast just because it is faster than other methods.
Basic iterative method
- Basic iterative method: In this method, we apply the fast method multiple times with small step size and we will clip the pixel values of the intermediate results after each step to see that they are in sigma-neighborhood of the original image.
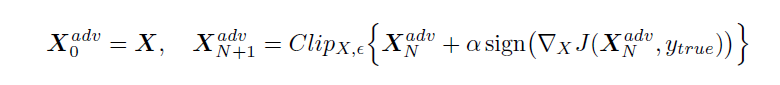
Iteratively Least Likely Class method
3.Iteratively Least Likely Class method: In this method, the adversarial image will be produced which will be classified as a specific desired target class. For desired class we chose the least-likely class according to the prediction of the trained-on input image X.
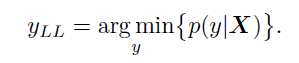
For a well trained classifier, the class to which the image is misclassified is quite different from the real or correct class. For example the image of dog is classified as an airplane.
To make an adversarial image which is misclassified as yLL we maximize log p(yLL|X) by making iterative steps in the direction of sign{ deltaX log p(yLL|X). This last expression equals sign{-deltaX J(X,yLL)} for neural networks with cross entropy loss. Thus we have the following procedure:
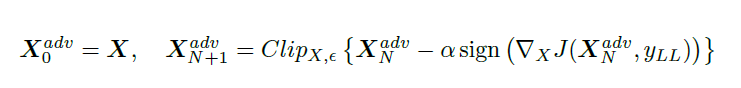
Defense Strategy
1. Adversarial Training
It is the defense technique in which the model is trained on adversarial examples so that it can stand against strong attacks. So basically here, while training is happening, we also generate adversarial images with the attack which we want to defend and we train the model on adversarial images along with the regular images.
The basic idea of adversarial training is to inject adversarial examples into training set, continually generating new examples at every set of training. In the beginning, adversarial training was developed only for small models. In a paper on “Adversarial machine learning at scale” by Alexey Kurakin, Ian J. Goodfellow and Samy bengio, they have showed how to scale it to bigger models such as Imagenet. Batch normalization was recommended for such purpose. The following loss function is used in the paper:
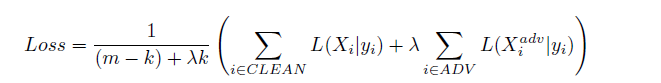
Here, L(X|y) is a loss on a single example X with true class y; m is the total number of training examples in the minibatch; k is number of adversarial examples in the minibatch and lambda is a parameter which controls the relative weight of adversarial examples in the loss.
The following algorithm was used for training of network N:

For experimental details, please refer the paper mentioned above.
2. Defensive distillation
It is the strategy in which the model is trained on output probabilities of different classes rather than hard decisions about which class to output. Here we supply the probabilities through an earlier trained model which was trained on same task using hard class labels.
So, this basically creates a model which can stand and defend in directions the adversary will try to exploit.
Different types of attacks
The following are some of the different types of attack against machine learning:
Evasion Attack
1. Evasion attack: Evasions attacks are the most common type of attack used. Consider the example of hackers and spammers. At the time of threat detection, the evade by making the data of code or mail unclear and confusing such that the threat is not detected. The samples are modified at test time to evade detection such that the data is classified as legitimate.
Poisoning Attack
2. Poisoning attack: When it comes to maintain the accuracy and capabilities of machine learning models through time and the advancements going on, the models are often retrained on data collected during operations. So during this retraining period, the attacker may poison that data on which the model is supposed to be retrained. What this means is that the attacker may smartly design some samples in that data that will lead to compromising the whole learning process. This process can be termed as adversarial contamination.
Privacy Attack (Inference)
3. Privacy attack(Inference): In this type of attack, the attacker tries to gather knowledge about the model and its algorithms, the dataset etc. So what inference here is like if we can get to understand how some program is working or what procedure/algorithm is it using, like in recommender systems of social medias, then we can like change the nature of our searches to see if the results changes the same way. In this type of attack, we can also find out if a particular example is in the dataset of the model (called Membership inference). We can also guess the type of data (Attribute inference) i.e. extracting valuable information about the data.
Trojaning
4. Trojaning: The main aim of this type of attack is to change the behavior of the model in any way possible. Here the attacker have the model and its parameters and tries to retrain the model with changed behavior.
Study References
- ADVERSARIAL MACHINE LEARNING by Ling Huang, Anthony D. Joseph and others. This paper gives the taxonomy for classifying attacks against machine learning. The authors have also explored vulnerabilities of machine leaning algorithms and details about this in their work.
- ADVERSARIAL MACHINE LEARNING AT SCALE by Alexey Kruakin, Ian J. Goodfellow and Samy Bengio. In this paper, the authors have shown how to scale adversarial training to larger models. They found out that multistep attack methods are somewhat less transferable than single-step attack methods. They have also the resolution of “label leaking” effect.
- EVASION ATTACK AGAINST MACHINE LEARNING AT TEST TIME by Battista Biggio, Igino Corona and other. In this paper, the authors have presented an effective gradient based approach which can be exploited to systematically assess the security of popularly used classification algorithms against evasion attacks.
- EXPLAINING VULNERABILITIES TO ADVERSARIAL MACHINE LEARNING THROUGH VISUAL ANALYTICS by Yuxin Ma, Tiankai Xie, Jundong Li and Ross Maciejewski. In this paper, the authors have presented a visual analytics framework which can be used for understanding model vulnerabilities to adversarial attacks. The paper shows details about Data poisoning attack algorithm.
Conclusion
So, in this article at OpenGenus, the basic methodologies regarding adversarial machine learning were explained. We can see why and how adversarial machine learning is such an important topic to explore. In real world, application of adversarial examples can lead to disastrous events like problems with self-driving cars.
On of the prominent defense strategy is Adversarial training. It is very difficult to implement adversarial training for large models because it becomes very costly and also time consuming. Defensive distillation is another useful strategy for making a strong model.