
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Reading time: 30 minutes | Coding time: 10 minutes
Apriori Algorithm is a associative learning algorithm which is generally used in data mining. It follows the principle that people who bought this will also buy this. It analyzes the data present in database and extend the number of data items present in that record. It determines the certain amount of association rules which used to determine the trend in data and based on that data items are added or extended.
Its most used case is Market Basket Analysis. It is beneficial for both customer and seller. It helps customer to buy thing and also increase the sales for seller. It also been used in health care for detection of adverse drug reaction. It also used in recommendation system as it learns from the trend according to user preference and recommend data based on that.
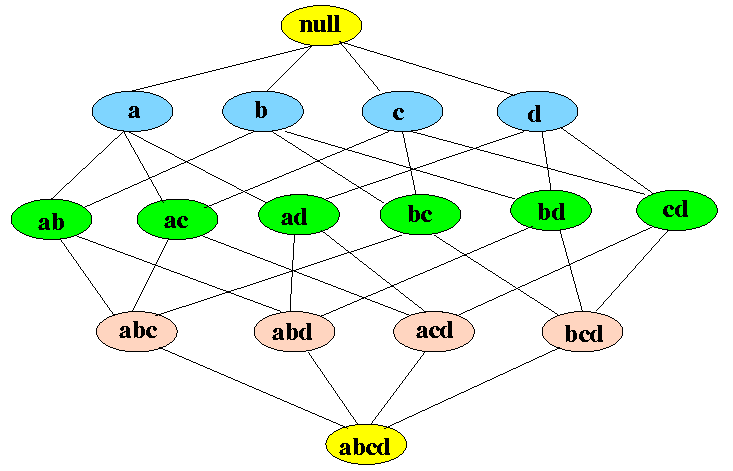
To understand apriori we should understand the association rules.
Association Rules
As discussed above apriori define associative rules. Basis on which it performs its whole process. These rules are generally used to determine the relation between each data item present in database.
- Let I={i1,i2,i3,…,in} are called items.
- D={t1,t2,…,tn} are the transaction.
Every transaction, ti in D has a unique transaction ID, and it consists of a subset of itemsets in I.
An association rule can be intrepreted as A⟶B where A and B are subsets of I(X,Y⊆I), and they have no element in common which means both the events are mutually exclusive i.e., X∩Y = 0.
Association rules generally tells the general trend in the database.
| UserID | Movies Liked |
|---|---|
| 1234 | Movie1, Movie2, Movie3, Movie4 |
| 1235 | Movie1, Movie2 |
| 1236 | Movie1, Movie2, Movie4 |
| 1237 | Movie1, Movie2 |
| 1238 | Movie2, Movie4 |
| 1239 | Movie1, Movie3 |
The above data contain records which specifies the movies liked by each user. After analyzing data certain rules are determined. These rules states that if a person like movie 1 then it will also like movie 2. Same for the case movie 2 and movie 4. Apriori are used to determine these rules and extend the items in the individual records after analyzing from whole data.
Association rules involves calculation of various constraints.
Support
It signifies amount of specific data appear in whole database records. In other words, how many times movie1 appears in other records too.
Support for movie M will be:
Support(M) = User Watchlist containing Movie M / Number of Movies in User Watchlist
Using above example,
support(movie1)= 5/6 = 0.8
It signifies that movie1 is liked by 80% of user
Confidence
It determines a relation between different items. Like referring above example, it signifies the liklihood of movie1 is liked while movie2 is also liked.
Confidence of Movie M1 and M2:
Confidence(M1-->M2) = User Watchlist containing Movie M1 and M2 / User watchlist containing Movie M1
Using above example,
confidence(Movie1--->Movie2)= 4/6 = 0.6
This means 60% of users like both movie1 and movie2
Lift
This signifies the likelihood of the movie1 being liked when movie2 is liked while taking into account the popularity of movie1.
List of Movie M1 and M2 will be:
Lift(M1-->M2) = Confidence(M1-->M2) / Support(M1)
If value is greater than movie2 is oftenly liked by user if they liked movie1
Using above example
lift(movie1--->movie2) = 0.8/0.6 = 1.3
Working of Apriori Algorithm
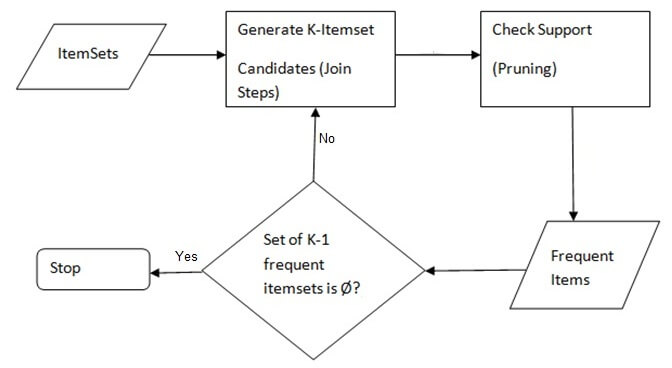
-
It sets a minimum support and confident. A value is set based on which filtering of unnecessary data from dataset. Support and confident value of each data item should more than this minimum values
-
It takes all subsets in transaction having higher support than minimum support. After comparing support and confident values of all data items, items whose values satisfy condition are stored in a location.
-
It take all the rule of these subsets having higher confidence than minimum confidence. Association rules are applied on these data items and will extend items based on that rule
-
It sort the rules by decreasing lift
Go through this image to understand how Apriori - Associative Learning Algorithm works. We have explained it following the image.
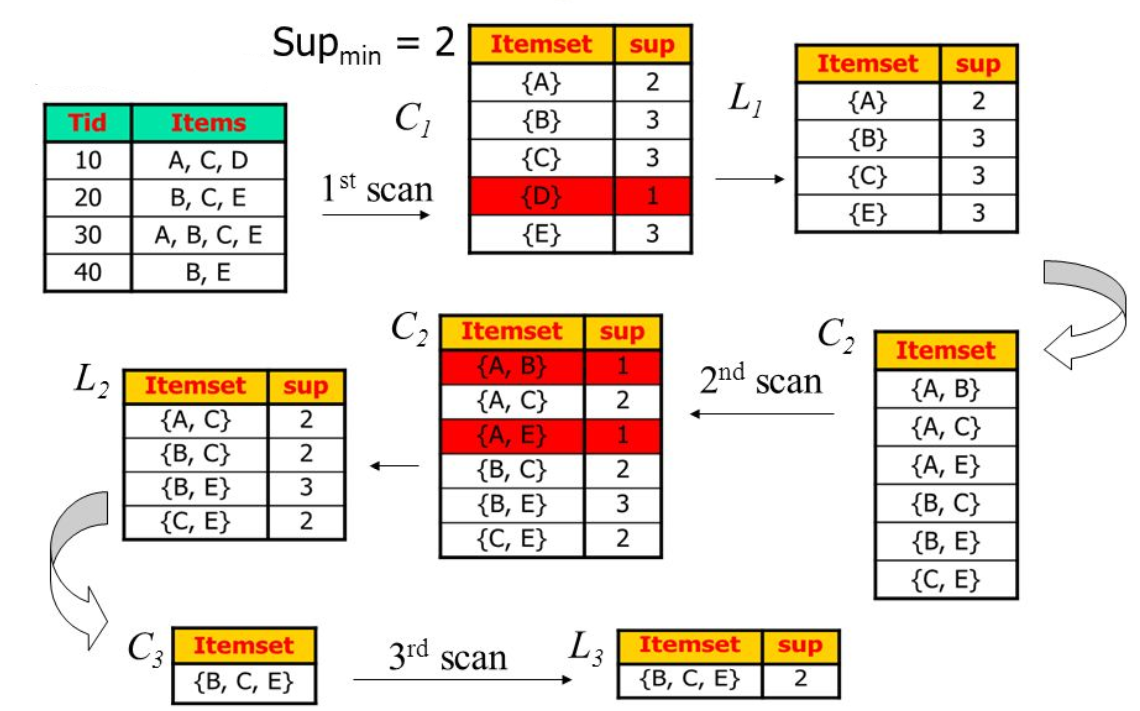
We will first create the frequency of all items present in dataset. We will set a minimum support value which means we will consider only those items which occur in more than 3 records. For this we determine the threshold support. And the support value of each item should be more than threshold value. After that we will make all the possible pairs of items without any repetition. We will create a frequency table of these pair and will only consider those pair whose support value is greater than threshold support. After that we will determine support and confidence of each pair and using the data we will add a item based on the trend in data.
Implementation
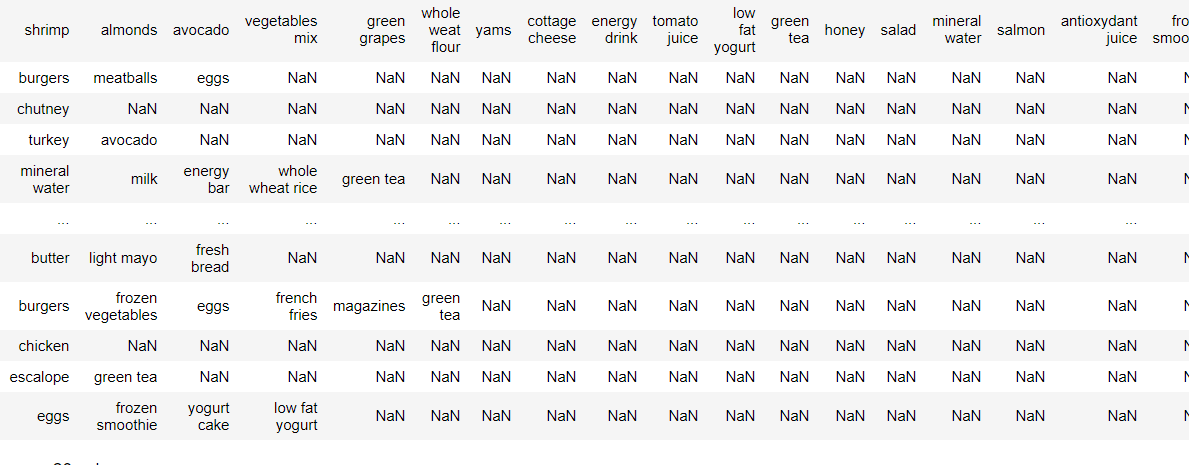
We will use a dataset which contains shopping list of various customer.
The dataset contains record of different market items in basket of each customer. Each record specify the different items chosen by customers. Amount of items varies for each customer. We will try to find relation between items using apriori algorithm.
We will load all the necessary libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
We will import the dataset and transform it into required form for training
dataset = pd.read_csv('Market_Basket_Optimisation.csv', header = None)
transactions = []
for i in range(0, 7501):
transactions.append([str(dataset.values[i,j]) for j in range(0, 20)])
We will train our model for purpose
from apyori import apriori
rules = apriori(transactions, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2)
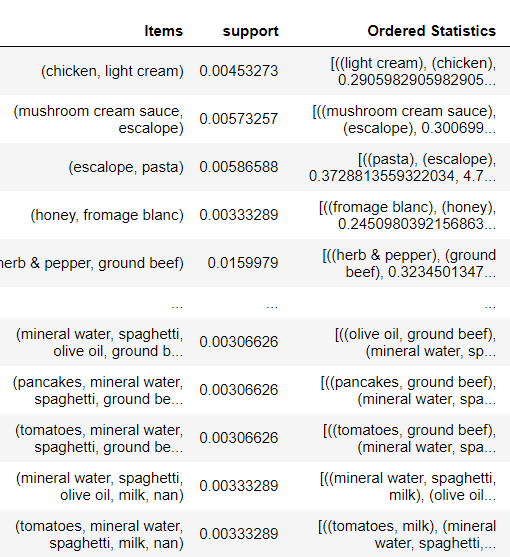
Our results:
Advantages
- It is easy to implement and understand
- It can be applied to large datasets
Limitations
- In some cases large number of rules are generated which makes the problem complex
- Calculation of constraints is time cosuming and expensive as it have to go through whole dataset
With this, you should have a good understanding of Apriori - Associative Learning Algorithm. Enjoy.