
Reading time: 30 minutes | Coding time: 10 minutes
Latent Dirichlet Allocation (LDA) is used as a topic modelling technique that is it can classify text in a document to a particular topic. It uses Dirichlet distribution to find topics for each document model and words for each topic model.
Johann Peter Gustav Lejeune Dirichlet was a German mathematician in the 1800s who contributed widely to the field of modern mathematics. There is a probability distribution named after him 'Dirichlet Distribution' which is the basis of LDA.

How LDA works?
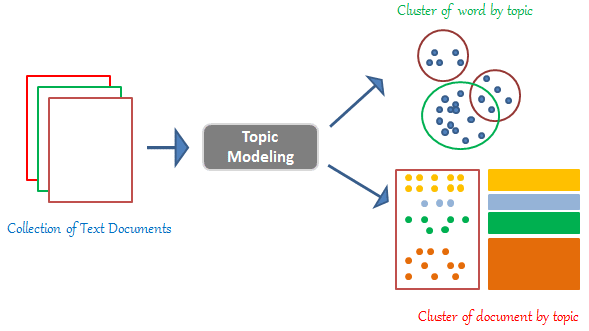
Latent Dirichlet allocation is a technique to map sentences to topics. LDA extracts certain sets of topic according to topic we fed to it. Before generating those topic there are numerous process that are carried out by LDA. Before applying that process we have certain amount of rules, facts that we considered.
Assumptions of LDA for Topic Modelling:
- Documents with similar topics use similar groups of words
- Latent topics can then be found by searching for groups of words that frequently occur togehter in documents across the corpus
- Documents are probability distributions over latent topics which signifies certain document will contain more words of a specific topic.
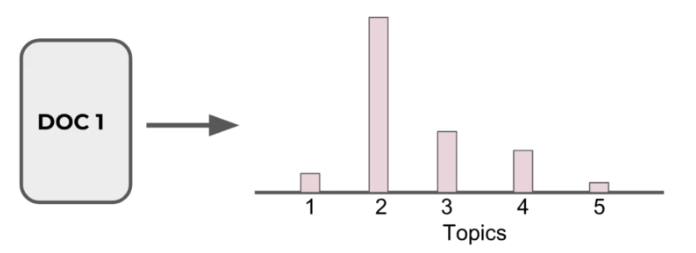
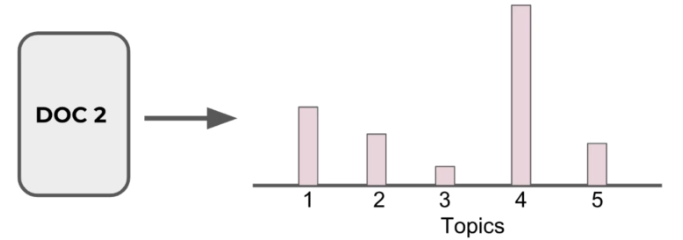
- Topics themselves are probability distribution over words
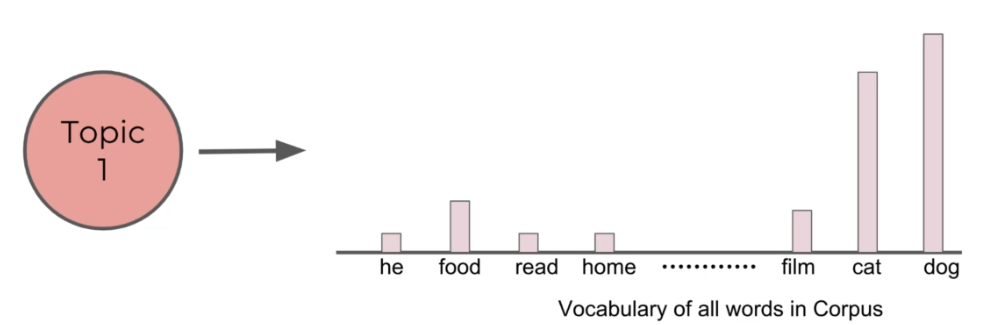
These are the assumptions users must understand before applying LDA.
Explaination through example:
Suppose we have following statements:
- Cristiano Ronaldo and Lionel Messi are both great player of football
- People also admire Neymar and Ramos for their football skills
- USA and China both are powerfull countries
- China is building largest air purifier
- India is also emerging as one of most developing country by promoting football at global scale
With the help of LDA we can generate as sets of topics about which the sentences are. If we take 2 topic sets in consideration then:
- Sentence 1 and Sentence 2 both belong to topic 1
- Sentence 3 and Sentence 4 both belong to topic 2
- Sentence 5 depicts 70% topic 1 and 30% topic 2
LDA states that each documents contains various type of context which relates to various topics. Hence, a document can be represented as collection of various types of topics. Each topic has numerous words with certain range of probabilities. According to LDA each document has its own properties. So LDA assumes certain rules and regulation before producing a document. Like there should be a word limit, a document should have certain amount of words set by user. There also should be diversity in the document content. Document should refer to various context like 60% business, 20% politics, 10% food. Every keyword contained in document related to a topic and that relation can be derieved using multinomial distribution. Example as we discussed before as word related to business domain will have probability of 3/5 and it realtion to politics will be 1/5.
Assuming this model applied on collection of documents, LDA then tries to back track from the documents to find a set of topic that are related to context of documents.
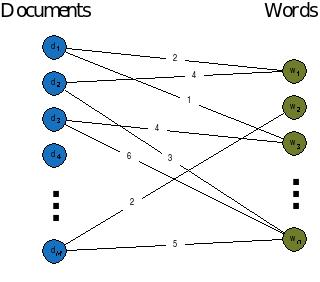
Now we try to understand it full working
Since we have set of documents from a certain dataset or through a random source. We will decide a fixed number of K topics to discover and will use LDA to learn the topic representation of each document and the words associated to each topic.
LDA algorithm cycles through each document and randomly assign each word in document to one of K topic. This random assignment already gives both topic representation of all document and word distribution of all documents and word distribution of all the topics. LDA will iterate over every word in every document to improve these topics. But these representation of topic are not good. So we have to imrove this limitation. For this purpose a formula is created where the main work LDA taken out.
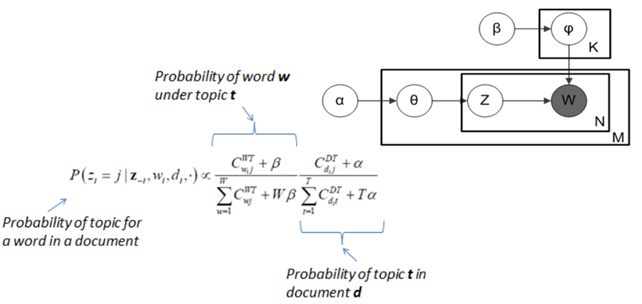
Plate Notation representing LDA model:
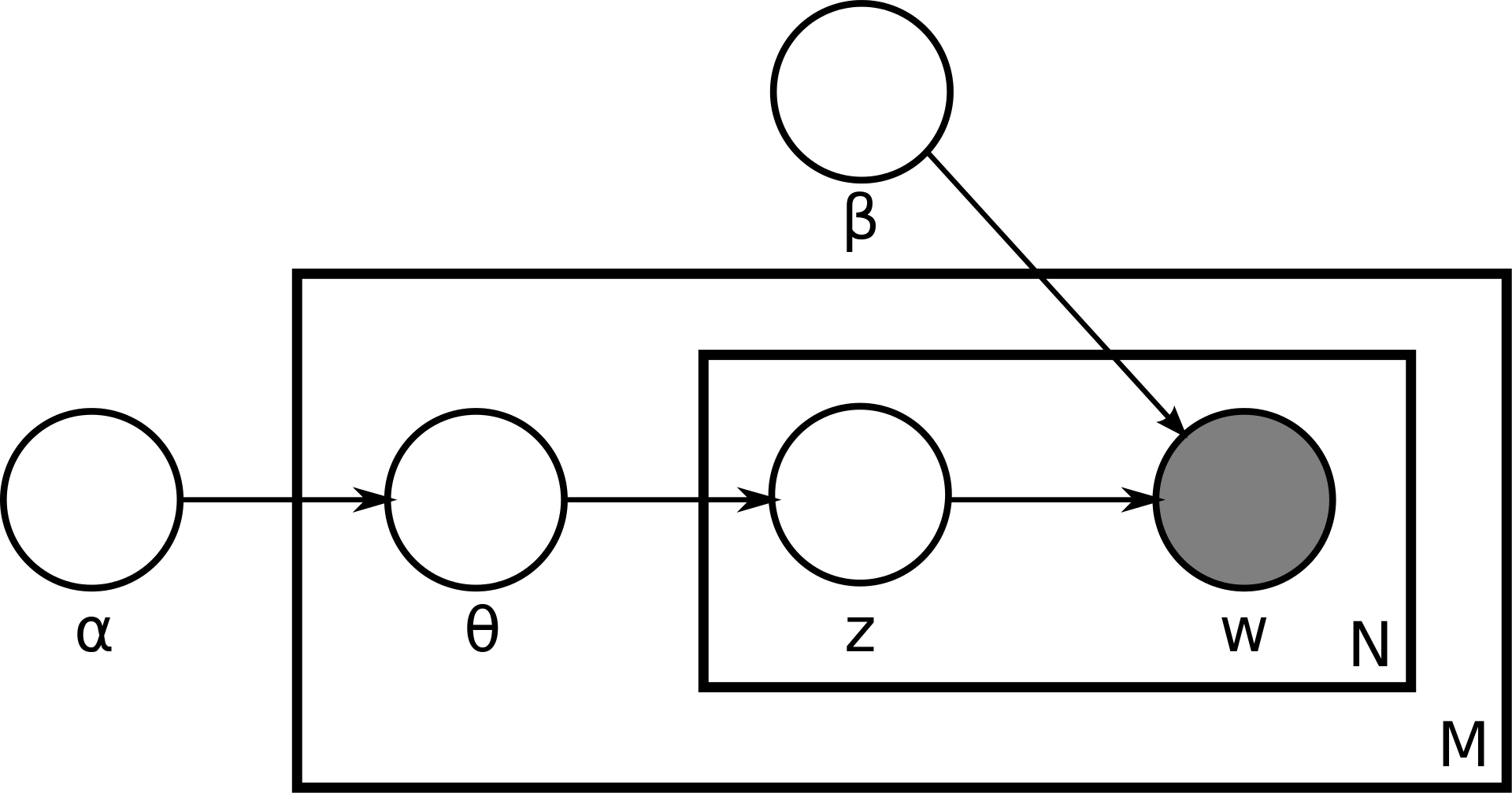
M denotes the number of documents
N is number of words in a given document (document i has {\displaystyle N_{i}}N_{i} words)
α is the parameter of the Dirichlet prior on the per-document topic distributions
β is the parameter of the Dirichlet prior on the per-topic word distribution
theta is the topic distribution for document i
varphi is the word distribution for topic k
z is the topic for the j-th word in document i
w is the specific word.
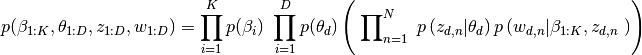
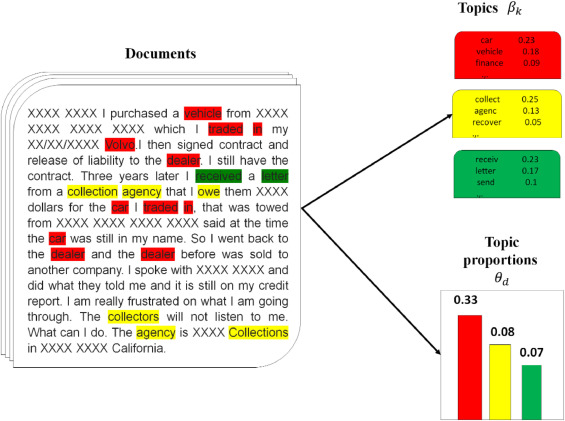
Explaination with simple terms:
For every word in every document and for each Topic T we calculate:
P(Topic T | Document D) = the proportion of words in document d that are currently assign to topic T
P(Word W | Topic T) = the proportion of assignments to topic T over all documents that come from this word W
Reassign w to a new topic where we choose Topic T with probability P(Topic T | Document D) * P(Word W | Topic T).This is essentially that Topic T genrated word w
After repeating the previous step large number of times, we eventually reach a roughly steady state where the assignments are acceptable. At the end we have each document assigned to a topic. We can search for the words that have highest probability of being assigned to a topic.
We ended up output such as
- Document assigned to topic 4
- Most common words (highest probability) for topic 4 ('cat','vet','birds','dog'...)
- It is up to the user to interpret these topics.
Two important notes:
- The users must decide on amount of topics present in the document
- the user must interpret what the topics are
So generally LDA if we have collection of documents we want to genrate a set of topic for topic representation of documents, we can perform it using LDA. As LDA will train from these each document by going through it and assigns words to topics. But this is not a one cycle process. As first cycle LDA randomly assigns words to topics. There is a learning procedure going on here. It will go through each word in each document and applies the formula discussed above. After repeating it about various iteration it generates a set of topic.
Implementaion
We will try to understand LDA more briefly by applying it on a dataset.
The dataset we are using contains information or news fetched from www.npr.org. The dataset contains latest globally. We will implement LDA on that news columns and try to find out most frequent topics around the world and will also assign a topic for future news.
Data Pre-Processing:
import pandas as pd
npr = pd.read_csv('npr.csv')
npr.head()
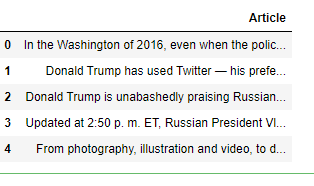
Notice how we don't have the topic of the articles! Let's use LDA to attempt to figure out clusters of the articles.
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_df=0.95, min_df=2, stop_words='english')
dtm = cv.fit_transform(npr['Article'])
Count Vecotrizer: CountVectorizer is a another part of natural language processing and also considered long part of TFIDF. Hence we use tfidf instead of countvectorizer. It counts the number of times a token shows up in the document and uses this value as its weight.We applied CountVectorizer to transform the text data into computer readable form.
-
max_df: float in range [0.0, 1.0] or int, default=1.0
It is used to remove words that appear too frequently. If max_df = 0.50 means "ignore terms that appear in more than 50% of the documents". If max_df = 25 means "ignore terms that appear in more than 25 documents". The default max_df is 1.0, which means "ignore terms that appear in more than 100% of the documents". Thus, the default setting does not ignore any terms. -
min_df: float in range [0.0, 1.0] or int, default=1
It is used to remove words that appear rarely. If min_df = 0.01 means "ignore terms that appear in less than 1% of the documents".If min_df = 5 means "ignore terms that appear in less than 5 documents". The default min_df is 1, which means "ignore terms that appear in less than 1 document". Thus, the default setting does not ignore any terms.
LDA model:
from sklearn.decomposition import LatentDirichletAllocation
LDA = LatentDirichletAllocation(n_components=7,random_state=42)
LDA.fit(dtm)
Showing Stored Words:
len(cv.get_feature_names())
>>>54777
for i in range(10):
random_word_id = random.randint(0,54776)
print(cv.get_feature_names()[random_word_id])
>>>cred
fairly
occupational
temer
tamil
closest
condone
breathes
tendrils
pivot
for i in range(10):
random_word_id = random.randint(0,54776)
print(cv.get_feature_names()[random_word_id])
>>>foremothers
mocoa
ellroy
liron
ally
discouraged
utterance
provo
videgaray
archivist
Showing top words per topic
len(LDA.components_)
>>>7
len(LDA.components_[0])
>>>54777
single_topic = LDA.components_[0]
# Returns the indices that would sort this array.
single_topic.argsort()
# Word least representative of this topic
single_topic[18302]
# Word most representative of this topic
single_topic[42993]
# Top 10 words for this topic:
single_topic.argsort()[-10:]
>>>array([33390, 36310, 21228, 10425, 31464, 8149, 36283, 22673, 42561,
42993], dtype=int64)
top_word_indices = single_topic.argsort()[-10:]
for index in top_word_indices:
print(cv.get_feature_names()[index])
These look like business articles perhaps. We will perform .transform() on our vectorized articles to attach a label number. But before, we view all the topics found.
for index,topic in enumerate(LDA.components_):
print(f'THE TOP 15 WORDS FOR TOPIC #{index}')
print([cv.get_feature_names()[i] for i in topic.argsort()[-15:]])
print('\n')

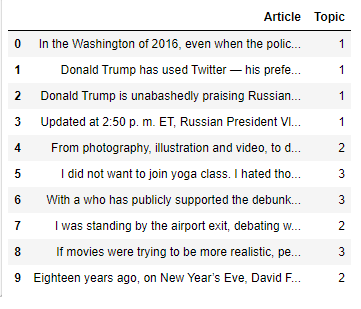
Attaching Discovered Topic Labels to Original Articles
topic_results = LDA.transform(dtm)
npr['Topic'] = topic_results.argmax(axis=1)
Limitations
- There is limit to amount of topics we can generate
- LDA is unable to depict correlations which led to occurence of uncorelated topics
- There is no development of topics over time
- LDA assumes words are exchangeable, sentence structure is not modeled
- Unsupervised (sometimes weak supervision is desirable, e.g. in sentiment analysis)
With this, you have the complete idea of Latent Dirichlet Allocation (LDA). Enjoy.