
Suggest some captions for this image!!

A boy playing with two dogs.
Two black dogs with a boy in snowy weather.
Both of these captions are valid for this image and many more might exist too.We can do this with ease just by looking at this image but can we write a computer program which can suggest a relevant caption after feeding an image to it?
With the recent advancements in deep learning this problem has become very easy provided the required dataset.
To better understand the problem statement, use Caption Bot developed by Microsoft. Upload any image and it will provide a caption for it.
Motivation
Before diving into the analysis of the task let us understand the use cases for this problem.
- We can use it to describe the surrounding to a blind person or person with low vision as they can rely on sound and texts for the description of a scene. Attempts are being made for this application.
- To make Google Image Search more efficient, Automatic Captioning can be done for images and hence search results would also be based on those captions.
- Along with videos from CCTV footages, relevant captioning would also help reduce the some crimes/accidents.
Early Methods for Image Captioning
1) Retrieval Based Image Captioning
The first type of image captioning method that were common in the early times is the Retrieval Based.
We were provided with a query image and the retrival method produces a caption for it through retrieving a sentence or a set of sentences for pre-specified pool of sentences. The caption can either be one if the retrievd sentences or a combination of those retrieved sentences.
A few approaches for image retrieval are as follows:
- Each query image were mapped into meaning space and then it was compared with each of the available descriptions using similarity measures to determine the semantic distance between the image and the available captions. The sentence closest to the image mapping was chosen for the caption.
- Another approach used to map the training images and the textual data into common space, where these training images and its corresponding captions are maximally correlated. And now in the new common space, cosine similarities between the query image and captions are calulated and the top ranked sentence is selected.
The major drawback of these captioning images is that it assumes that there is always a sentence which is apt for the query image. But this assumption is hardly true for any practical cases. Therefore in the other line of researches instead for directly using the top ranked captions, a new one was generated using those retrieved ones. Under certain conditions the retrieved images can also be irrelevant to image contents. Hence, Retrieval based methods have large limitations to their capability to describe images.
2) Template Based Image Captioning
In early image captioning works, another model which was used is Template Based. In this method, captions were generated via very constrained process both syntactically and semantically. We used to have a fixed templates having a number of fixed blank slots to generate captions. The different attributes, features, actions and surroundings of the objects are detected firstly and then these extractions are used to fill in the blanks of those fixed templates. Thereby making the template now relevant to the image provided.
A few of template based approaches are as follows:
- One approach used triplet of a scene of object or an action to fill in the gaps of templates. Object detection algorithms were first applied to estimate objects and the scenes followed by application of pretrained language models to find out verbs, prepositions and scenes to produce a meaningful sentence.
- Another method uses Conditional Random Field (CRF), to render image contents. The nodes of the graphs represented objects, its attributes and the spatial relationship among them. These are used to fill gaps in the templates and thus are used to make the templates complete describing the image.
Template Based models generate grammatically correct sentences and the descriptions obtained by these methods are much more relevant to images than the Retrieval models. However its major disadvantages are such that this approach uses predefined templates and also can't generate variable length captions. Also compared to human hand-written captions, these rigid templates make the generated descriptions less natural.
All the above mentioned approaches and methods were basically some form of hard coded rule based description generation. Infact many didn't consider it as a generation task rather took it as a ranking task meaning given many descriptions(training set), we needed to rank these descriptions on basis of maximum correlation and thus produce the result. But these performed fairly poorly when dealing with unseen objects and also as training size grew larger it became difficult to handle these large number of description and hence was not space friendly. Thus came Neural Network based approaches.
3) Deep Learning Based Image Captioning
With the recent advancements in deep learning specially in Computer Vision and Natural Language Processing, recent works have inclined towards deep neural networks for automatic image captioning.
We have discussed deep learning methods in detail below as they are used to produce state of art results.
Tech Stack
For the purpose of understanding and implementing this task at hand one must have experience with topics like Computer Vision , Language Modelling , MLP( Multi-layered perceptrons) , Transfer Learning , Text preprocessng , Keras , CNN (Convolution neural Networks), CNN (Convolution Neural Networks) etc.
The purpose of this blog is to explain the general idea and the techniques used to solve this problem.
General Idea
Image Captioning is the process to generate some describe a image using some text. This task involves both Natural Language Processing as well as Computer Vision for generating relevant captions for images.
The two main components our image captioning model depends on are a CNN and an RNN.
Hence our captioning model is about how we integrate our two most important attributes i.e
- CNN's -> For preserving the image features and it's information.
- RNN's -> For dealing with any kind of sequential data and for generating sequence of words.
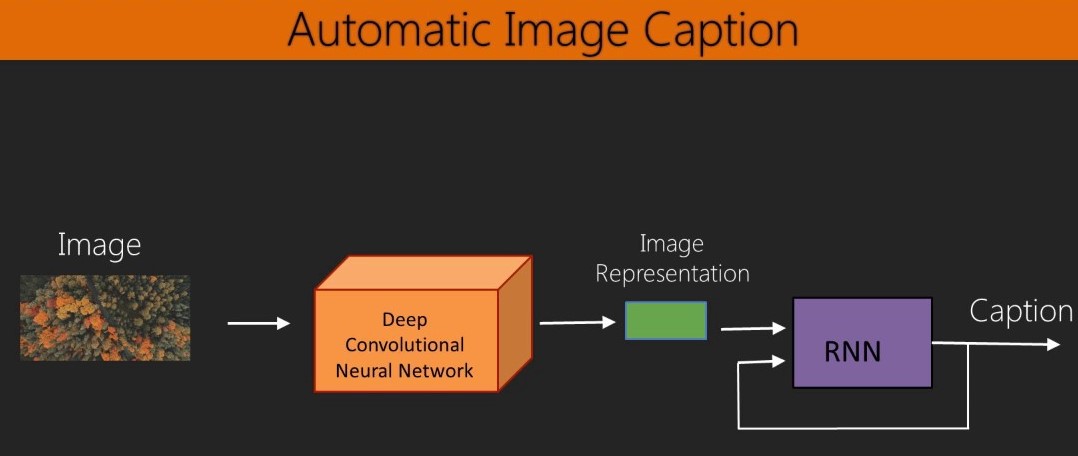
Above picture gives us a brief overview of how those two distinct components combine together to produce a meaningful result.
Captions Preprocessing
No model deals directly with raw input English words. Hence, we will first need to preprocess the captions available so that we can make it model friendly for the training purpose.
Prediction of the entire model doesn't happens, rather it is done word by word. So we need to convert the words to suitable format.
Tokenizing Captions
Tokenizations means converting out corpus (or captions) into list of integers.
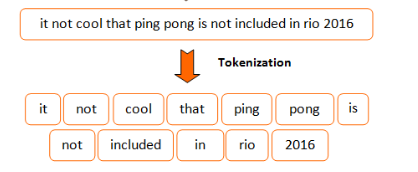
First, iterate through all the training captions and map each unique word to an index. This dictionary is also known as vocabulary.
Now this list of tokens is now turned into integers using the vocabulary and mapping them to their corresponding integer index.
RNN model predicts the next word given the previously predicted words.Thus it can go on infinitely. To avoid this we need some kind of starting and ending token to teach our model to end caption after predicting sufficient words.
For this purpose we attach < start token > and < end token > at the beginning and at end of each caption.
Network Topology
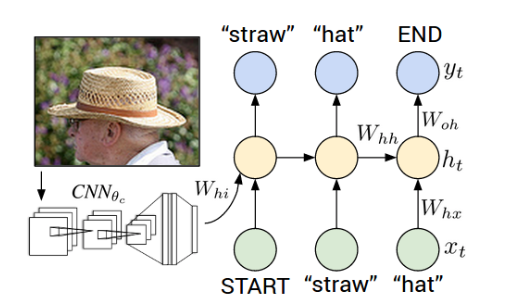
CNN acts as the encoder for our network and provides necessary dense image features to the next part of our network topology i.e the RNN (or LSTM) which is the decoder for our topology.
Encoder (Image Feature Exraction)
This part of the topology's function is to extract features from the image. For this purpose we can either train a CNN model from scratch or use pretrained model for feature extraction. Function of encoder is not to classify the images but to get a fixed length of dense informative vector for each of the image.
This part is known as Automatic Feature Engineering
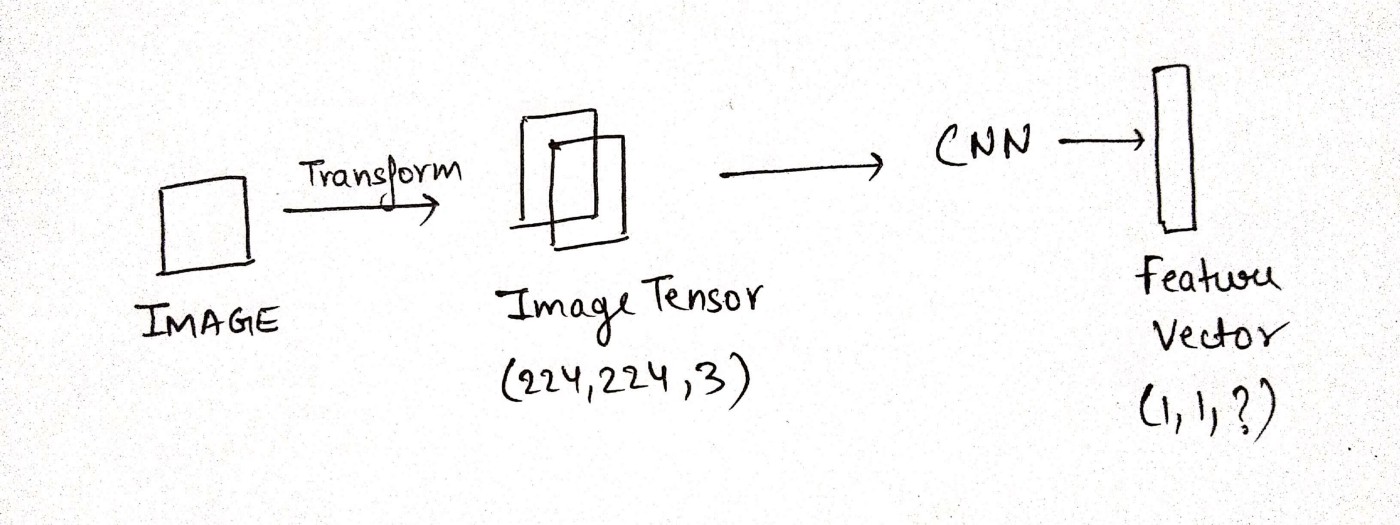
Decoder
The decoder is the RNN network and it's function is to perform language modelling up to the word level. The output of the encoder (CNN) is connected to the input of the decoder function.
We should note that the captions are the target variable and our model is learning to predict the target variable during training.
While training , decoder accepts the dense vectorized form of the image as well as the corresponding caption (not in the raw format but with text preprocessing like tokenization , mapping words to vaocab indices etc) and our model learns to predict the next word in the sequence given the partial caption.
Hence, RNN now has two responsibilities :
- Recollect the spatial features from the dense input vector.
- Predict the next word in the sequence.
Model Architecture
Since our input consists of two parts i.e the input image vector and the partial caption generated , we can't simply merge out two different inputs using Keras Sequential API. For this purpose we use a Functional API used to create MERGE MODELS.
Merge Model
In 'Merge Models' the image vector is left out of the RNN sub-cell and hence RNN deals purely with the linguistic info. After the prefix has been vectorized, it is merged with the image vector in a separate ‘multi-model layer’ which comes after the RNN sub-network.
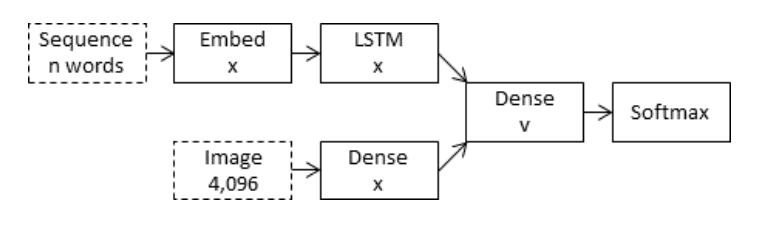
Training
For the first time step , we give the output of the last hidden layer of the CNN encoder as input.
We set X1 = < start token > and the desired output Y1 = first word in caption.
Similarly we set X2 = first word of caption and expect output as Y2 = second word of the caption and thus this goes on till last word i.e Xn = last word of caption and expect our model to predict YT = < end token >.
During training we feed correct input to the decoder even if our decoder made mistake in predicting the correct next word.
Prediction
The vectorized image is provided as the input to decoder in the first time step.
Set x1 = < start token >, compute the distribution over all possible words and then consider the word with the highest probability (argmax).
This process is repeated untill the end token i.e < end token > is predicted by the model.
During prediction phase, the output at time T is fed as input for the next time step i.e. T+1 for generation of the next word in sequence.
This NIC(Neural Image Caption) based approaches produced state-of-art results when it's performance was test on different datasets. It made way for neural networks to explore more in this literature.
Datasets
For this project we have some nice datasets like
- Flickr_8k (containing 8k images with captions) can be downloaded from Kaggle.
- Flickr_30k (containing 30k images)
- MSCOCO (containing 180k images) etc.
External Links
- Caption Bot developed by MICROSOFT.
- ALIPR.com for real-time image captioning.
- Horus by NVIDIA A life-changer for the blind
Further reading
This section provides more indepth research papers if you are looking to go deeper into this domain.
We have two options for feeding the image info to our RNN model either by directly feeding it to our RNN model(INJECT mechanism) or in a layer following the RNN conditioning the linguistic information(MERGE feature). This paper compares these two appraoches and suggests better one for practical purposes.
How shall we view our RNN model, as an generator or as an encoder? This paper helps you explore both the factions and discovers that RNN can better be viewed as an encoder rather than generator.
- Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures , 2016.
This paper provides a detailed review of different existing models, comparing their advantages and disadvantages. It also provides benchmark for datasets and evaluation measures. Further it also guides for the future directions in the area of automatic image captioning.
With this article at OpenGenus, we have now got the basic idea about how Image Captioning is done, general techniques used, model architecture, training and its prediction.
Hope you enjoyed reading this article!!