
BERT (Bidirectional Encoder Representations from Transformers) is a recent paper published by researchers at Google AI Language. It is pre-trained on huge, unlabeled text data (without any genuine training objective). BERT makes use of Transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text.
To get the indepth understanding of BERT model, please go ahead on this link which will help you understand it in depth.
BERT base vs BERT large
BERT is based on stacked layers of encoders. The difference between BERT base and BERT large is on the number of encoder layers. BERT base model has 12 encoder layers stacked on top of each other whereas BERT large has 24 layers of encoders stacked on top of each other.
The image below shows the architecture of a single encoder.
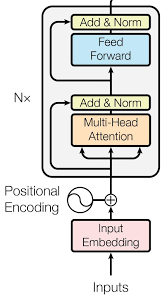
So we can take encoder layers and stack it on top of each other and we can form our own modified BERT based on different number of encoder layers.
The image below shows standard two different BERT, BERT base and BERT large
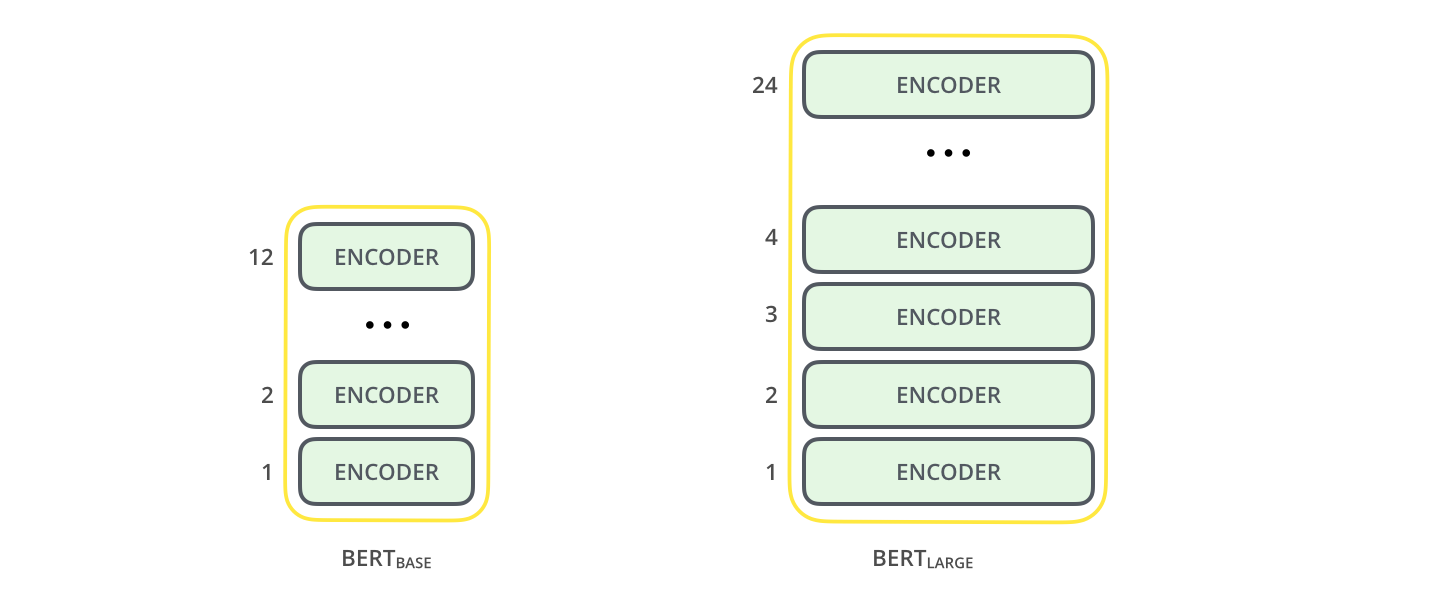
As the number of layers is BERT large is increased so does the number of parameters (weights) and number of attention heads increases. BERT base has a total of 12 attention heads (lets each token in input to focus on other tokes) and 110 million parameters. Whereas BERT large has 16 attention heads with 340 million parameters. BERT base has 768 hidden layers whereas BERT large has 1024 hidden layers.
Results
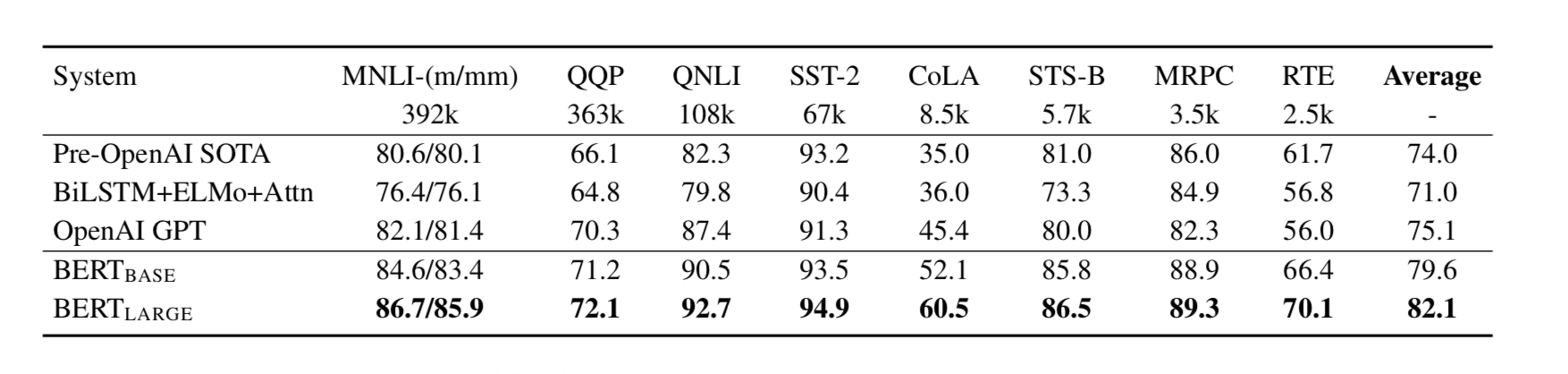
As we can see in the image above, the results of GLUE benchmarks show us that the BERT performs better than the other models. And BERT large increases the performace of BERT base further.
The image below shows SWAG Dev and test accuracy. BERT beats other models where BERT large performs better than BERT base.
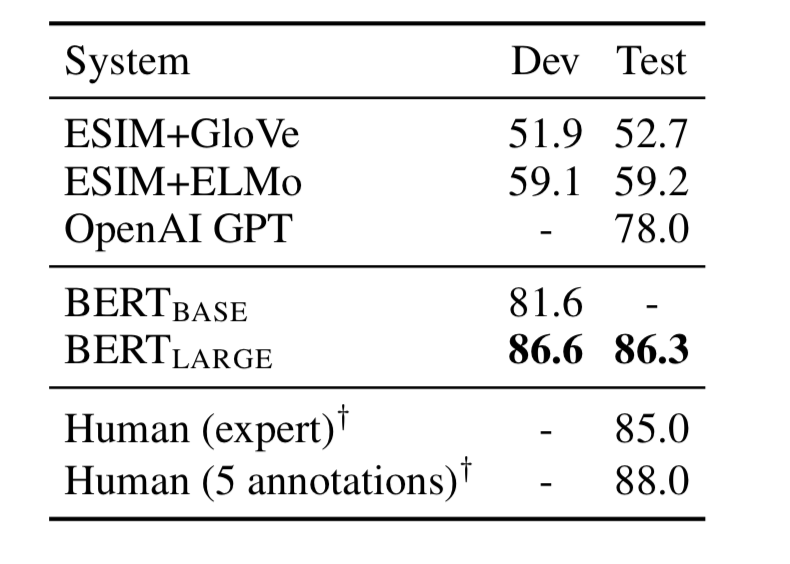
These results also cements the claim that increasing the model size would lead to the improvement in results.
Although the larger model performs better, fine tuning and training such a model is difficult and requires a lot of horse-power. For example, BERT-base was trained on 4 cloud TPUs for 4 days and BERT-large was trained on 16 TPUs for 4 days. Also, BERT large is more memory hungry than BERT base.