
We will be talking about a paper titled "Can Machine Learning Be Secure?" by Marco Barreno, Blaine Nelson and others. This paper basically answers the question title itself presents. The paper involves a taxonomy of types of attacks on Machine learning, defense strategies and more.
Introduction
In the modern world, machine learning is finding its application in many important fields. One example is of network Intrusion Detection System (IDS). Machine learning models can be trained on traffic intrusion detection and hence show how useful it can be. But there are always adversaries present that can manipulate and mess with the model.
The paper explores some important question like:
Can the adversary manipulate a learning system to permit a specific attack?
Can an adversary degrade the performance of a learning system to the extent that administrators are forced to disable the system?
What defenses exist against adversaries manipulating learning systems?
More generally, what is the potential impact from a security standpoint of using machine learning on a system?
What is Machine learning?
A machine learning system is responsible for finding a hypothesis function which maps events into different classes. Consider the example of email. Based on the content and other details, the system is supposed to classify it either spam or not spam.
Attacks
The Attack Model
There are three basic axes that define a space of attack:
- Influence
i. Causative: In these types of attacks, the adversary tries to mess with the machine learning model through the training data. Training is the time when the ML models are quite vulnerable as during this time only these models are supposed to learn what to do.
ii. Exploratory: In exploratory attack, the adversary aims to gather information about the model or we can say explore the model. There are many techniques to do so like offline analysis, probing the learner etc. - Specificity
i. Targeted: Targeted attacks are like when the adversary tries to focus on some particular part of the model that can be useful in causing the model to misclassify. The particular target can be a fixed set of points or some separate value etc.
ii. Indiscriminate: In this type of attack, the adversary focuses on more of a class of points. Unlike targeted attack, this type is more general. Like the adversary focuses on “any false positive” etc. - Security Violation
i. Integrity: In this type of attack, the integrity of the model is compromised i.e. the points installed by the adversary to misguide the model are classified normal by the model. They basically serve as the backdoor to the model.
ii. Availability: This attack results on model being declared useless and improper. The model provides large number of incorrect classifications such that the predictions becomes not trustable.
Consider the following table:
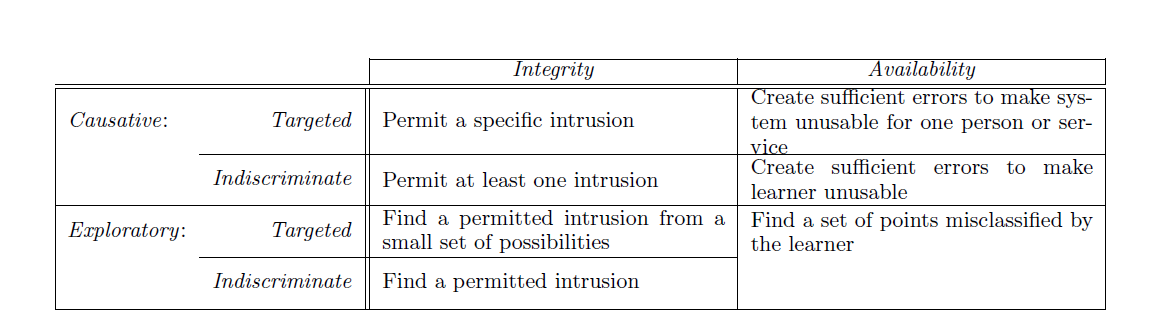
As we have learned that causative attacks messes with the training process, so we can say that the adversary have some control over the training process. If we see the example where due to the adversary attack, the IDS (Intrusion Detection System) misclassifies the intrusion point i.e. the exploit point is not marked as intrusion, so this is called the causative intrusion attack. From the table we can see that there can be two types of the above attack, targeted causative integrity attack and indiscriminate causative integrity attack. The difference is that in targeted, a particular exploit is searched and in the other the system looks for any exploit. In causative availability attack, the system is considered compromised. As too many misclassifications are there, the system is declared unusable. In targeted attack here, the focus is on a particular service and in indiscriminate, focus is on any service.
Previously, we have learned that exploratory attacks focus on information about the data and system rather than focusing on training process. Now, in Exploratory integrity attack, the focus on finding intrusions that are not recognized by the learner. So, in targeted attack, specific intrusions are searched for and in indiscriminate any unrecognized intrusions are searched. In Exploratory availability attack, focus is on finding a set of points or intrusions that are misclassified by the learner.
Online Learning
Online learning is where the learner is continuously trained. It helps the learner to adapt to changing conditions i.e. updating is done with time. Online learning can lead to causative attack as when the model is being trained or updated with recent events, it gives the adversary the chance to mess with the training data and hence make the model less credible. Online learning basically involves changes in prediction function over time. So, the adversary can include the required changes in that time. Gradual causative attacks are not easily detected.
Defenses
Let is now discuss some defenses against these attacks.
Robustness
The robustness of the model can be increased by putting a constrain on the class of prediction functions. This can be done by using Regularization. If the basic function can be given as:
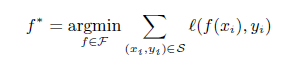
Then using regularization, the equation can updated as follows:
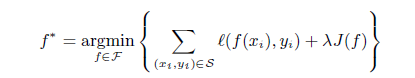
Here the term lambdaxJ(f) is added which penalizes the hypothesis. The lambda adjusts the trade-off. Now, adding constrain helps the defense in two ways. The first one is like it helps in removing the weak points or the complexities that can be used by the adversary. It is like removing the obstacles from a path.
The second help is that the learning process is improved by the prior distribution. As the model learns about the domain in a deep and good way, the model does not have to rely on exact data fitting and hence the adversary cannot mess in that place.
Detecting Attacks
One of the most helpful way to maintain the integrity of the machine learning model is by detecting the attacks. But it is not easy to detect any attack.
There is a way using which the causative attacks can be detected and that is by using a special test set. In this special set, the trainer itself includes some intrusion points, and other points that are similar to them. Now when the model is trained and a large number of these intrusion points are misclassified, this will indicate that the model is not credible and hence not usable.
Exploratory attacks can be detected using some specific algorithms. These algorithms can help us detect probing etc.
If the attacks are discovered, then it will help learner get the knowledge about the methods used by the adversary. This can help in strengthening the defense strategies. If the training data is exposed to the adversary, the best thing to done by the learner is to ignore this data.
Disinformation
Sometimes, the learner might be able to get the information about the data that is seen by the adversary. So, the learner can alter that data to confuse the adversary. This strategy is called disinformation. In this case, this can be described as causative attack on the adversary.
The learner can confuse the adversary by making it believe that a particular intrusion is not included in the training set. Now this placed intrusion point will help the learner detect the presence of an attack by letting the adversary to reveal itself. This is called honeypot.
Randomization of Targeted Attacks
There is a way using which the learner can deal with targeted attacks as these attacks focus on a particular set of points. Randomization is the answer to that. If randomization is used on points, then it becomes difficult for the adversary to move decision boundary past the targeted points and hence it becomes difficult for adversary to attack the learner.
Summary of Defenses
To summarize the defenses, consider the following table:
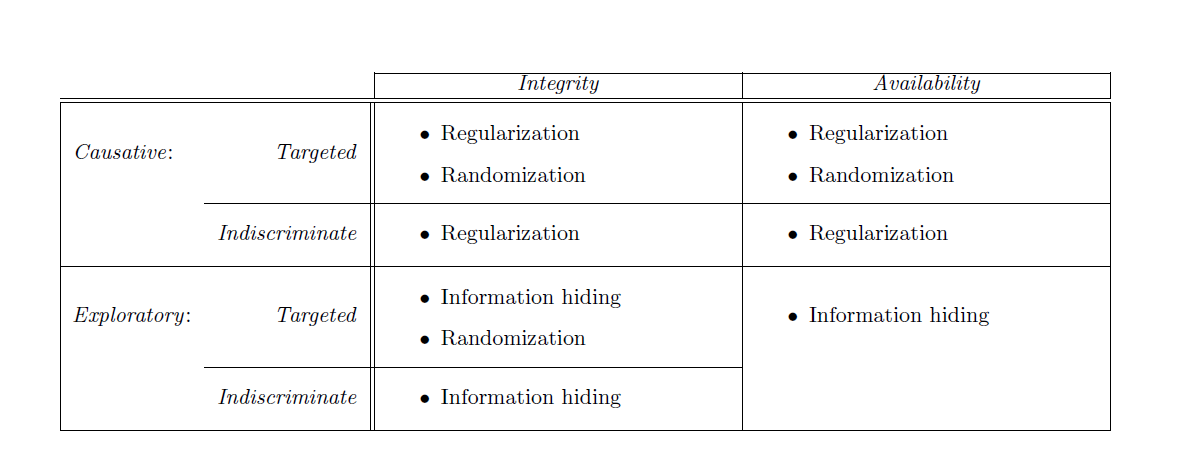
From the table we can see that for causative integrity and availability attacks, Regularization can be the helpful strategy. Regularization basically helps in penalizing the prediction equations.
For exploratory integrity and availability attacks, Information hiding is the best step. Information hiding is basically dealing with essential information. The defenses and attacks both depend upon the details of the machine learning algorithms available to the adversary. These essential details include choice of model, training data, information about decision boundary etc. So, hiding such some essential details can be very useful in helping the system deal with the attacks of adversaries.
Theoretical Results
In the paper, the authors have presented an analytical model that examines a causative attack to manipulate a naïve learning algorithm. For the model details and results, please refer the paper itself.
Conclusion
To conclude, lets jump back to the questions that were raised initially by the paper and try to provide answers to them.
1. Can the adversary manipulate a learning system to permit attack?
So, we have seen that the adversary can possibly mess with the training data to make the model less credible. These are called the causative attacks. There are also defense strategies against them like detecting the causative attacks using special test set etc.
2. Can an adversary degrade the performance of a learning system to the extent that system administrators are forces to disable the IDS?
The adversary might be able to degrade the performance of a learning system such that the admin is forced to disable the Intrusion detection system (IDS). There are attacks that can lead to compromising the integrity of the system.
3. What defenses exist against adversaries manipulating learning systems?
In the earlies sections, we have seen many defense strategies like increasing the robustness of the system, working on ways to detect the attacks, disinformation, randomization and more.
4. More generally, what is the potential impact from a security standpoint of using machine learning on a system? Can an attacker exploit properties of the machine learning technique to disrupt the system?
As we know machine learning has found its way into many areas where the work is carried out by the ML algorithm. But when it comes to seeing this from the security standpoint, the system gets prone to getting disrupted as there are different ways or attack types through which the adversary can mess up the machine learning technique and hence the entire system.
Research Directions
For the security of the machine learning inclusion in different fields of current world, the following the some research directions proposed in this paper.
- Information: Information secrecy is very important in any field. What data to hide from adversary? If the adversary has access to all the data, are all exploratory attacks trivial? If the adversary has no information, what attacks are possible?
- Arms race: Can we avoid arms races in online learning systems? Arms races have occurred in spam filters. Can game theory suggest a strategy for secure re-training?
- Quantitative measurement: Can we measure the effects of attacks? Such information
would allow comparison of the security performance of learning algorithms. We could calculate risk based on probability and damage assessments of attacks. - Security proofs: Can we bound the amount of information leaked by the learner? If so, we can bound the accuracy of the adversary’s approximation of the learner’s current state.
- Detecting adversaries: Attacks introduce potentially detectable side effects such as drift, unusual patterns in the data observed by the learner, etc. These attacks are more pronounced in online learning. When do these side effects reveal the adversary’s attack?