
In this article, we will have a simplified view of the research paper "Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images" by Anh et al. Here, we will observe how the neural networks can be fooled by simply modifying certain image fed into the input. In fact, these models recognize images with high confidence in cases where the same images are completely unrecognizable for humans.
Our article demonstrates some techniques how such examples are created. This is a fundamentally important paper in the domain of Machine Learning and has over 1590 citations as of 2020 (being published in 2015). A more interesting thing is that these same models can wrongly recognize images which are valid for humans. This article covers the idea:
Fool Deep Neural Networks by changing one pixelThis paper (by Goodfellow) summarizes the ideas of Adversarial examples
Explaining and Harnessing Adversarial examples by Ian Goodfellow
Introduction
Deep Neural Networks have hierarchial layers which are used to identify the patterns related to a particular group. Current state of art techniques expecially in computer vision have humangous developement. Often the question arises what would be the gap between or the difference between huan vision and computer vision. But a recent study reveils that changing an originally correctly classified image slightly can cause the model to classify it as somethingelse. For example, an image initially labelled as lion may be misclassified into something else. In this papaer, we will look at another way where images which are completely inrecognisable to humans will be recognized by DNN models with very high accuracy. Such iages are produced by evolutionary algorithms which optimize the iages to fool the DNN models. The overview of the explanation is given in the below images.
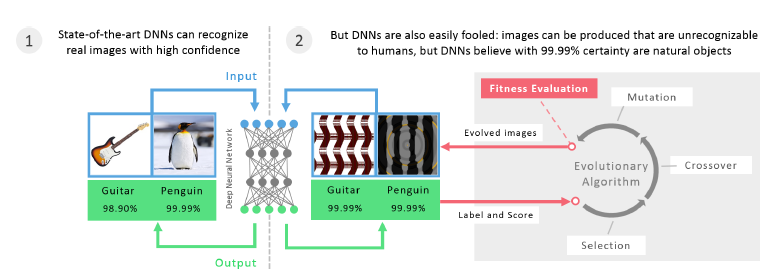
Methods
In order to find the false positives (number of unrecognizable images labelled as positive), we need a high performance DNN model. We have chosen AlexNet DNN provided by caffe software package which is trained on 1.2 million image ILSVRC 2012 ImageNet dataset. We chose AlexNet because it is widely known and a trained DNN similar to it is publicly available. Throughout this paper, we refer to this model as “ImageNet DNN”
In order to check if the results hold true for other architectures also, we use LeNet model trained on MNIST dataset. We use sigmoid activation layers and the error rate is 0.94%. We refer to this model as "MNIST DNN".
Generating Images
The modified images are generated by Evolutionary Algorithms. These algorithms works on the basis of Darwin's Evolutionary theory. It contains population of images which alternatively face selection and random mutations based on the fitness function. In other words, the images with highest probability will be selected and will undergo changes.
Traditional algorithms performs well for single class classification problems. For example, one class of ImageNet dataset. But for a multi class problem, we cannot use it. We instead use a multi dimensional archive of phenotypic elites MAP - Elites which allows us to simultaneous evolve data which performs well on multu classes. MAP - elites works by keeping the best fit among each class as objective and performing multiple iterations on the population randomly. In other words, the best fit fit images are mutated randomly and replaced with a better fit in the population if exists. Thus it continuously replaces the objective data if the mutation decreases the fitness of the data. Here fitness refers to the probability of occurance of a particular image in the population.
We test EAs with two different types of encoding - direct and indirect. In case of direct encoding, there exists one greyscale integer for each of 28 x 28 pixels of MNIST data and three integer for each of the 256 x 256 pixels of ImageNet data. These images are intialized with random noise between 0 and 255. These are then randomly mutated starting at the rate of 0.1 and then continuously decreasing at the rate of 0.5 for every 1000 generations.
An indirect encoding produces regular images which contains conpressible patterns like symmetry, repetition etc. The indirect encoding here is a Compositional Pattern Producing Network (CPPN) which can evolve complex, pattern producing images that resemples natural images. One important point to note is that images produced with can be identified by both numans and DNN. PicBreeder is a website which uses this kind of algorithm and generates images. A sample of these generated images are given below.

A CPPN is similar to an Artificial Neural network and it takes x and y pixel values of the images and produces greyscale values in case of MNIST data or a tuple of HSV color values in case of ImageNet data. The network contains numerous nodes which contains different activation functions. For example a node with gaussian function procues left side symmetry, a node with sine function produces top down repetition. The rate and the number of evolution determines the topology, weight and activation layers of each CPPN in the network. Similar to an ANN, a CPPN starts with minimal or no hidden nodel in the beginning to extract simple feature and generate evolution.
Results
1. Evolving Irregular Images to match MNIST
At first, we evolve LeNet to generate a population of images which shows high confidence that the images are hand written digit but they are not at all recognizable by humans. Multiple evolutions on the dataset produces a set of images which fools the DNN model with 99.99% confidence. Within 40 generation, we are ablee to achieve this. The sample images generated are shown below.

2. Evolving regular Images to match MNIST
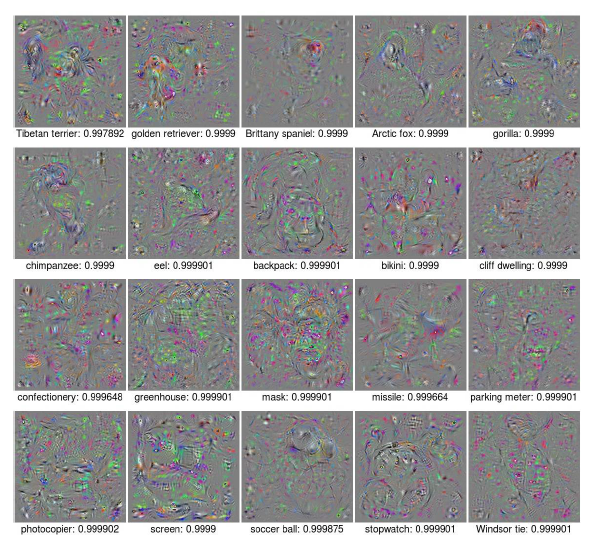
As CPPNs have the capacity to generate regular images which are recognizable by human eyes other than the white noises, we now generate images using indirect encoding. Even after a few generations, the model is able to generate images which can fool a DNN model to believe it as hand written digits with high confidence. But they can be easily recognised by a human as non MNIST. By 200 generations, we are able to achieve a median accuracy of 99.99%. Certain features such as horizondal line, vertical lines are becoming indicative features of certain images. The sample images genearted are shown below.
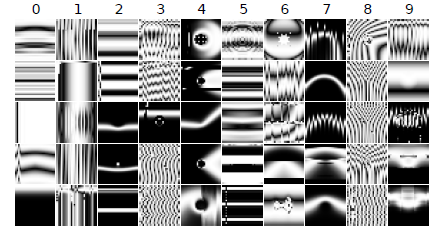
3. Evolving irregular images to match ImageNet
It is possible to doubt that as MNIST data is very small, it can be fooled due to the fact of overfitting also. But a ImageNet data with 1.3 million natural images falling under 1000 classes will be difficult to fool. So, now we work on that hypothesis. But the confidence scores generated by irregular images were not satisfactory. It falied to achieve high confidence even after 20000 generations. The confidence score was just 21.59%. However, it was able to generate images for 45 such classes with 99% accuracy. The result generated after 5 iterations are given below.
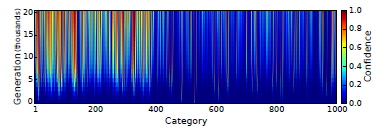
4. Evolving regular images to match ImageNet
Now, with CPPN enabled indirect encoding, the model really works better. After 5000 runs, it was able to generate images with confidence of 88.11% whih is very much better than that of direct encoding in ImageNet. Also, the it works well for many of the classes. The results are shown below.
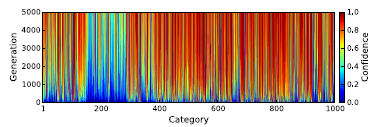
A actual human will not be able to find whcih class it belongs to. But it has certain recognizable patterns such as fot a starfish, it has blue background of sea, for a baseball, it has patterns of red stiching etc. This is because, the CPPN has to generate images which are unique to a particular class, only then it will be able to fool the DNN models. Many of the CPPN generated images has repetitive patterns. We then ablated certain repetitive features to see any changes in the performance. Ablation means removing certain repetitive features. It is shown that ablation leads to decrease in performance. This helps us understand that repetitive features lead us to believe that it increases the accuracy score. It also suggests that DNNs learn more from start and mid layers rather than the global features. That is the reason the performance drops when easily recognizable repetitive features are removed. The below image shows the drop in accuracy with removal of repetitive features.
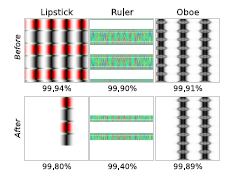
The classes which consisted of images of dogs and cats produced very low performance scores. But obviously, they form the majority of the dataset. There are two explanations for this. One is that as the dataset is huge, chances of overfitting is less and cannot be fooled. The other one is that as the size of the dataset is huge, it is very difficult to identify specific patterns for a specific classes. The sample images are shown below.

5. Images that fool one DNN generalize to others
The above observations convince that DNNs identify specific features to classify images. But we are not sure that if the results changes for different DNNs. Thus we conduct experiments on different test cases. In one, two different DNNs are trained on same architecture and data but with different random intialization. In another test case, the two different DNNs are trained on different architectures of same dataset. The experiment is performed on both MNIST and ImageNet datasets. The result obtained performed with 99% confidence on both the test cases. Thus it proves that the DNNs obtain generalized features and are not specific to certain models alone.
6. Training networks to recognize fooling iages
It can also be said that if the evolved images are found fooled images, why can the model learn from this in the next step. Thus we perform another experiment. Here, we during the first process, the evolution occurs and the fooled images are obatined and classified as another class. This new dataset is inturn fed into another network. This experiment is performed on both MNIST and ImageNet datasets. It is found that it produces error of 20 and 2000 for MNIST and ImageNet respectively.
7. Training MNIST DNNs with fooling images
In order to make the newly generated category have same nuber of images as other categories, we add 6000 images to the training obtained from 300 evolutionary runs. Then for each additional iteration, we add 1000 images to the dataset. It is made sure that the ratio of all images remains constant. But the evolution still produces unreconizable images with 99.99% confidance. After 11th iteration, the training set contains only 25% of the initial training set images.
8. Training ImageNet DNNs with fooling images
In order to test the above condition in ImageNet dataset, we have added a 1001st class with 9000 images fooled by evolution. The number of images in this class is 9000 whereas in other classes it was just 1300. This is to make sure that the DNN emphasises the false negatives. Contrary to the previous experiments, the accuracy dropped from 88.1% to just 11.7%. Thus, we can understand that MNIST dataset was comparitively easier to learn. The below graph shows the accuracy of the various models.
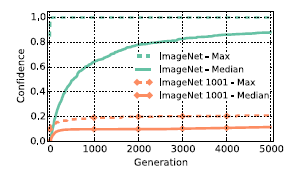
9. Producing fooling images via gradient ascent
We also tried a different way to fool the DNNs to produce high accuracy for unrecognizable images. Here, we are taking the gradient of the softmax output of the DNN model with respect to its corresponding input image using back propogation and then increase the emphasis of features using gradient ascent The model worked well and was able to obtain 99.99% confidence for unrecognizable images. Thus, a third method to fool DNNs are proposed. The sample images are shown below.
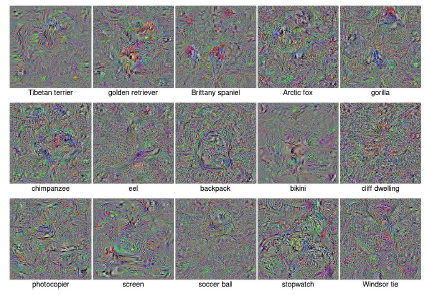
Supplementary Material
But there still exists some questions regarding this topocs. Let us now look at some of these questions in the following passages.
1. Images that fool one DNN generalize to fool other DNNs
The primary question is that whether different DNNs learn same features for each class or it learn distinctive features. In order to solve this, we create two DNN models with same architecture and training but differ only in their randomized initializations. We obtain the evolved images of first model and feed it into the second model. This is performed on both ImageNet and MNIST. The experiment generated 300 evolved images of MNIST and 1000 evolved images of ImageNet.
Following this procedure, we found that both the DNNs gave same results. Many of the fooling images are captured correct by both the DNNs with > 99.99% confidence. This shows that all the DNNs capture features similar to each other. On working with MNIST images, we found that images evolved to represent 6, 9 and 2 are found to have fooled the DNNs the most. But still, all these images showed different features. Thet are shown below.
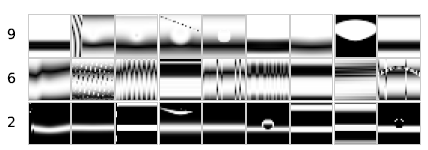
Now, we have to test whether the images genearated by one architecture are fooled by another architecture. Thus, we have chosen two different ImageNet architecture - AlexNet and GoogLeNet provided by caffe. But only 20.7% of GoogLeNet results have similarity with that of AlexNet (17.3% vice versa). Thus, we can conclude that different DNNs are not similar with their architectures.
2. Does using an ensemble of networks instead of just one prevent fooling?
Then we wondered if an ensemble of state of networks would help us escape from getting fooled. To test this, we created an ensemble of three architectures - caffeNet, AlexNet, GoogLeNet. The final confidence score of each image is calculated as the mean of the three architectures. But only after 4000 generations, evolution was able to produce fooling images for 231 classes out of 1000 available with more than 90% accuracy.
3. Training networks to recognize fooling images to prevent fooling
It can be stated that we can identify all the fooled images and classifying them under a separate class and thentraining them again could help solving this problem. So, we did this on MNIST and ImageNet. We tested the evolved images with a DNN algorithm. The fooled images are then added to a new class in the dataset. This new dataset is then trained using another DNN. It is found that eventhough the process is repeated for many iterations, the CPPNs were able to generate fooled images with 99.99% confidence for the newly trained DNNs also. Thus the above statement failed.
4. Evolving regular images to match MNIST
As already mentioned, CPPNs can also produce regular images. Thus, we can also see recognizable patterns in the images generated by CPPNs. WHile obsrving the below shown results, we can recognize that all the different representations of 1 have vertical line while all of 2 have horizondal lines. We have 50 prepresentation because of 5 runs on the 10 class data. This produces 50 distinct recognizable results for each digits.

5. Gradient ascent with regularization
We have also shown above where we can genearte fooling images using gradient ascent and generate output with high confidence. Instead of directly applyig the process, we instead use multiple process to evaluate the impact on the data. We use a 20 class dataset.
In the below samples, we have performed L2 regularization with weight decay after each step by multiplying with a constant of (1-alpha) where alpha = 0.01.

In the below results, we performed the same experiment but with a different weight decay. Alpha was decreased to 0.001. Then we added two additional regularization techniques too. We implemented a gaussian blur with a radius of 0.3 to retrieve information about low frequency detail. The second additional regularization was
a pseudo-L1-regularization in which the pixels with norms lower than the 20th percentile were set to 0. This tended to produce slightly sparser images.
Now, in the below shown samples, we have performed same experiments with same weight decay but with aggressive blurring.

6. Confidence scores of real ImageNet images
We found that the DNNs can be fooled to give high confidence score for images generated by CPPns. But we have to know how the confidence scores of the real images and that of the fooled images are compared. Across the 50000 images of the validation set, the median confidence score is 60.3%. During the cases, both the classfications are correct, the median confidence score is 86.7%. While during the cases, both the classification does not match, the images are given only 33.7% median confidence.
7. Can the fooling images be considered art?
In order to know whether these fooling patterns can be considered as art, we have sent few of the samples to “University of Wyoming 40th Annual Juried Student Exhibition” where only 21.3% submissions are accepted. Our submission was accepted and awarded too. It is then placed at the University of Wyoming Art Museum. The image submitted is shown below.

Conclusion
Thus, we have demonstrated that DNN models can easily be fooled. We have used direct and indirect encoding to evolve the existing images to form regular and irregular images to fool the DNN models. We have also done this using gradient descent as a third approach. These leads to the question that where curret state of art computer vision models actually generalizes the features of the input images.
Resources
- Original paper (PDF) om ArXiv