
Get this book -> Problems on Array: For Interviews and Competitive Programming
ELMo is the state-of-the-art NLP model that was developed by researchers at Paul G. Allen School of Computer Science & Engineering, University of Washington. In this article, we will go through ELMo in depth and understand its working.
Embeddings from Language Models (ELMo)
ELMo model represents a word in the form of vectors or embeddings which models both:
- complex characteristics of word use (e.g., syntax and semantics)
- how these uses vary across linguistic contexts (i.e., to model polysemy).
This is because contex can completely change the meaning of the word.For exmaple:
- The bucket was filled with water.
- He kicked the bucket.
- I have yet to cross-off all the items on my bucket list.
This is one of the main reason why previously used word embeddings failed to capture the multiple meanings of the word as they used one single word embedding for a particular word (word2vec, GloVe, fastText).
Instead of using a word embedding from a dictionary, ELMo creates embeddings of the words on the fly.
It uses a bi-directional LSTM trained on a specific task, to be able to create contextual word embedding.
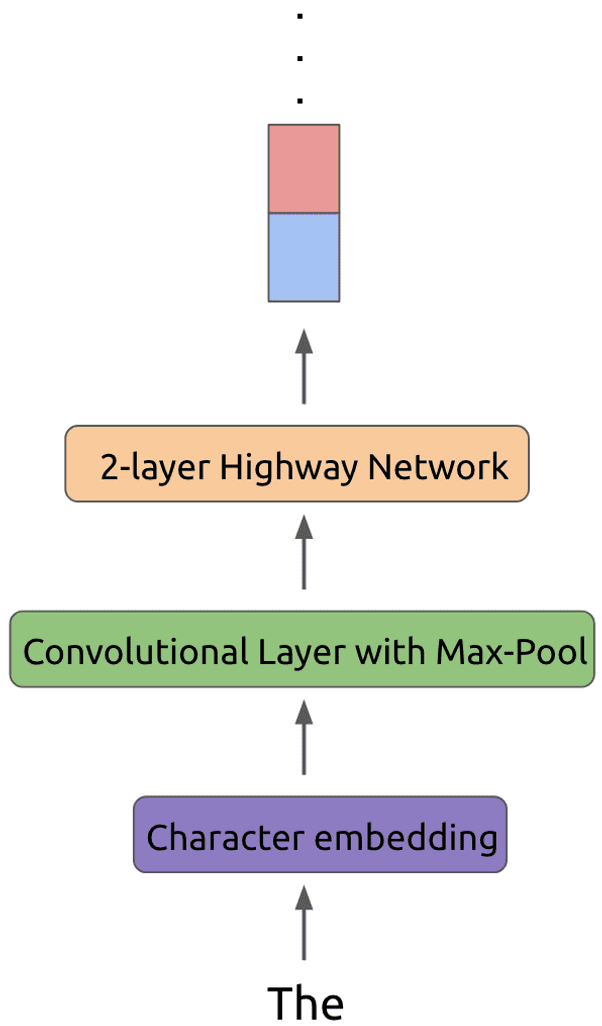
The image shown above that word 'the' is passed through a convolutional layer using some number of filters, followed by a max-pool layer. At last it is passed through a 2-layer highway network and finally it can be fed into biLM model.
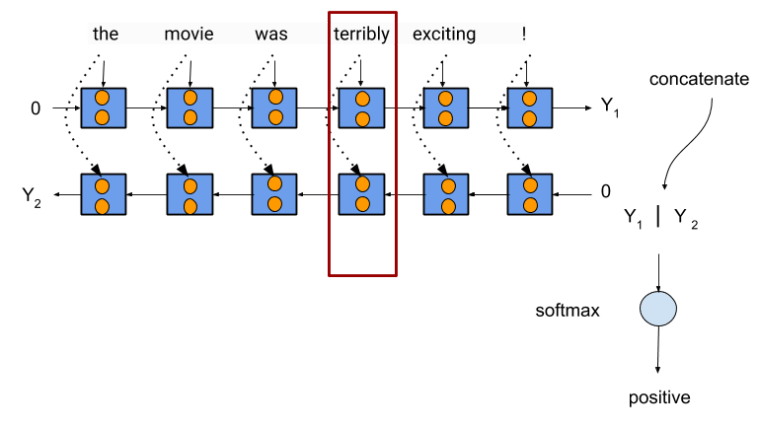
biLM model means that its a bi-directional LSTM which means that a particular word depends not only on all the previous words but all the words ahead of that word. It helps to model the to understand the meaning of that particular word in greater context than suppose if it were single directional LSTM. It will help the model to learn what types of words are generally present behind and at the front of the word at the center of attention.
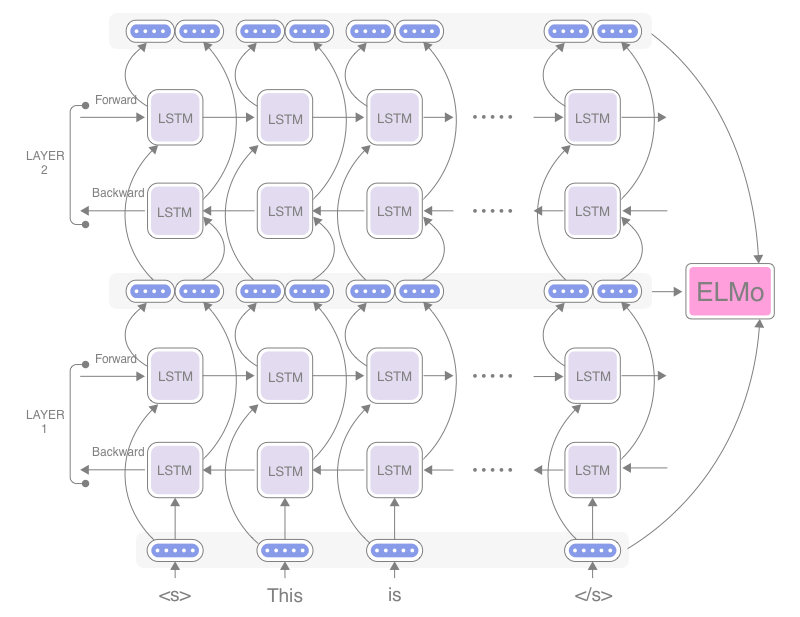
This input is fed to the one of the total 2 layers of biLM. There are two passes in both of the layers. The forward pass contains information about a certain word and the context which is nothing but the other words before that word we are currently at. Similarly, the backward pass contains information about the word and the context of the words after it. After running both the forward and the backward pass, this information is passed to the next or final layer and the same steps happens with this new input. Finally the output which we got from the final layer is averaged with both input and the intermediate vectors. This averaged result is the final output of the ELMo.
As the input to the biLM ELMo model is computed from characters rather than words, it easily captures the inner structure of the word. For example, it can get the difference between beauty and beautiful without even looking at the context.
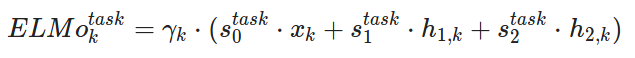
As ELMo takes a summation of these concatenated embeddings it represents a token as a linear combination of corresponding hidden layers and its input and output (input layer (x), first Bi-LSTM output layer (h1) and second output layer(h2) into a single vector).
Once ELMo model has been trained on a text corpus, it can be easily integrated into various NLP tasks with simple concatenation to the embedding layer.
Experiments
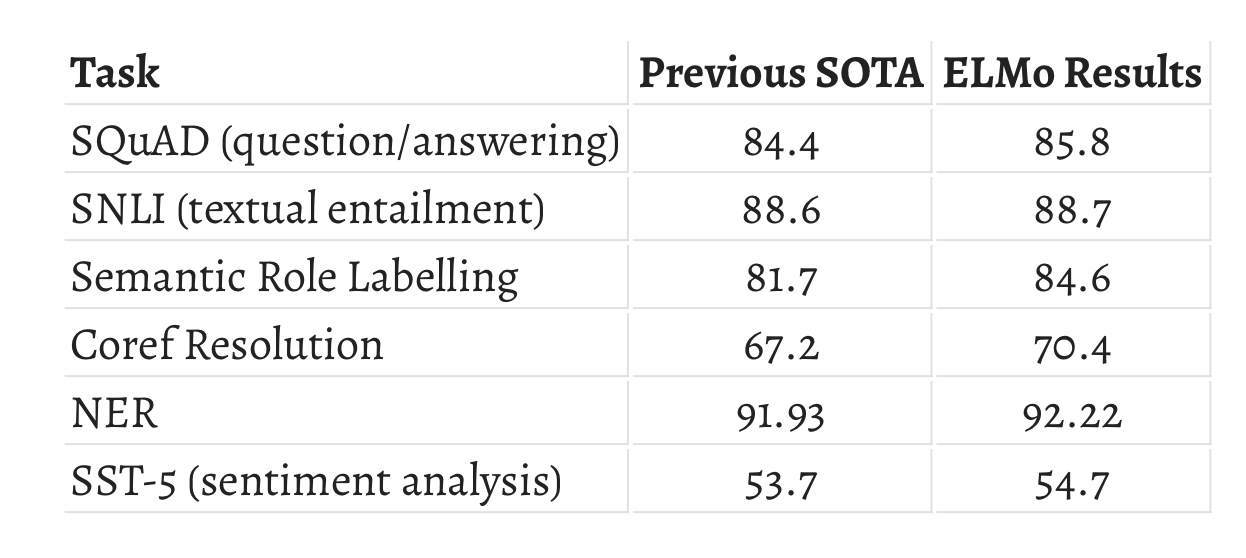
The image above bencharks the performace between previous state-of-the-art (SOTA) and ELMo by running tests on standard dataset such as SQuAD, SNLI and others.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text from the corresponding reading passage, or the question might be unanswerable. SNLI is a collection of about half a million natural language inference (NLI) problems. Each problem is a pair of sentences, a premise and a hypothesis, labeled with one of three labels: entailment, contradiction, or neutral. An NLI model is a model that attempts to infer the correct label based on the two sentences. To learn more about these dataset visit these official links for the datatset.
ELMo representations were added to existing architectures across six benchmark NLP tasks: textual entailment, question answering, named entity extraction, semantic role labelling, sentiment analysis and coreference resolution. In all cases, ELMo achieved state-of-the-art results.
What type of information is captured by ELMo? (and the main reason to use it in NLP tasks)

The image above compares difference between biLM’s context representation of “play” and “play” using GloVe vectors and finally finding the nearest neighbours. 'Play' is polysemic (multiple meaning depending on context) word. We can clearly see the biLM is able to disambiguate both the part of speech and word sense in the source sentence. This is because of the use of biLM as it trained on learning by seeing the words that are not only present behind, but also at the front (full context). 'play' at the top was related to sports and at the bottom it was related to theatrical drama.
Difference between ELMo and BERT?
BERT removed one shortcoming of ELMo. Although ELMo took into account of the context for a particular word and they were two seperate vectorsi.e., it simply concatenated the left-to-right and right-to-left information and hence it couldn’t take advantage of both left and right contexts simultaneously. BERT on the other hand looks all the words at the same time.
Do check out the original research paper given in this ArXiv link