
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we will cover the idea of Pruning which is an important optimization technique for CNN models. It reduces the size of models as well as the Inference time. We dive into two main types of Pruning that is Channel Pruning and Filter Pruning.
Table of Contents:
- Introduction to Pruning in CNN
- Filter Pruning
- Channel Pruning
Prerequisites:
Introduction to Pruning in CNN
Convolutional neural networks (CNN) are now widely used for image processing applications such as picture classification, object recognition, and semantic segmentation. CNN networks frequently have dozens to hundreds of stacked layers, each with many gigabytes of weights.
Pruning is one of the approaches for reducing complexity and memory footprint. Pruning is the process of eliminating weights from the network that connect neurons from two neighbouring levels.
Structured pruning uses channel and filter pruning to build compressed models that don't require specific hardware to run. This latter point is what makes this type of organised pruning so appealing and popular. Understanding and defining how to prune channels and filters in networks with serial data dependencies is rather simple. However, in more sophisticated models with parallel-data dependencies (paths), such as ResNets (skip connections) and GoogLeNet (Inception layers), things get more complicated, and defining the pruning schedule requires a better knowledge of the data flow in the model.
Filter Pruning
Filter pruning might improve the structural integrity of the pruned model and allow for realistic acceleration. Filter pruning techniques currently in use follow a three-stage process.
(1) Training: a big model is trained on the target dataset.
(2) Pruning: irrelevant filters from the pre-trained model are pruned based on a specific criterion.
(3) Retraining (fine-tuning): the pruned model is retrained in order to regain its original performance.
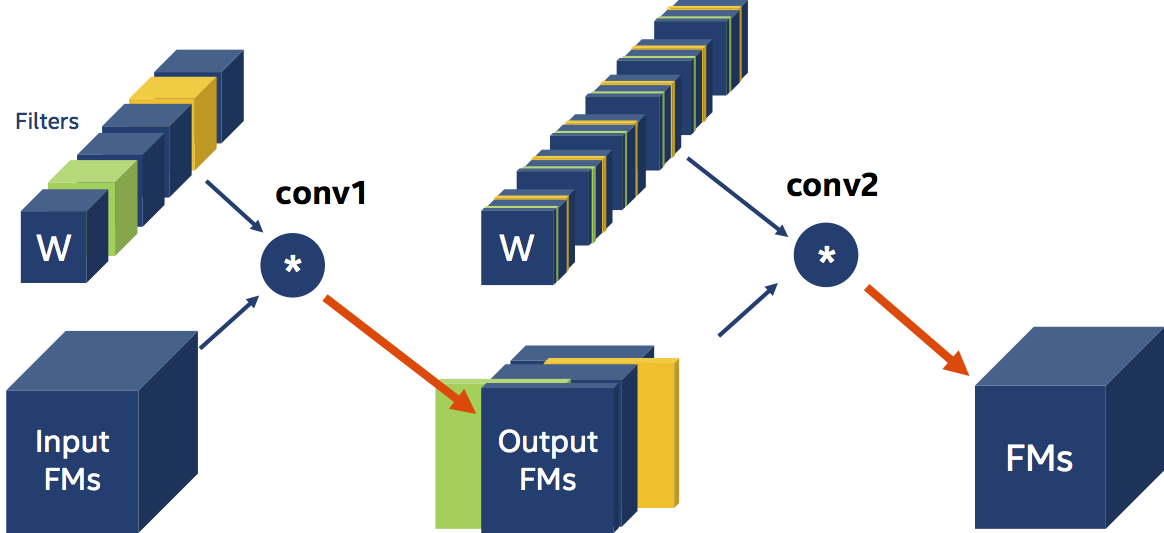
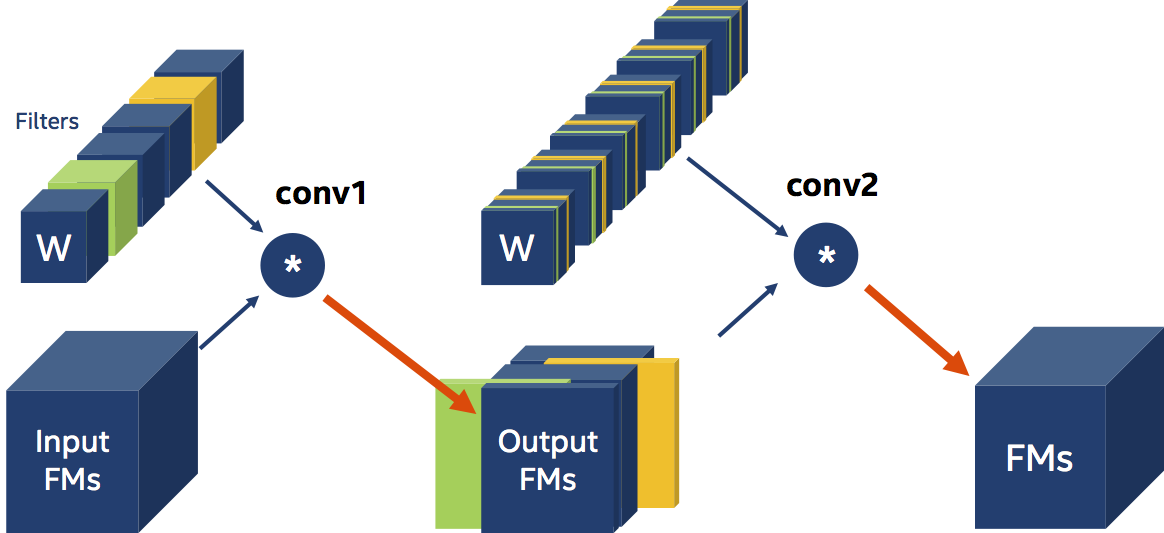
We utilise a criterion to decide which filters are relevant and which are not in filter pruning. The L1-magnitude of the filters (citation), the entropy of the activations (citation), and the classification accuracy decrease (citation) are only a few examples of pruning criteria devised by researchers. Let's pretend that, regardless of how we choose the filters to prune, we opted to prune (eliminate) the green and orange filters in the figure below (the circle with the "*" represents a Convolution operation).
We need two fewer output feature-maps since we have two less filters acting on the input. When we prune filters, we must additionally modify the immediate Convolution layer (change its out channels) and the next Convolution layer (change its in channels), in addition to adjusting the actual size of the weight tensors. Finally, because the next layer's input is now smaller (has fewer channels), we should remove the channels corresponding to the filters we pruned from the weights tensors of the next layer. We say that there’s data-dependency amongst the two convolutional Layers.
Now, between the two convolutions, add a Batch Normalization layer:
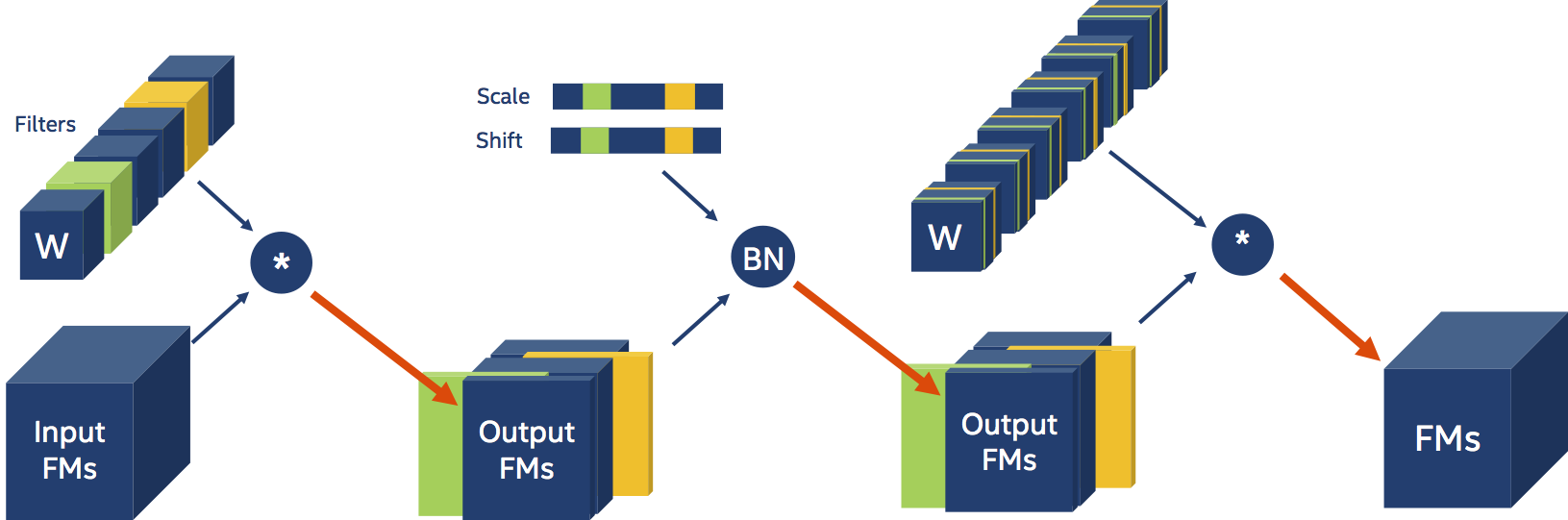
A handful of tensors that carry information per input-channel parameterize the Batch Normalization layer (i.e. scale and shift). We must additionally change the Batch Normalization layer because our Convolution produces less output FMs, which are the input to the Batch Normalization layer. We also need to physically decrease the scale and shift tensors of the Batch Normalization layer, which are coefficients in the BN input transformation. Furthermore, the filters (or output feature-maps channels) that we deleted from the Convolution weight tensors must match to the scale and shift coefficients that we removed from the tensors. The inclusion of a Batch Normalization layer in the above example is undetectable to us, and the YAML schedule remains unchanged. Distiller recognises Batch Normalization layers and automatically modifies their settings.
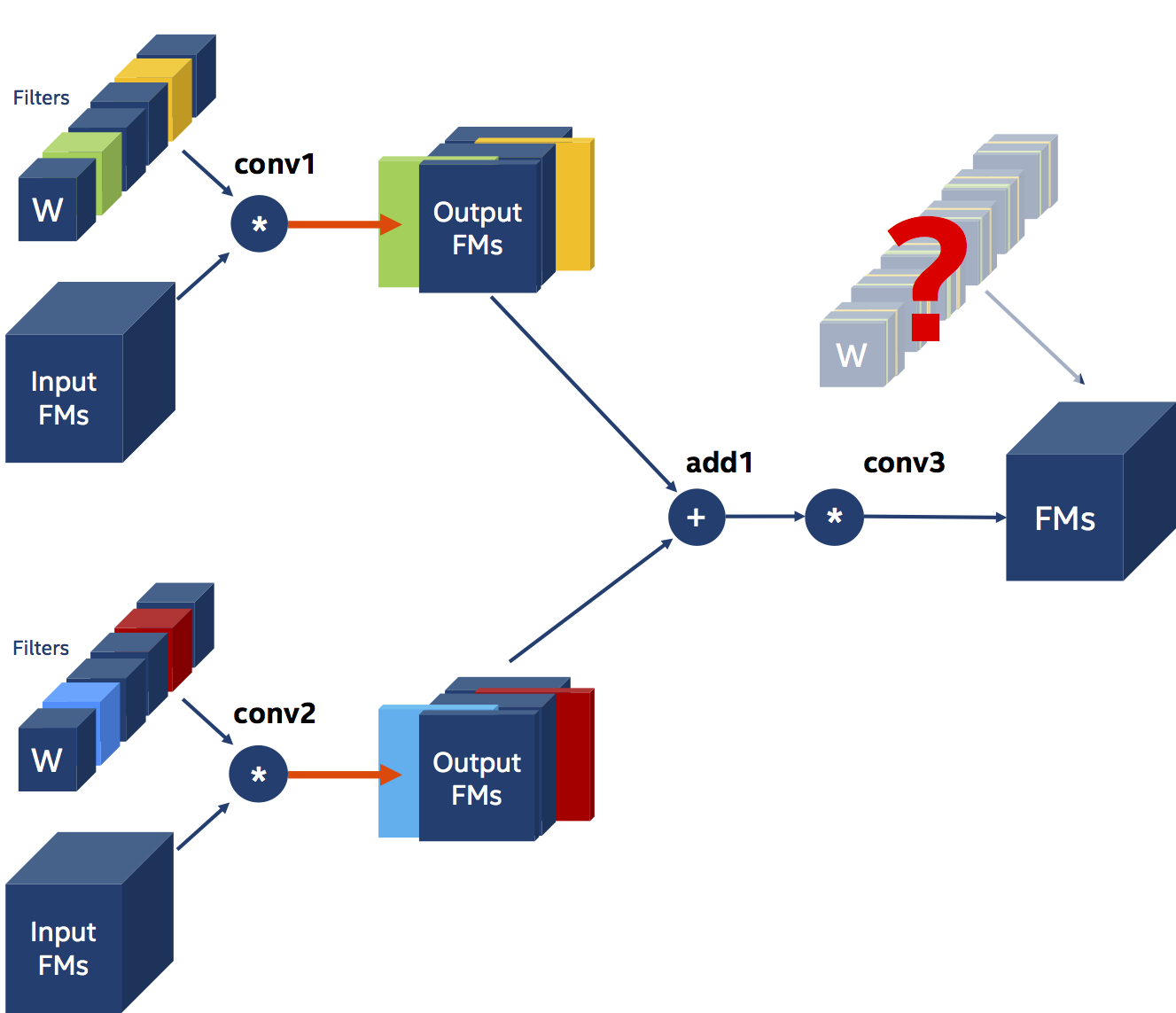
Let's look at another example with three Convolutions, but this time we'll prune the filters of two convolutional layers whose outputs are element-wise summed and fed into a third Convolution. Conv3 is dependent on both conv1 and conv2 in our case, and this reliance has two consequences. The first and most apparent conclusion is that both conv1 and conv2 must have the same number of filters pruned. Because we combine the outputs of conv1 and conv2 using element-wise addition, they must have the same shape - and they can only have the same shape if conv1 and conv2 prune the same number of filters. The second consequence of this triangular data dependence is that both conv1 and conv2 must prune the same filters! Let us pretend for a moment that we don't care about the second limitation. The following figure depicts the difficulty that arises: Can we prune the channels of the weights of conv3? We can’t!
We must now apply the second constraint, which requires us to be proactive: we must determine whether to employ the prune conv1 and conv2 based on conv1's or conv2's filter-pruning selections. The pruning strategy after electing to adopt conv1's pruning selections is depicted in the figure below.
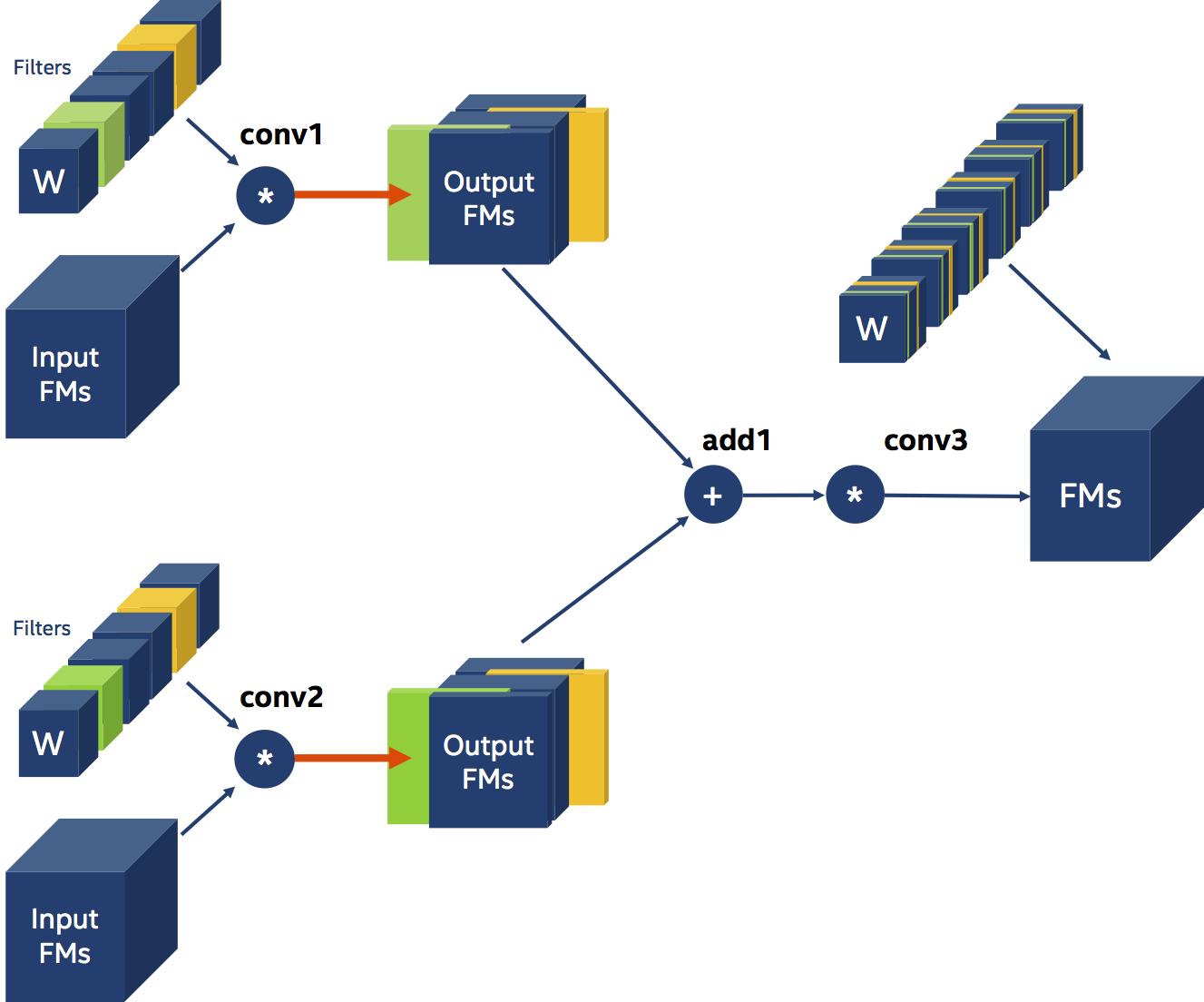
First, we must inform the Filter Pruner that a dependence of type Leader exists. This indicates that at each iteration, all of the tensors specified in the weights field are pruned simultaneously, to the same amount, and that the pruning choices of the first tensor listed will be used to prune the filters. Module.conv1.weight and module.conv2.weight are pruned jointly in the example below, based on the pruning options for module.conv1.weight.
pruners:
example_pruner:
class: L1RankedStructureParameterPruner_AGP
initial_sparsity : 0.10
final_sparsity: 0.50
group_type: Filters
group_dependency: Leader
weights: [module.conv1.weight, module.conv2.weight]
Because of the skip-connections, we encounter some fairly lengthy dependency chains while filter-pruning ResNets. If you're not careful, you may easily under-specify (or mis-specify) dependency chains, causing Distiller to crash. This has to be addressed because the exception does not explain the specification mistake.
Channel Pruning
Channel pruning is a type of structural model compression technique that not only reduces model size but also improves inference speed. Pruning channels is easy yet difficult since eliminating channels from one layer might have a significant impact on the input of the next layer. Recently, training-based channel pruning research has focused on placing sparse constraints on weights during training, which might help hyper-parameters be determined adaptively.
Through channel pruning we can remove redundant channels on feature maps. To enhance accuracy, there are numerous training-based ways to regularise networks. For the first several conv layers of LeNet and AlexNet, channel-wise SSL achieves a high compression ratio. Training-based techniques, on the other hand, are more expensive, and their use for extremely deep networks on huge datasets is rarely utilised.
Channel pruning is identical to Filter pruning, but with the dependency details reversed. Consider the example again, but now pretend we've adjusted our schedule to prune the channels of module.conv2.weight.
Conv1 is now relying on conv2, and its weights filters will be implicitly pruned based on the channels eliminated from conv2's weights, as shown in the diagram.
It's evident that channel pruning has two major components. The first is channel selection, since we need to choose the most representative channels in order to keep as much data as possible. The second step is to rebuild (reconstruction). Using the specified channels, we must recreate the feature maps.
Through this article at OpenGenus you must have a strong understanding of what Channel and Filter pruning are.