
Reading time: 30 minutes | Coding time: 15 minutes
With due time, it has become easier to produce summaries due to latest tools such as NLTK and Sumy in Python. In this article we will understand Graph based approach for text summarization (also known as Graph Reduction) which basically helps in providing quick insights to the large documents and thus helping in producing summaries.
It uses techniques to reducing graph size such as predicate argument mapping and normalization.
Introduction
The graph based approach for text summarization is an unsupervised technique,where we rank the required sentences or words based on a graph. In the graphical method the main focus is to obtain the more important sentences from a single document. Basically, we determine the importance of a vertex within a graph. We use unidirected and weighted graphs to implement text-based ranking. In this technique either of the documents or sentences are represented as nodes. Edges are used to connect any two nodes sharing the common information. Sentence scoring is done by intializaing weightage to the nodes of the graph.
Graph based methods are much more easy to visualize, understand and are more redundant than the other summarization methods. However, pwe can only generate summary for a single document using this method.
Other methods following graph based approach for text summarization includes:
- PageRank : It is an algorithm used by Google to manage its interconnectivity of web-pages with similar content.
- LexRank:In this method we use cosine similarity and tf-idf models.
- TextRank:In this method we use model somewhat similar to LexRank in addition to normalization of our data.
Note- PageRank is the parent method to both LexRank and TextRank.
Concept
Objective is to extract the most important sentences from the original document by first generating the document semantic graph and then using the document and graph features to generate the document summary.
First, Semantic representation of the graph based on the Subject-verb-object triplet is created. Nodes are linked created based on the association of the words. Then the nodes(expressions) referring to the same entities are removed from the graph. This is also known as processing phase. Words are divided based on their semantical and gramatical meanings as nodes.
Then in order to reduce the graph a set of heuristic rules are applied. Scored are provided to the sentences for efficient ranking. The hueristic reduction method consists of the following three nodes, namely Subject-Noun node(SN), Main verb node(MV) and Object-noun(ON) node. All the irrelevant words are removed.
In the final phase a logical graph is obtained using the triplets where the associated nodes consist of subjects and objects. Sentences with the highest scores are selected for the final reduced graph.
In case of rich semantic graph the nodes store the text semantics unlike traditional semantic graphs that were not able to understand the meaning of the sentences.
Algorithmic steps

It is necessary to preprocess all the data prior to use it for text summarization. In our implementation we have tried to remove the stopwords as a part of preprocessing. The following steps to generate an algorithmic summary:
- The verbs and the nouns present in the document are represented as the nodes and edges of the graph.
Let us consider a simple graph for better understanding.
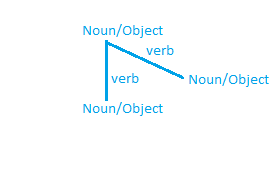
The main objective is to generate a redundant graph for each module of sentences.
2.In the second step,we reduce the original graph to a more reduced graph using heuristic rules . This is done as follows:
- Mapping: This refers to predicate-argument mapping.
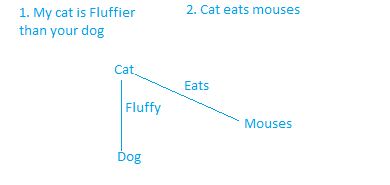
Note that how we are just mapping the predicate (that is cat) to the argument (that is dog and Mouses) which reduces the complexity of the graph and preserves its meaning as well. The edges have the action word associated with it.
- Normalization: Here we will use log transformation for normalization:
Normalization = log(length[words1]) + log(length[words2])
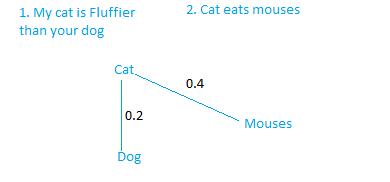
where words1 and words2 are the set of words in any sentence sentence1 and sentence2 respectively.
*NOTE - The sentences placed in the graph are preprocessed i.e. Stopwords are removed.
Step 2 is the most important step.
In this step we replace or remove the exsting nodes in the graph according to their relevance.
It is not an iterative algorithm.
Finally we have our reduced graph as follows:

3.In the third step we get the output as an abstractive summary.
Applications
- Text summarization
- Web link analysis
- Ranking web Pages
Naive Implementation
Import the necessary packages
import math
from itertools import combinations
from collections import defaultdict
After importing all the required modules, we define the Reduction summarizer.
class ReductionSummarizer():
_stop_words = frozenset()
#Overriding property
@property
def stop_words(self):
return self._stop_words
@stop_words.setter
def stop_words(self, words):
self._stop_words = frozenset(map(self.normalize_word, words))
def __call__(self, document, sentences_count):
ratings = self.rate_sentences(document)
return self._get_best_sentences(document.sentences, sentences_count, ratings)
We shall define a function to rate the sentences as used above.
## Rating the sentences
def rate_sentences(self, document):
sentences_words = [(s, self._to_words_set(s)) for s in document.sentences]
ratings = defaultdict(float)
# Iterating over the sentences in order to rank them
for (sentence1, words1), (sentence2, words2) in combinations(sentences_words, 2):
rank = self._rate_sentences_edge(words1, words2)
ratings[sentence1] += rank
ratings[sentence2] += rank
return ratings
def _to_words_set(self, sentence):
words = map(self.normalize_word, sentence.words)
return [self.stem_word(w) for w in words if w not in self._stop_words]
In the method defined below we rate(define weight) for each sentence present at the node.
def _rate_sentences_edge(self, words1, words2):
rank = 0
for w1 in words1:
for w2 in words2:
rank += int(w1 == w2)
if rank == 0:
return 0.0
assert len(words1) > 0 and len(words2) > 0
norm = math.log(len(words1)) + math.log(len(words2))
return 0.0 if norm == 0.0 else rank / norm
Quick Implementation using sumy library
Using sumy:
#Importing necessary packages
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.reduction import ReductionSummarizer
doc="""OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
OpenGenus is all about positivity and innovation.
Over 1000 people have contributed to our missions and joined our family. We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean. We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
"""
print(doc)
Output-
OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
OpenGenus is all about positivity and innovation.
Over 1000 people have contributed to our missions and joined our family. We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean. We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
# For Strings
parser=PlaintextParser.from_string(doc,Tokenizer("english"))
# Using Reduction Summarizer
summarizer = ReductionSummarizer()
#Summarize the document with 4 sentences
summary = summarizer(parser.document,2)
for sentence in summary:
print(sentence)
Output-
OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
Conclusion
We have successfully generated an abstractive summary for our document using reduction technique.
Advantages-
- Redundant summary is obtained.
- Grammatically more accurate.
Disadvantages-
1.Limited to a single document.
Further Reading
- Graph-Based Algorithms for Text Summarization(Pdf) by Khushboo S. Thakkar , Dr. R. V. Dharaskar and M. B. Chandak.
- Graph Based Approach for Automatic Text Summarization by Akash Ajampura Natesh, Somaiah Thimmaiah Balekuttira, Annapurna P Patil.
- Semantic Graph Reduction Approach for Abstractive Text Summarizationby Ibrahim F. Moawad and Mostafa Aref .