
In this article, we will look at what are graph databases, how they differ from traditional relational databases, and their uses in System Design.
Table of Contents
- What is a Graph?
- Graph Databases
- Types of Graph Databases
- Need for Graph Databases
- Popular Graph Databases
- Usecase - Credit Card Fraud Detection
- Challenges in Graph Databases
What is a Graph?
A graph is a collection of nodes that are connected by edges. An edge always connects 2 nodes.
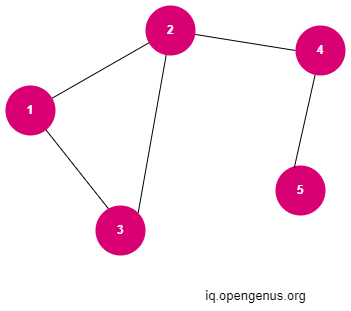
In the above image, 1,2,3,4 and 5 are called the nodes or vertices of the graph.
They are connected by using edges. The edges can be weighted (have a value) and can be uni-directional depending upon the type of graph.
Graph Databases
A graph database is simply a database that makes use of the graph data model. That is, it stores the data in nodes, and the relationship among the data is given by edges. For example, a graph database may look like this,
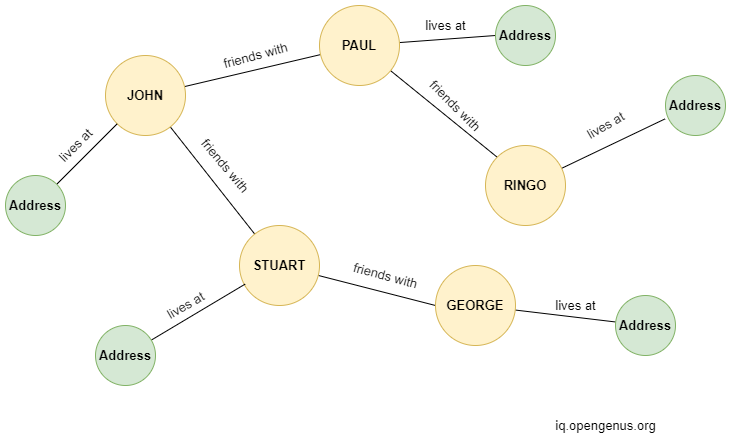
This graph database describes a social network, with each person having an address where they live and an edge to those they are friends with.
Types of Graph Databases
There are 2 main types of graph databases.
- Property Graphs
- Resource Description Framework
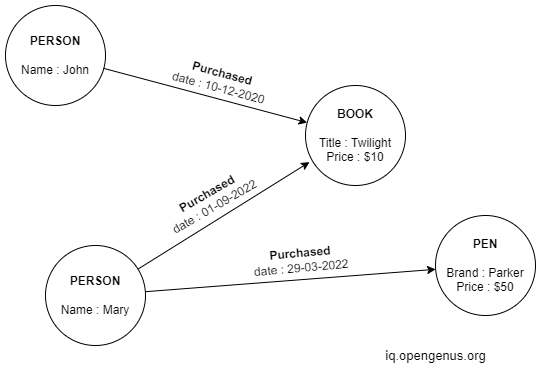
Property Graphs:
In a property graph, the nodes and vertices may have attributes, called properties. They are commonly used to model relationships among data. Then enable easy querying and analytics of data.
Resource Description Framework:
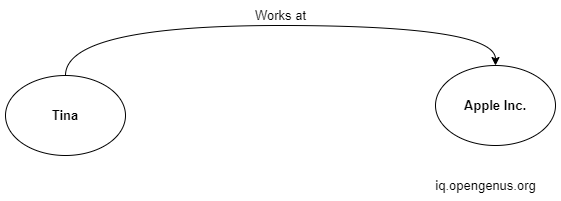
Resource Description Framework is also known as RDF graph database is a W3C standard originally designed for encoding, exchange, and reuse of structured metadata. It has since become a general method for describing and exchanging graph data.
An RDF consists of 3 components referred to as a triple,
- The subject is the resource which is a resource that is being described.
- The predicate is the relationship between the subject and object.
- The Object is the resource to which the subject is linked.
Relational Databases and the Need for Graph Databases
Oftentimes, the data that we encounter in the real world is highly relational and requires complex traversals. In traditional relational databases, we separate the data into different tables to reduce insertion, update, and deletion anomalies.
But what happens when we need to study the relationships among various data or combine some tables to get a new result? This problem can be solved in relational databases by using deep joins which can be very complex. Further, as the database grows, joins can take a lot of time and slow down the performance of the system.
Enter graph databases. They store our data in a much more logical fashion and in a way that represents the real world. Adding new nodes or adding a new data value to an existing node is as simple as it sounds.
Popular Graph Databases
Let us take a look at some of the most popular graph databases available and their unique features.
Neo4j
Neo4j is one of the most popular graph database management systems. It is ACID compliant and hence can be used for transactional purposes. In Neo4j everything is stored in the form of an edge, node, or attribute. Each node and edge can have any number of attributes. Both nodes and edges can be labeled. It is written in Java but can be used in other languages through its property graph query language called Cypher.
Dgraph
Dgraph is another popular option for a graph database. Dgraph is currently the most starred graph database in Github. It natively uses GraphQL query language. Dgraph is known for its performance and scalability. It just takes milliseconds to query terabytes of data.
AWS Neptune
AWS Neptune is a fast and fully managed graph database provided by Amazon Web Services. It can perform 100,000 queries per second and is highly reliable and can perform a continuous backup to S3 storage. Neptune supports popular graph models like RDF and property graphs and their query languages like Apache TinkerPop Gremlin and SPARQL.
ArangoDB
ArangoDB is an open-source, multi-model graph database. It combines the power of graphs with JSON documents, a key-value store, and a full-text search engine allowing developers to combine all these data models and benefit from them.
Usecase - Credit Card Fraud Detection
Over the years, there have been many measures taken by financial institutions to prevent credit card fraud such as using an embedded chip in cards. However, In many places which don't use chip readers, card skimming devices card devices can still be stolen by reading the magnetic strips. Once the card details are obtained, they can be used to make duplicate cards and make purchases online or withdraw money.
Detection of card fraud usage involves finding purchase patterns based on the location and other details based on the user. Graph analytics can efficiently be used to establish patterns and identify natural behavior patterns. The graph nodes are given by the location, transaction, accounts of cardholders, etc.
For example, It is highly unlikely that a user from the UK would suddenly make a car purchase in India through a credit card. This is a flag that the transaction could be potentially fraudulent.
Challenges in Graph Databases
- The is no widespread standard on the query language used for graph databases. It differs based on the software used.
- The community is small and hence it is hard to find solutions to a problem when it is encountered.
- Graph databases need to make trade-offs in ACID properties and hence may not be suitable for mission-critical applications.
Despite these challenges, graph databases have been evolving in popularity over the years with the increase in computing power and used to model complex data relationships.
With this article at OpenGenus, you must have the complete idea of Graph Database in System Design.