
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we have explained the idea of zero copy intuitively with code examples. This is an important idea to design efficient systems.
Table of contents:
- Pre-requisites
- Problem statement
- Idea of Zero Copy
- Applications of Zero Copy
- Codes & examples
- Setup environment to run the code
- Try it
- References
Learn via Audio:
Pre-requisites:
FILE handling in C, system call (GNU/Linux preferred), kernel space, user-space, context switches, sockets in networking
Problem statement:
It is usual to upload resume or CV and/or cover letter in a job portal when seeking for a job. What are the steps that are followed by a machine, when we upload a file? A byte/string/page-size amount of information from disk (secondary storage where file is present) will be to memory by kernel, then the information is again copied to browser's (user-space process) address space by kernel. Browser shall now use socket related functions, to copy the information to corresponding socket dedicated for the job portal. In the end, sockets redirect the information to kernel which interacts with networking hardware to handle the rest. Here same information is copied 4 times: disk to kernel space memory, kernel space memory to user-space memory, user-space memory to kernel space memory, kernel space memory to network hardware buffers and two context switches between user-space, kernel space. This seriously hurdles the performance as the process wastes CPU cycles. The below figure depicts the mentioned issue.
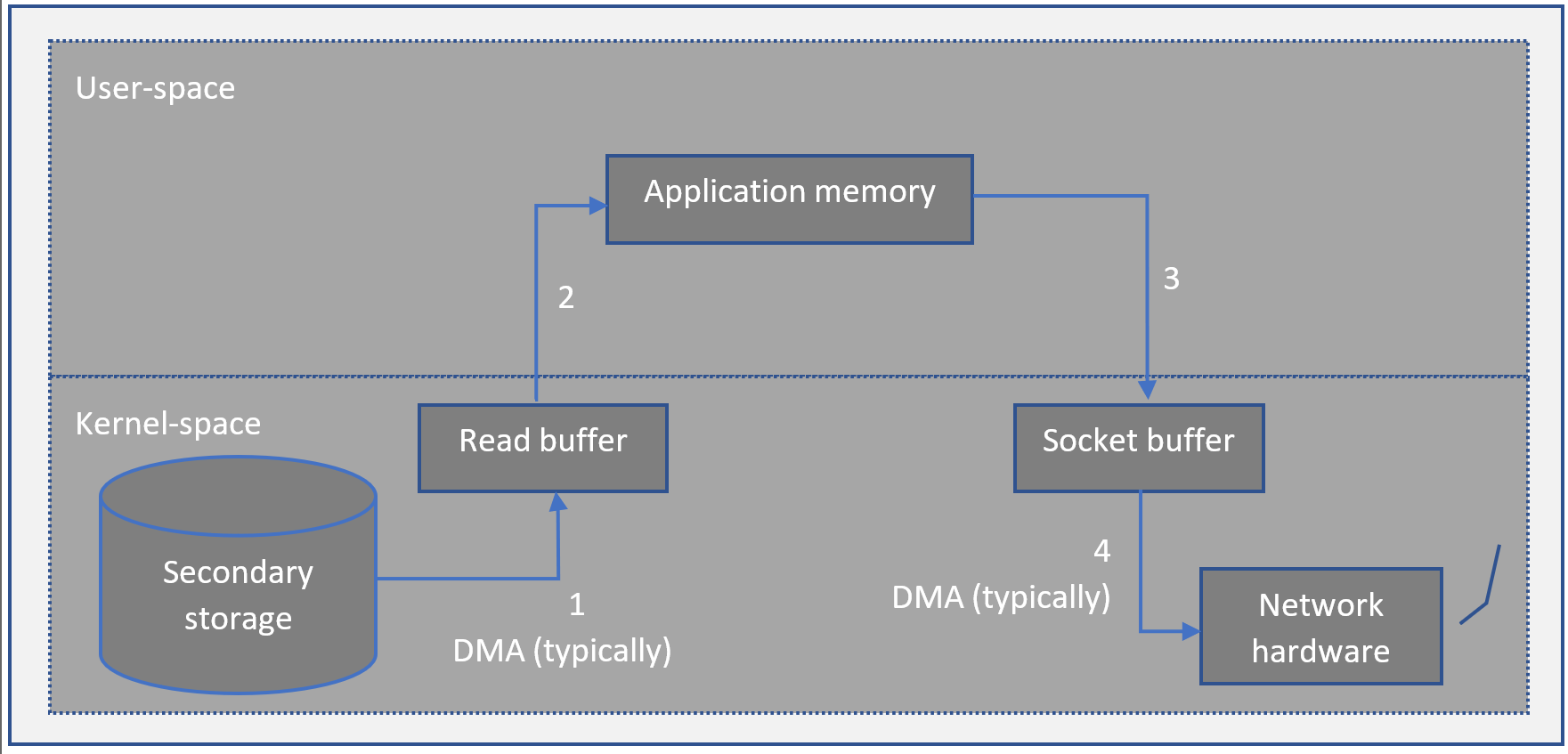
Idea of Zero Copy
What if the kernel itself handles copying from disk to network directly? This would significantly save 2 buffers and the 2 un-necessary context switches between kernel space and user-space. Note that, there may be an idea of something like, disk copying file directly to network peripheral's buffers without CPU's involvement. Basics of this idea is illogical: CPU must be the master and control peripherals in the system; If peripherals can communicate directly (unless CPU commanded), then system is said to compromised and it is useless to have CPU on machine.
The concept of copying data from one peripheral to another peripheral by kernel, without switching back to user-process is termed as zero copy. As you may know, kernels offer system calls for user-space processes to interact with hardware or to get things done from the kernel. GNU/Linux offers a system call named sendfile for achieving the idea of zero copy. This process is briefed in the below picture.
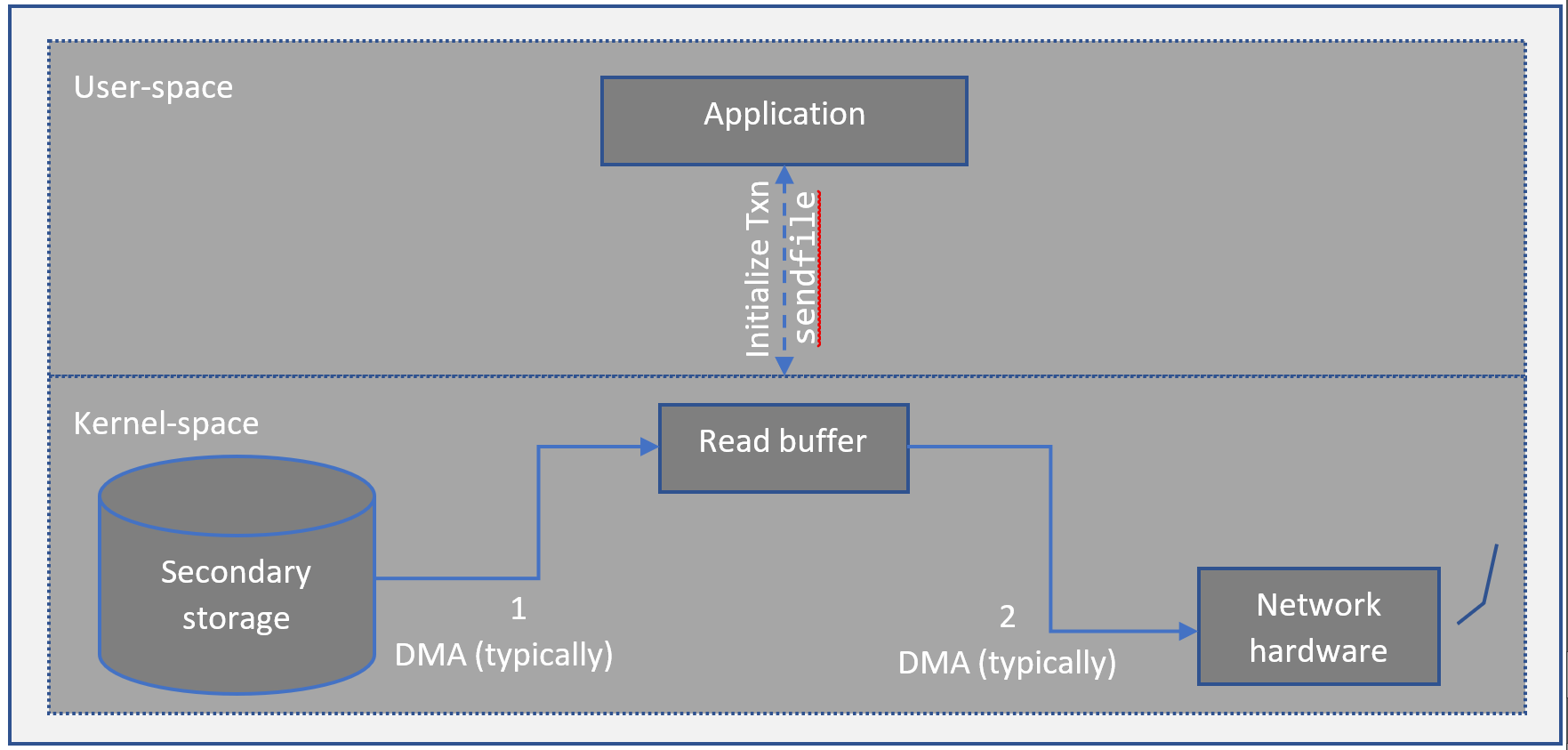
Applications of Zero Copy
- The idea itself aims to solve issue discussed in the problem section of this article. That is, Improvising performance for network applications.
- Nearly everything is a file in Unix like OSs. So, the mentioned
sendfilecan even be used for normal files along with socket files. Thus making file copying bit more efficient. - I feel that, the concept can be used to make memory-memory, peripheral-peripheral transactions as commanded by CPU; Why this? Reason is simple: "nearly everything is a file in Unix like OSs".
Codes & examples
The code tries to demonstrate usage of sendfile system call by using normal disk-files and not socket-files. Code also tries to compare time consumed to copy data between two files when usual read, write system calls are used and when sendfile is used. If ZEROCOPY switch is defined then code is compiled such that file contents of in are copied to out1 else copied to out. This is achieved by making use of conditional compilation or compile time switches such as, #ifdef, #else, #endif. Kernel tracks open files by giving them a number, termed as file-descriptor & typically declared as fd. If we encounter an error while opening in, out/out1 file/s or while allocating dynamic memory, the code releases allocated resources and ends execution by returning from main. Code duplication is avoided to release resources by making use of an unconditional branching of C-language construct; that is goto. Files are opened by using open system call for both in file, out/out1 file and corresponding file-descriptors are saved in 2 variables.
Once both the files are open, we find number of characters in in file and store it in a variable. Once the size is known, we get a dynamic memory of size bytes. This memory is used if the code uses read, write to copy file contents. File statistics for in file can be obtained by using fstat function.
Once memory is allotted successfully, we use read syscall on in file-descriptor and get complete contents of in file into the allotted memory. Contents of the memory are then written into out/out1 file using write syscall.
If the code is compiled with ZEROCOPY switch defined, only sendfile is used in the place of read and write. Irrespective of ZEROCOPY switch, count of CPU clock cycles is noted before making copy and after making copy. The difference in the noted clock values helps us compare performances.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <sys/stat.h> //open
#include <fcntl.h> // open
#include <sys/types.h> // fstat
#include <sys/stat.h> // fstat
#include <unistd.h> // fstat, read, write
#include <sys/sendfile.h> // sendfile
#define IN_FILE "in"
#ifdef ZEROCOPY
#define OUT_FILE "out1"
#else // ZEROCOPY
#define OUT_FILE "out"
#endif // ZEROCOPY
int main()
{
// FILE *in, *out;
int in_fd, out_fd;
struct stat stat_buf;
char *c;
unsigned long int file_size;
clock_t start, end;
// in = fopen(IN_FILE, "r");
in_fd = open(IN_FILE, O_RDONLY, 00664);
// if (!in) {
if (in_fd == -1) {
puts("File doesn't exist or unknown error");
goto in_error;
}
else {
puts("File already exits and opened in read mode successfully");
}
// out = fopen(OUT_FILE, "w");
out_fd = open(OUT_FILE, O_WRONLY | O_CREAT, 00664);
// if (!out) {
if (out_fd == -1) {
puts("Unable to open/create the file");
goto out_error;
}
else {
puts("Out file open in write mode successfully");
}
file_size = (fstat(in_fd, &stat_buf), stat_buf.st_size);
c = malloc(file_size);
if (!c) {
puts("Unable to allocate memory");
goto mem_error;
}
start = clock();
#ifndef ZEROCOPY
read(in_fd, c, file_size);
write(out_fd, c, file_size);
#else // ZEROCOPY
sendfile(out_fd, in_fd, 0, file_size);
#endif // ZEROCOPY
end = clock();
printf("Time consumed: %ld\n", end - start);
free(c);
mem_error:
close(out_fd);
out_error:
close(in_fd);
in_error:
return 0;
}
Setup environment to run the code
The code is tested in a GNU/Linux based machine. Make sure that a file named in exists in the same directory as that of executable. Code assumes that in file has some content (if not make use of lorem-ipsum text). Build guide - gcc -o nozerocopy file.c && gcc -o zerocopy -DZEROCOPY. -D option to GCC defines the followed pre-processor macro or compile-time switch. As explained earlier, same code is compiled into two different executables: one with the ZEROCOPY defined and other with no such switches.
The below is shown in my terminal screen
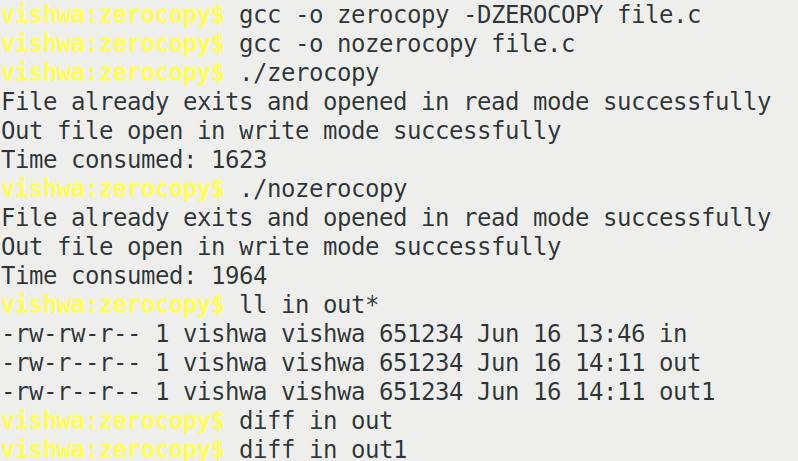
From the above picture it is clear that, idea of zerocopy helps save CPU cycles and thus saving time. As there's no context switch involved, kernel implementation may not keep another copy of buffer; The read data pointer itself may be passed to writing function of the file, thus saving space too (however it depends on implementation).
The above snapshot also clears the doubt of successful copy by making use of diff tool among in, out, out1 files.
man pages are a useful resource and serve as documentation for the tools in Unix-like machines. System calls and header-files that need to included are also well documented in man pages.
Try it:
The example code shows usage of disk-files for measuring and demonstration. Readers are encouraged to try repeating both codes, by using socket files. Discuss your issues when you try.
References:
[1] https://developer.ibm.com/languages/java/articles/j-zerocopy/
[2] Man pages https://linux.die.net/man/3/fstat, https://man7.org/linux/man-pages/man2/sendfile.2.html