
In this article, we have explored about a neural network architecture called Inception and understand in great detail its fourth version, the Inception V4 along with the architecture of InceptionV4 model.
Table of contents
- Working of a naive Inception layer
- Motivation for the Inception network
- Inception architecture
- Inception V4 architecture
- Inception V4 vs previous inception models
Working of a naive Inception layer
Instead of choosing the filter size and its dimensions amongst many possibilities for a conv layer or choosing between a conv and a pooling layer, an inception layer performs it all and gives a concatenated output. For example, let's assume that we give an input of 28 x 28 x 192 as shown below.
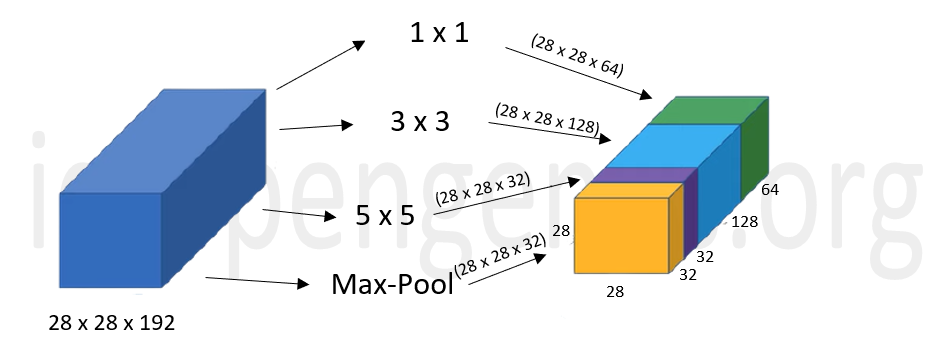
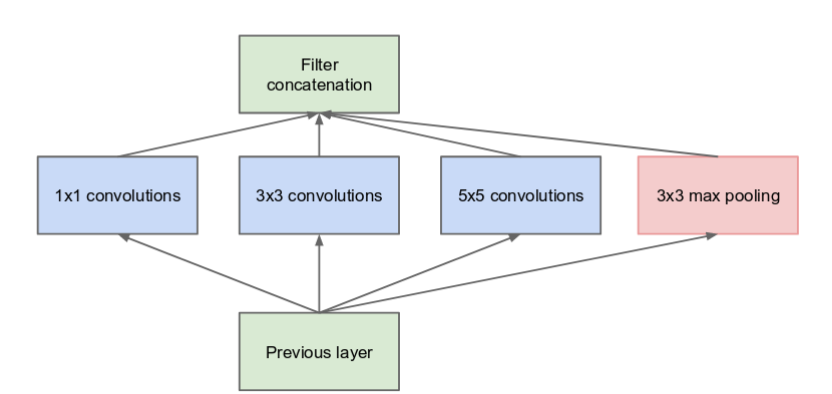
On the given input, the inception layer perfoms a 1 x 1 convolution which has 64 filters and gives an output of dimensions 28 x 28 x 64 (given in green colour). Similarly it performs a 3 x 3 convolution with 128 filters , a 5 x 5 convolution with 32 filters giving outputs of dimensions 28 x 28 x 128 and 28 x 28 x 32 respectively. It also performs pooling as shown. All these outputs are concatenated or stacked on one another which gives us the final output of dimensions 28 x 28 x 256. Given below is a representation of the naive Inception module.
Motivation for the Inception network
Now that we have seen what's the basic idea behind an Inception layer and how it works, let us understand as to why we need it.
Objects in the images can be in a multitude of sizes. For example, the area in which a lion can be present in an image can vary as shown.

Due to this variation in size, choosing the optimal kernel size for the convolution layer becomes difficult. A larger or a smaller kernel is peferred depending on the distribution of information. A very specific and deep neural network may lead to overfitting.
The solution to this is making the network wider rather than deeper by having many sizes operate on the same level. The Inception network was formulated keeping this idea in its core.
Inception architecture
One major change made to the naive Inception layer is that a 1 x 1 convolution layer was added before the 3 x 3 and 5 x 5 convolution layer and after the max pooling layer. This change was implemented in the architecture of the Inception neural network to limit the number of inputs which inturn reduces the computational cost and was named GoogleNet. Given below is the inception layer after implementing the changes stated above.
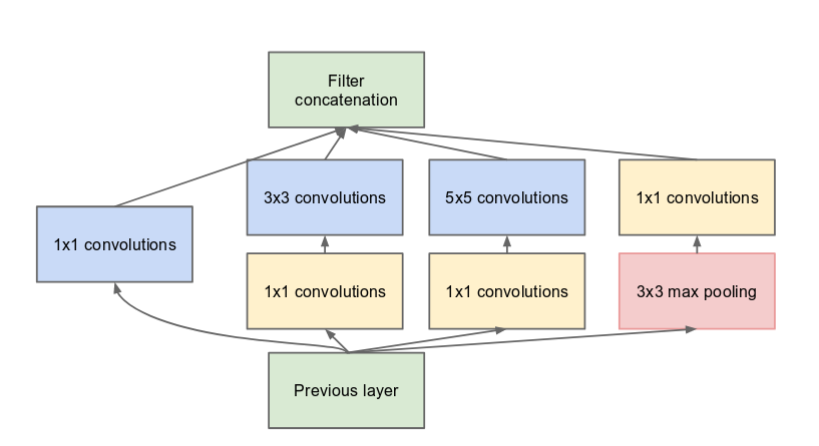
Vanishing gradient problem may arise in this model as it is a deep classifier. To avoid this, two auxillary classifiers are introduced in the model. The architecture of GoogleNet is given below.
| Type | Patch size / stride | Output size | Depth | # 1 x 1 | # 3 x 3 reduce | # 3 x 3 | # 5 x 5 reduce | # 5 x 5 | pool proj |
|---|---|---|---|---|---|---|---|---|---|
| convolution | 7 x 7 / 2 | 112 x 112 x 64 | 1 | ||||||
| max pool | 3 x 3 / 2 | 56 x 56 x 64 | 0 | ||||||
| convolution | 3 x 3 / 1 | 56 x 56 x 192 | 2 | 64 | 192 | ||||
| max pool | 3 x 3 / 2 | 28 x 28 x 192 | 0 | ||||||
| inception (3a) | 28 x 28 x 256 | 2 | 64 | 96 | 128 | 16 | 32 | 32 | |
| inception (3b) | 28 x 28 x 480 | 2 | 128 | 128 | 192 | 32 | 96 | 64 | |
| max pool | 3 x 3 / 2 | 14 x 14 x 480 | 0 | ||||||
| inception (4a) | 14 x 14 x 512 | 2 | 192 | 96 | 208 | 16 | 48 | 64 | |
| inception (4b) | 14 x 14 x 512 | 2 | 160 | 112 | 224 | 24 | 64 | 64 | |
| inception (4c) | 14 x 14 x 512 | 2 | 128 | 128 | 256 | 24 | 64 | 64 | |
| inception (4d) | 14 x 14 x 528 | 2 | 112 | 144 | 288 | 32 | 64 | 64 | |
| inception (4e) | 14 x 14 x 832 | 2 | 256 | 160 | 320 | 32 | 128 | 128 | |
| max pool | 3 x 3 / 2 | 7 x 7 x 832 | 0 | ||||||
| inception (5a) | 7 x 7 x 832 | 2 | 256 | 160 | 320 | 32 | 128 | 128 | |
| inception (5b) | 7 x 7 x 1024 | 2 | 384 | 192 | 384 | 48 | 128 | 128 | |
| avg pool | 7 x 7 / 1 | 1 x 1 x 1024 | 0 | ||||||
| dropout (40%) | 1 x 1 x 1024 | 0 | |||||||
| linear | 1 x 1 x 1000 | 1 | |||||||
| softmax | 1 x 1 x 1000 | 0 |
The columns #3×3 reduce and #5×5 reduce represents the number of 1×1 filters in the reduction layer used before the 3×3 and 5×5 convolutions. The number of 1×1 filters in the projection layer after the built-in max-pooling is given in the pool proj column. All the convolution layers and projection layers use rectified linear activation.
Inception V4 architecture
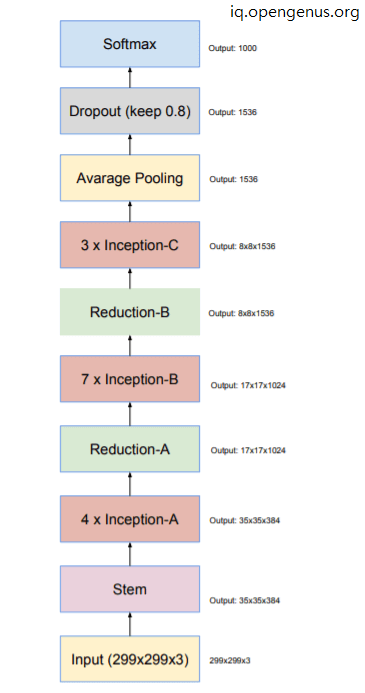
In the fourth version of the Inception model of deep convolutional neural network, the initial set of operations before the inception layer is introduced is modified. Specialized Reduction blocks are an added feature in this model which are used to change the height and width of the grid. This is explicitly added in this model whereas all the previous version had this functionality implemented. The overall schema of Inception V4 is given below.
Following is the overall InceptionV4 architecture:
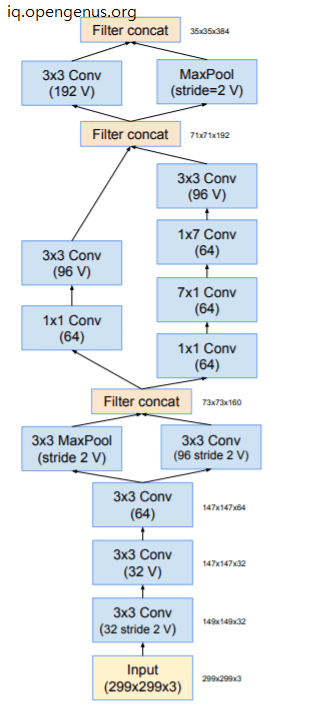
Following is the stem module in Inception V4:
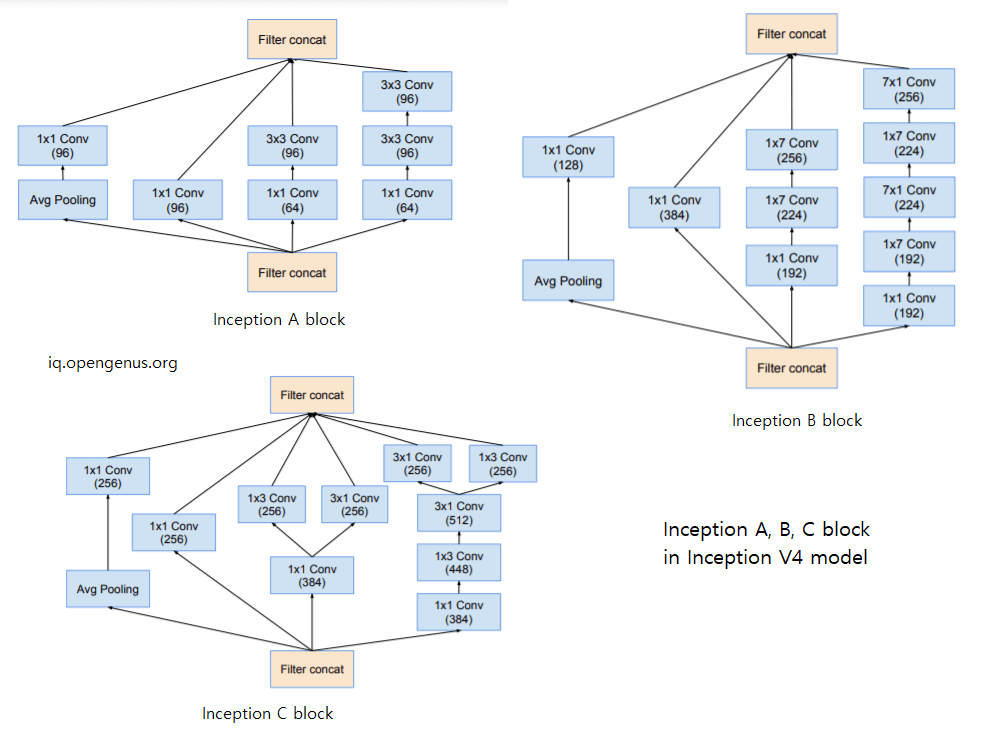
Following are the 3 Inception blocks (A, B, C) in InceptionV4 model:
Following are the 2 Reduction blocks (1, 2) in InceptionV4 model:
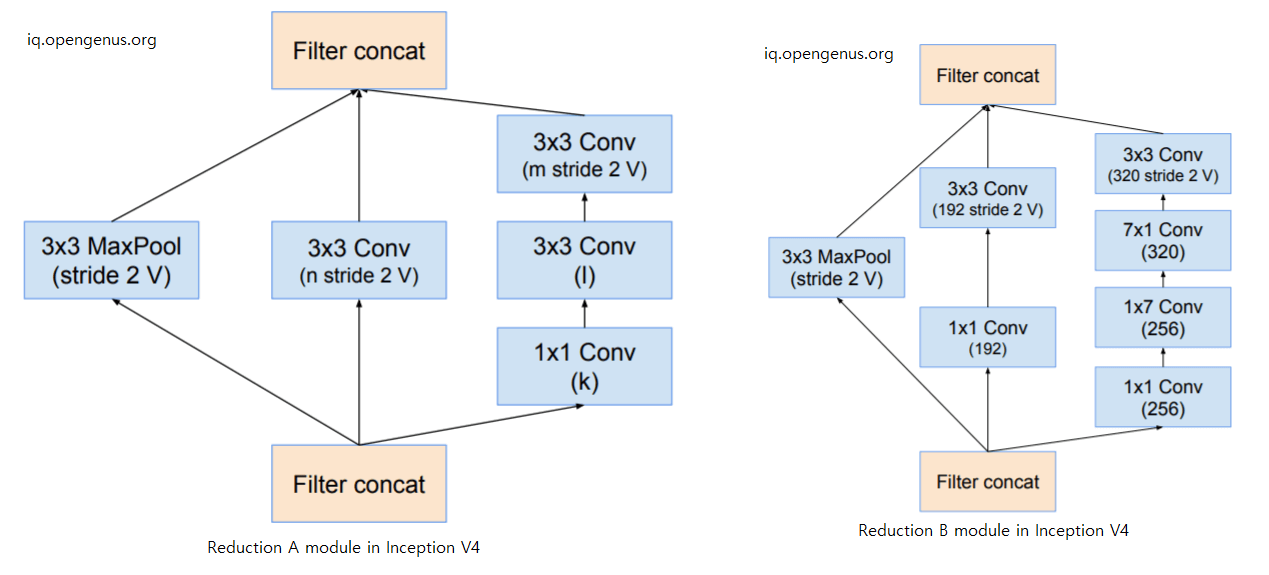
All the convolutions not marked ith V in the figures are same-padded, which means that their output grid matches the size of their input. Convolutions marked with V are valid padded, which means that the input of each unit is fully contained in the previous layer and the grid size of the output activation map is reduced accordingly.
Following is the architecture of InceptionV4 model:
| Type | Patch / stride size | Input Size |
|---|---|---|
| Stem moduel | 3×3/2 | 299×299×3 |
| 4 × Inception A | Module 1 | 35×35×384 |
| Reduction A | Moduel 1.1 | 17 x 17 x 1024 |
| 7 × Inception B | Module 2 | 17×17×1024 |
| Reduction B | Moduel 1.1 | 8 x 8 x 1536 |
| 3 × Inception C | Module 3 | 8×8×1536 |
| AvgPool | 8 × 8 | 1 x 1 x 1536 |
| Dropout | Logits | 1 × 1 × 1536 |
| Softmax | Classifier | 1 × 1 × 1000 |
Inception V4 vs previous inception models
We saw in detail about the Inception V1 or Googlenet in one of the above sections.
In the next version: Inception V2, Batch Normalization was implemented. ReLU was used as the activation function to resolve the vanishing gradient problem and saturation issues. Also the 5 x 5 conv layer was replaced by two 3 x 3 conv layers to reduce the cost.
In Inception V3, factorization was introduced in the conv layers. This means that a 3 x 3 filter was replaced by a 3 x 1 and 1 x 3 filters so that the total number of parameters goes down by 33% from 9 in the first case to 6 after factorization was implemented. A grid size reduction module was also introduced.
Inception V4 has more uniform architecture and more number of inception layers than its previous models. All the important techniques from Inception V1 to V3 are used here and its a pure inception network without any residual connections.
With this article at OpenGenus, you must have the complete idea of InceptionV4 model architecture.