
In this article, we have explored the difference between two popular string pattern searching algorithms: Knuth-Morris-Pratt (KMP) vs Boyer Moore Pattern Searching algorithm.
Before we begin to differentiate between these two pattern searching algorithms,we first go into detail about each one of them.
Knuth-Morris-Pratt (KMP) Pattern Searching algorithm
This topic is elaborately explained in the article by Piyush Mittal that can be found here : KMP Algorithm
Boyer Moore Pattern Searching algorithm
This topic is also elaborately explained in the article by Piyush Mittal that can be found here : Boyer Moore String Search Algorithm
Differences between them
- KMP Algorithm scans the given string in the forward direction for the pattern, whereas Boyer Moore Algorithm scans it in the backward direction.
- For example, in Boyer Moore, after alignment of pattern along text we start matching pattern and text character by character from right end of pattern until we get first unmatched character and then we try to align pattern to right side in such a way that the matched substring or its suffix get matched again. Given below an example, The substring "ab" is matched from right to left. After that, a non-pattern character is found to have occurred.

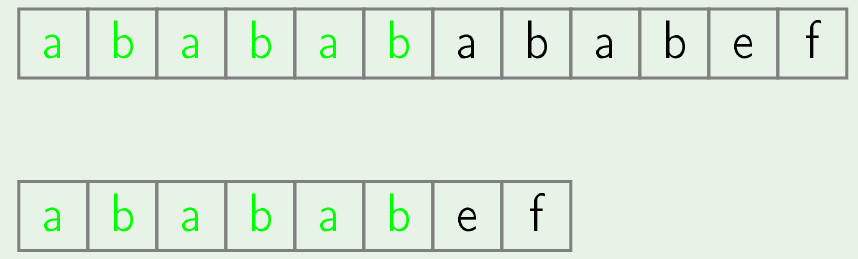
- But in case of KMP, after alignment of pattern along text we start matching pattern and text character by character from left end of pattern until we get first unmatched character.In below example, upper string is text and lower one is pattern and we search for pattern in text. In first iteration we check occurrence of pattern in text at position 0 and we found that only initial 6 characters of pattern will match when taking from left to right i.e. in forward direction.
- Scanning backwards with Boyer Moore Algorithm is sometimes faster because if we spot a character that isn't in the pattern, then we can skip many spaces forward. In the best case scenario, we may only need to compare the last character every time, and skip forward the full length of the word. However, if we were scanning forward with KMP, and spotted the non-pattern character, then we can only skip forward as far as we have matched.
- In Boyer Moore, pattern moves past matched substring. In the following situation the suffix ab has matched. There is no other occurrence of ab in the pattern.Therefore, the pattern can be shifted behind ab, i.e. to position 5.
- In KMP, in first iteration we check occurrence of pattern in text at position 0 and we found that only initial 6 characters of pattern will match.
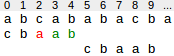
Now we will notice that border size of matched string is 4 (i.e "abab").
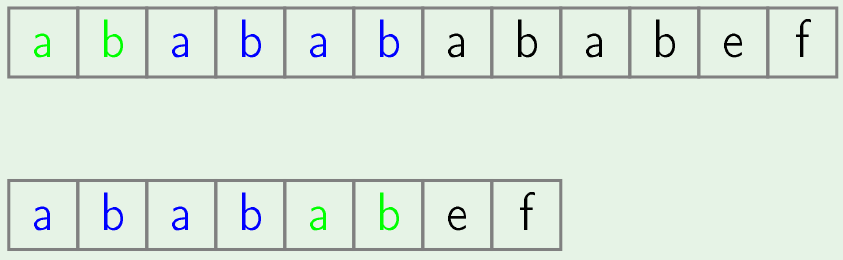
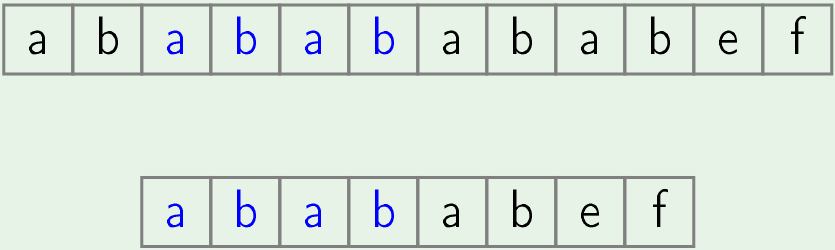
Now, we will skip second position of text and in second iteration we just start searching of pattern from 3rd position of text.
- KMP Algorithm has a guaranteed worst-case linear-time performance, i.e. both time and space complexity: O(m + n) in worst case. But, Boyer Moore can be much faster than KMP, but only on certain inputs that allow many characters to be skipped (similar to the example in the 2nd point). So it can be faster or slower than KMP depending on the given input, while KMP is perfectly reliable at O(m+n).
Now the question arises :
Which one is better ? KMP Algorithm or Boyer Moore Algorithm
- It depends on the kind of search we want to perform. Each of the algorithms performs particularly well for certain types of a search.
- Boyer Moore Algorithm : It works particularly well for long search patterns. In particular, it can be sub-linear, as we do not need to read every single character of our string.
- KMP Algorithm : It can work quite well, if your alphabet is small (e.g. DNA bases), as we get a higher chance that our search patterns contain reusable sub-patterns.
Hence, there is no definite answer to the overall best. It is rather a matter of choosing the right tool for the pattern at hand.