Research question: Is it also possible to learn useful features for a diverse set of visual tasks using any other form of supervision?
Hypothesis
Can the awareness of egomotion be used as a supervisory signal for feature learning?
Results
Yes, it is possible to learn useful features for a diverse set of visual tasks using ego motion as a supervision method.
Egomotion as supervision method compares favourably to using class-label, including the features learnt. This is on the condition that (1) the same number of training images are used and (2) on tasks of scene recognition, object recognition, visual odometry and keypoint matching.
Benefits
- Knowledge of egomotion is "freely" available unlike class labels
- Feature learning: Egomotion-based feature learning outperforms many previous unsupervised methods of feature learning on MNIST, and features learnt by class-label based supervision may not be suitable for all tasks
- Scene recognition: Egomotion based learning performs almost as well as class-label-based learning on scene recognition
- Visual odometry: Egomotion based learning outperforms class-label supervision on two orders of magnitude more data
- Keypoint matching: Egomotion based learning outperforms class-label supervision on one order of magnitude more data
Limitations
- High capacity deep models were evaluation and trained on relatively little data, and by downsizing the networks better features could have been learnt theoretically
- Standard deep models were used as this paper did not aim to explore novel feature extraction architectures, but to evaluate the use of egomotion
- There are no publicly available datasets as large as Imagenet, hence the utility of motion-based supervision cannot be evaluated across the full spectrum of training sets
Reflection on the experiment setup
Models were pretrained on a base task of egomotion, and then finetuned for target masks. Learning of better features could be achieved for the agent to have continuous access to intrinsic supervision and occassionally explicit access to extrinsic teacher signal, i.e. primarily dependent on egomotion but occassional exposure to class labels.
Purpose of choosing egomotion
Egomotion is a "freely" available type of knowledge as mobile agents are naturally aware of it through their own motor system.
It is inspired by biological agents, who also use perceptual systems to obtain sensory information about their environment. AI can be developed to use their own motor system as a source of supervision to learn useful perceptual representation, which in particular refers to (1) the ability to perform multiple visual tasks and (2) ability to perform new visual tasks by learning from a few examples labelled an extrinsic teacher.
The paper presents the hypothesis that the aforementioned useful visual representations can be learnt by correlating visual stimuli with egomotion. In other words, the computer should predict the camera transformation from consequent pairs of images.
Model for motion-based learning
The visual system of the agent was modelled with a Convolutional Neural Network. Egomotion was used as a supervision and the network model was Siamese-like. Essentially, a CNN with two streams is trained, where it takes two images as inputs and predits the egomotion undergone by the agent as it moved between the two spatial locations of the image. Both streams share the same architecture and weights, hence they perform the same set of operations for computing features.
Slow Feature Analysis was developed based on the idea that useful features change slowly in time, and the following contrastive loss formulation was used. xt in this case were features computed with a CNN, and the weights W and D were chosen to be the L2 distance. SFA pretraining used the two stream architectures, where it received input consisting of pairs of images and output xt1 and xt2 from the two streams.

The figure below demonstrates the method for feature learning. Each individual stream is referred to as a Base-CNN (BCNN) and the features from two of these are concatenated into the Top-CNN (TCNN), which predicts the camera transformation between the inpur pair of images. The TCNN is removed after pretraining as a single BCNN is used to compute features for the target task.
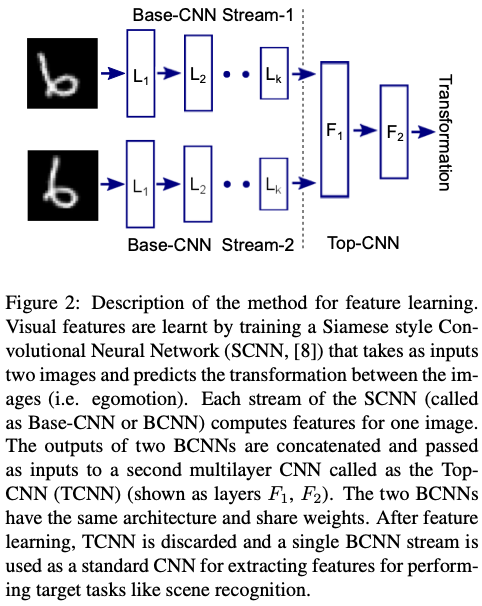
The pre-training finetuning paradigm is used to evaluate the utility of learnt features. Pretraining is the optimisation of weights for a randomly initialised CNN for an auxiliary task that is not the target task. Finetuning is the modification of the weights of a pretrained CNN for the given target task.
The experiments in the paper compare the utility of features learnt with egomotion based pretrained with that of class-label based and slow-feature based pretraining on multiple target tasks.
Methodology
Multilayer neural networks were trained for feature learning using egomotion, they were to predict the camera transformation between pairs of images. The approach is first demonstrated on the MNIST dataset. Then the efficacy of the approach is trialled on real world imagery, using image and odometry data from the KITTI and San Francisco (SF) city datasets.


Training
First, MNIST was used to generate synthetic data of random transformations, being translations or rotations, of digit images. Digits were randomly sampled from the dataset of 60K images, and transformed using two different sets of random transformations to generate image pairs. CNNs were trained to predict the transformation between the image point and this was posed as a classification task. Three softmax losses, one each for the translation along the X, Y axes and rotation about Z-axis, were to be minimised by the SCNN. A total of 5 million image pairs were used for both pretraining procedures, and the error rate of the BCNN is shown below.
For egomotion based pretraining, the TCNN: F1000-D-Op, a concatenation of the two BCNN streams, was used. The BCNN-F500-D-Op was used for finetuning. The learning rate of all the BCNN layers were set to 0 during finetuning for digit classification, so as to evaluate the quality of BCNN features. 4000 iterations were finetuned.
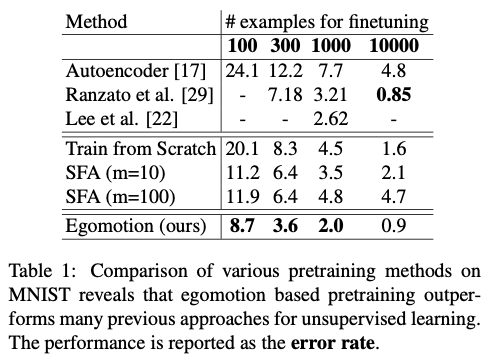
The results showed that the BCNN architecture: C96-P-C256-P was optimal for egomotion and SFA pretraining and training from scratch, where random weights were initialised. SFA-based pretraining used different values of the margin m and found that m = 10,100 led to the best performance. The method outperformed convolutional deep belief networks.
Real world testing
The visual feature learning was put into use in natural environments next using the KITTI and SF Datasets.
The former provided odometry image data. There were a total of 23201 frames recorded by 11 short trips of different lengths made by a car driving through urban landscapes. 9 of these trips were used to training and 2 for validation, and a total of 20501 images were used in the training.
The latter SF dataset provided camera transformation between 136K pairs of images, constructed from 17,357 unique images taken from Google streetview. 130K images were used for training and 6K for validation.
In both these datasets, the task of predicting camera transformation was considered a classification problem. In the former, the Z axis was the direction in which the camera pointed and the image plane was the XY plane. Frames were at most 7 frames apart so that the images would have a reasonable overlap. In the latter, there was significant camera transformation along all six dimensions of transformation, being the three euler angles and translations.
The dimensions were binned into uniformly spaced bins in both cases in response to the classification problem. The KITTI set separated the three dimensions into 20 uniformly spaced bins, and the latter binned rotations between [-30, 30] into 10 uniformly spaced bins, with two extra bins for outliers.
Evaluation and results
-
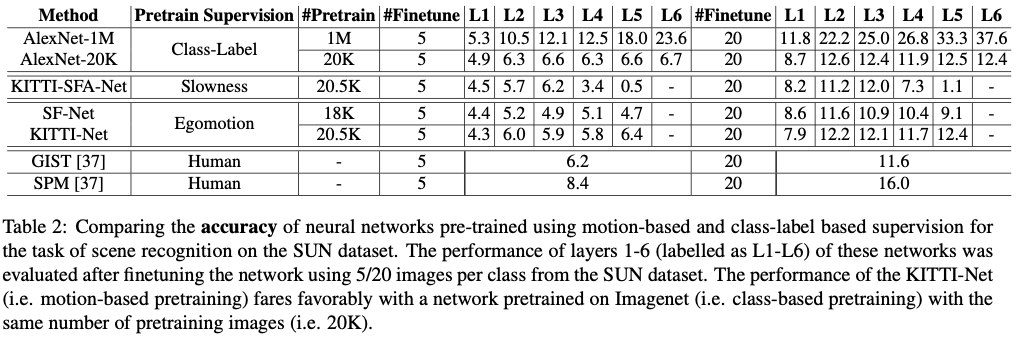
Scene recognition on SUN
SUN dataset of 397 indoor/outdoor scene categories were used to evaluate scene recognition performance. The accuracy of the networks are shown below, and with the same number of pretraining images the performance of the KITTI-Net does better.
-
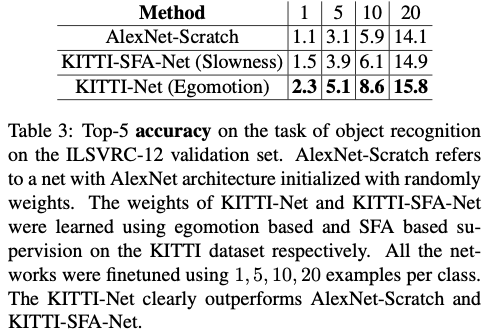
Object recognition on Imagenet
Egomotoion based supervision clearly outperforms SFA based supervision and AlexNet-Scratch as shown in the table below.
-
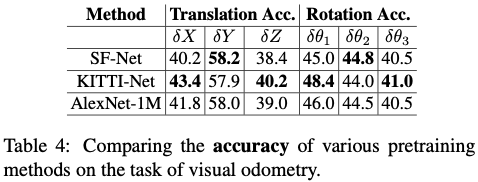
Visual odometry
Visual odometry is the task of estimating the camera transformation between pairs. Performance of KITTI-Net was superior or comparable to AlexNet-1M. On some metrics, SF-Net outperformed KITTI-Net, but this can be explained as the evaluation was made on the SF dataset itself.
-
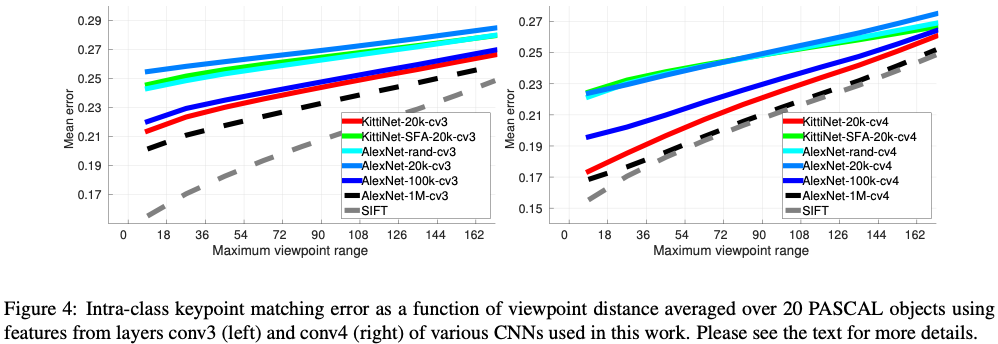
Intra-Class key-point matching
The accuracy would depend on the camera transformation between the two viewpoints of the object, i.e. the viewpoint distance.