
In this article, we have explored the idea of MapReduce tool in depth and how it is used in System Design.
Table of contents:
- MapReduce Overview
- Top 3 Stages of MapReduce
- Advantages of MapReduce
- MapReduce Applications
- Alternatives and limitations
- Conclusion
MapReduce Overview
Hadoop's MapReduce processing engine processes and computes huge amounts of data. It enables businesses and other organizations to perform calculations in order to:
• Determine the most profitable price for their items.
• Understand how effective their advertising is and where their ad money should be spent.
• Make weather forecasts
• Analyze site clicks, retailer sales data, and Twitter hot topics to figure out what new products the company should release in the coming season.
These calculations were difficult before MapReduce. Problems like these are now quite simple for programmers to solve. Complex algorithms have been coded into frameworks so that programmers can use them.
MapReduce runs across a network of low-cost commodity devices, so companies don't require a whole department of Ph.D. scientists to model data, nor do they need a supercomputer to handle enormous volumes of data.
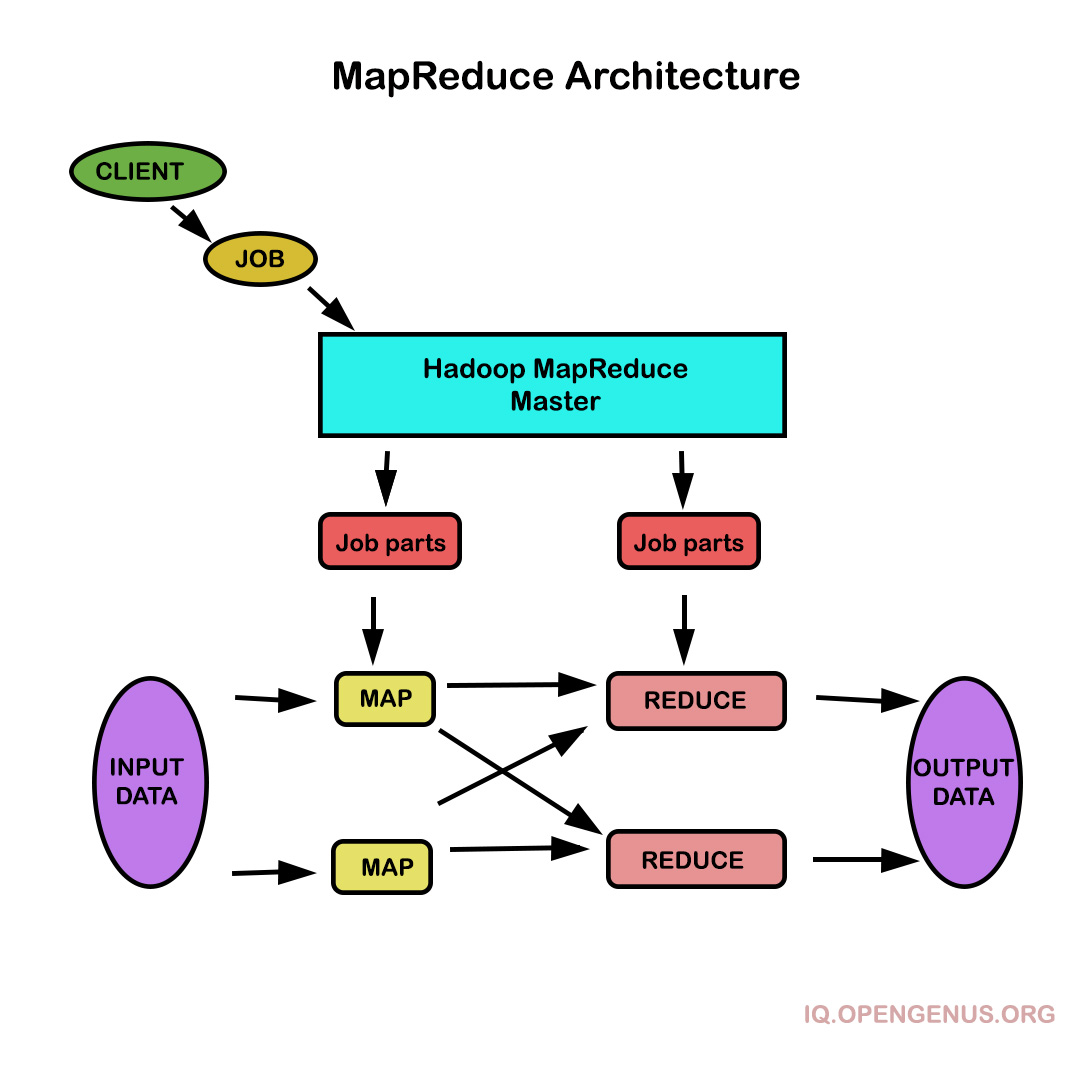
Top 3 Stages of MapReduce
Top 3 Stages of MapReduce:
- Map Stage
- Reduce Stage
- Shuffle and Sort
Map Stage
The map's or mapper's job is to process the data that is given to them. In most cases, the input data is stored in the Hadoop file system as a file or directory (HDFS). Line by line, the input file is supplied to the mapper function. The mapper divides the data into little bits and processes it.
Reduce Stage
This level is the result of combining the Shuffle and Reduce stages. The Reducer's job is to take the data from the mapper and process it. It generates a new set of outputs after processing, which will be stored in the HDFS.
Let's take a closer look at each of the phases and try to figure out what they mean.
In the input phase, we have a Record Reader that parses each record in an input file and passes the data to the mapper as key-value pairs.
Map is a user-defined function that takes a list of key-value pairs and processes each one to produce zero or more key-value pairs.
Intermediate Keys The intermediate keys are the key-value pairs generated by the mapper.
A combiner is a form of local Reducer that organizes related data from the map phase into distinct sets. It accepts the intermediate keys from the mapper as input and aggregates the values in a narrow scope of one mapper using a user-defined function. It is an optional component of the core MapReduce algorithm.
The Shuffle and Sort step is the first stage in the Reducer task. The aggregated key-value pairs are downloaded to the local machine where the Reducer is operating. In a larger data list, the individual key-value pairs are sorted by key. The equivalent keys are grouped together in the data list so that their values may be iterated conveniently in the Reducer process.
Reducer takes the grouped key-value paired data as input and applies a Reducer function to each of them. The data can be aggregated, filtered, and integrated in a variety of ways here, and it necessitates a variety of processing. When the execution is complete, the final step is given zero or more key-value pairs.
MapReduce's strength is in its ability to handle large data sets by distributing processing across many nodes and then combining or reducing the output.
Advantages of MapReduce
1. The ability to scale
Hadoop is a highly scalable platform, owing to its capacity to store and distribute big data sets across a large number of computers. The servers utilized here are quite low-cost and can run in parallel. With the addition of new servers, the system's processing power can be increased. Traditional relational database management systems, or RDBMS, were incapable of processing large data sets at scale.
2. Flexibility
The Hadoop MapReduce programming style allows diverse business entities to process structured and unstructured data and work on multiple forms of data. As a result, they can derive a business value from such significant and valuable data for analysis by business organizations. Hadoop supports a variety of languages for data processing, regardless of the data source, such as social media, clickstream, email, and so on. In addition, Hadoop MapReduce programming enables a wide range of applications, including marketing research, recommendation systems, data warehouses, and fraud detection.
3. Security and Authentication
If an outsider got access to all of the organization's data and is able to change numerous petabytes of data, it can cause significant damage to the company's business operations. The MapReduce programming architecture mitigates this danger by integrating with hdfs and HBase, which provide excellent security by enabling only authorized users to access the system's data.
4. A Budget-Friendly Option
Such a system is extremely scalable and a cost-effective solution for a business strategy that requires the storage of data that grows exponentially in response to current needs. In terms of scalability, prior traditional relational database management systems were not as easy to process the data as the Hadoop system. In such circumstances, the company was obliged to reduce the data and implement classification based on assumptions about how important specific data could be to the company, resulting in the removal of raw data. Hadoop's scaleout design and MapReduce programming come to the rescue in this case.
5. Fast
Hadoop is an open-source distributed file system. HDFS is a fundamental Hadoop feature that essentially implements a mapping system for locating data in a cluster. The tool for data processing is MapReduce programming, which is also located on the same server, allowing for faster data processing. Hadoop MapReduce accelerates the processing of massive amounts of unstructured or semi-structured data.
6. Programming Model in Its Most Basic Form
MapReduce programming is built on a relatively simple programming model that enables programmers to create MapReduce programs that can handle many more tasks with greater simplicity and efficiency. The MapReduce programming model is developed in Java, which is a popular and easy-to-learn programming language. Learning Java programming and designing a data processing model that matches their business goals is simple.
7. Parallel Processing
The programming model divides the tasks such that the independent tasks can be completed in parallel. As a result of the parallel processing, it is easier for the processes to take on each of the jobs, allowing the program to run in much less time.
8. Availability and Resilience
The Hadoop MapReduce programming model processes data by sending it to a single node and then forwarding the same piece of data to the rest of the network's nodes. As a result, in the event of a node failure, the identical data copy is still available on the other nodes, which may be accessed whenever needed, assuring data availability.
Hadoop is fault-tolerant in this sense. This is a unique feature of Hadoop MapReduce in that it may immediately identify a problem and apply a short remedy for an automatic recovery solution.
Map-reduce is used by many companies around the world, including Facebook, Yahoo, and others.
One issue with MapReduce is the infrastructure it necessitates in order to function. Many companies that could profit from big data jobs can't afford the capital and overhead required to build such a system. As a result, some businesses rely on public cloud Hadoop and MapReduce services, which provide massive scalability with low capital and maintenance costs.
Amazon Web Services (AWS), for example, offers Hadoop as a service via its Amazon Elastic MapReduce (EMR) offering. Users can utilize Microsoft Azure's HDInsight service to provision Hadoop, Apache Spark, and other clusters for data processing activities. Google Cloud Platform's Cloud Dataproc offering allows Spark and Hadoop clusters to be run.
Hadoop and MapReduce are only one choice for enterprises that choose to construct and operate private, on-premises big data infrastructures. Other systems, including as Apache Spark, High-Performance Computing Cluster, and Hydra, are available for deployment. The sort of processing jobs required, available programming languages, and performance and infrastructure constraints will all influence which big data framework an organization picks.
MapReduce Applications
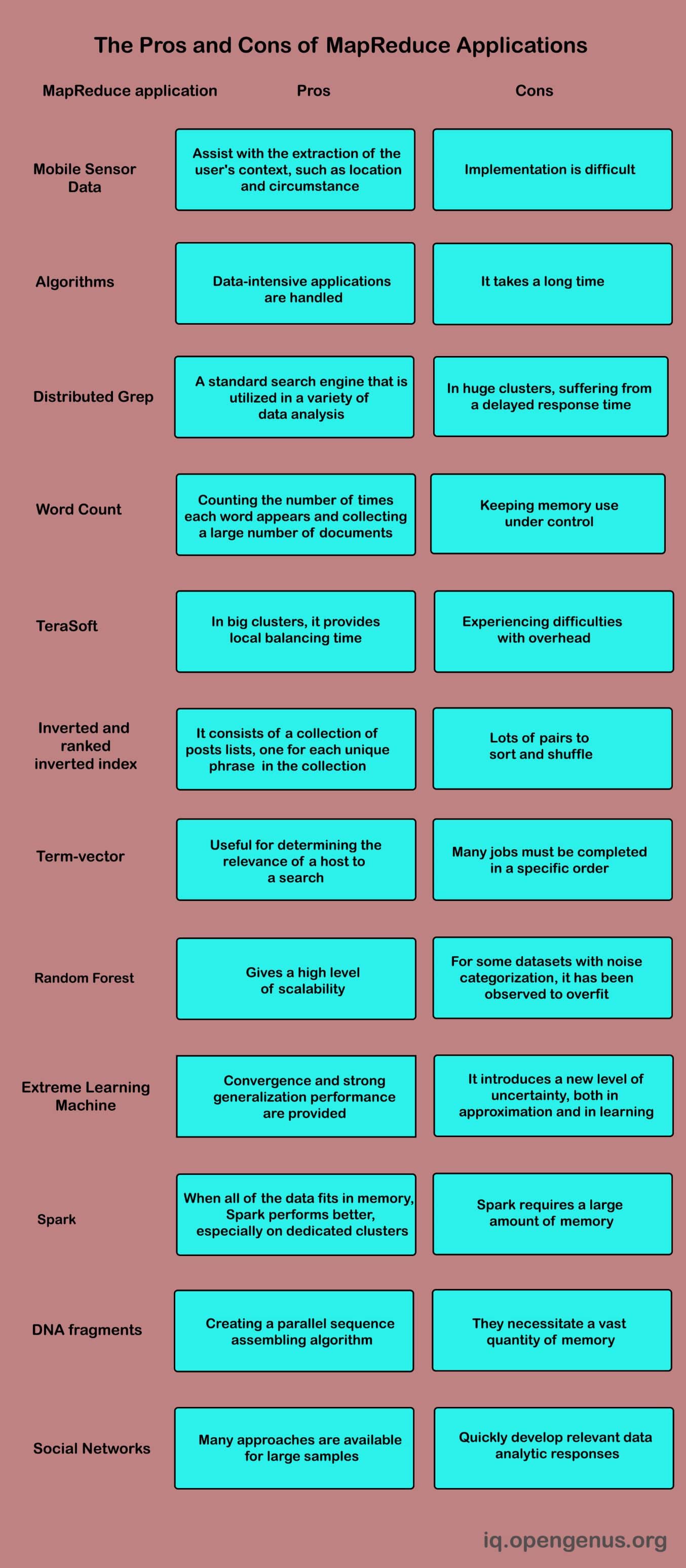
The MapReduce application speeds up the execution of several data-parallel applications. MapReduce is a key component in a number of critical applications, and it may boost system parallelism. For data-intensive and computation-intensive applications on machine clusters, it receives a lot of attention. It is utilized as an efficient distributed computation tool for a variety of issues, such as search, clustering, log analysis, various forms of join operations, matrix multiplication, pattern matching, and social network analysis; it enables researchers to look into many topics. Many big data applications use MapReduce, including short message mining, genetic algorithms, k-means clustering algorithm, DNA fragment, intelligent transportation systems, Healthcare scientific applications, Fuzzy rule based classification systems, heterogeneous environments, cuckoo search, extreme learning machine, Random Forest, energy proportionally, Mobile Sensor Data, and semantic web.
A quick look at the many types of MapReduce applications:
Distributed Grep
Distributed Grep looks for lines that match a regular expression in plain-text data collections. It's used to search through a huge number of files for a certain pattern.
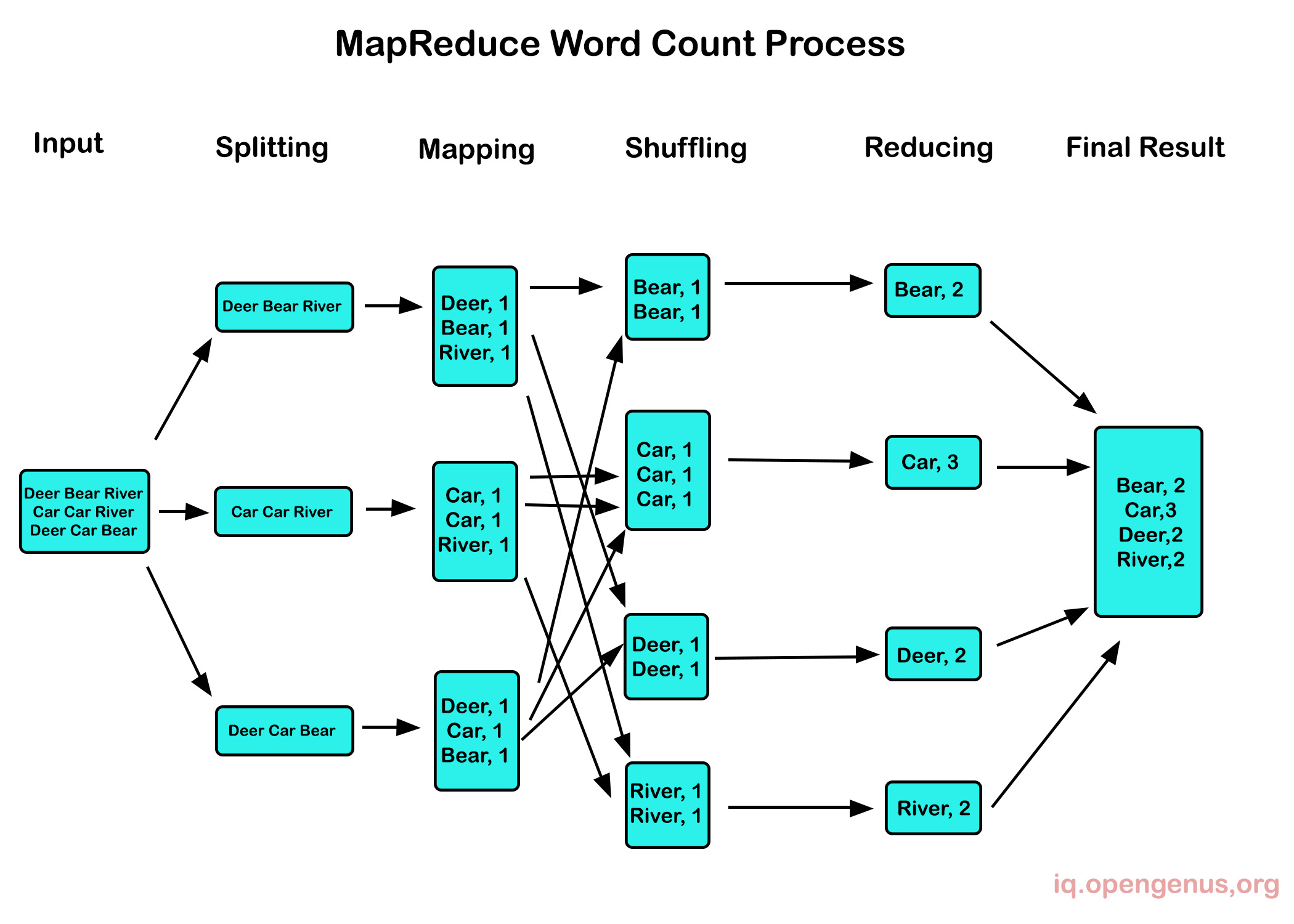
Word Count
Word count is a MapReduce application that counts the number of times each word appears in a huge text collection and extracts a tiny bit of data from it.
TeraSort
TeraSort is a MapReduce sorting method using a custom Reducer that accepts a sorted list of N – 1 sampled keys with preset ranges for each reducer.
Inverted and Ranked Inverted Index
An inverted index is a type of index that stores a mapping between information, such as words or numbers, and their placement in a database file or document.
Term-Vector
A MapReduce describes the most frequently occurring terms in a host, which is important for determining a host's relevance to a search.
Random Forest
In classification, prediction, researching variable relevance, variable selection, outlier detection, and classification, random forests (RF) is particularly popular.
Spark
Spark, as a cluster computing platform, can run applications using working sets and has similar scalability and fault tolerance as MapReduce. It's utilized to keep MapReduce's scalability and fault tolerance by using a concept called resilient distributed datasets (RDDs). A read-only group of items split by a set of machines that can be recreated if a partition is lost is known as an RDD. Spark's fundamental concept is to build a resilient distributed dataset (RDD), which is a read-only collection of items kept in memory between iterations and facilitates fault recovery.
Extreme Learning Machine
Due to its quick convergence and high generalization performance, the extreme learning machine (ELM) has gained traction in numerous research disciplines in MapReduce framework applications.
DNA Fragment
An organism's genetic information is stored in a DNA sequence. To comprehend the structure of an organism, the whole sequence of DNA must be obtained, as well as a grasp of the structure and composition of a gene. DNA sequence data processing is based on sequence assembly technology.
Mobile Sensor Data
Mobile phones have a variety of sensors, such as an accelerometer, magnetic field sensor, and air pressure meter, that aid in the extraction of situational information about the user, such as location, state, and so on. One of the major tasks is to upload to the public cloud the sensor data that has been retrieved from mobile devices. The use of MapReduce in the cloud for parallel computing for training and detection of human activities from accelerometer sensor data relies on classifiers that can readily scale in performance and accuracy. Its goal is to identify and forecast human activity trends.
Social Media Sites
The Social Networks Service (SNS) is growing in popularity, with an exponential increase in the number of empirical research conducted in this dynamic subject. Due to the rapid growth of the network, typical analytical methodologies are no longer appropriate. The MapReduce framework may tackle the challenge of large-scale social network analysis by utilizing the capability of multi-machines that are capable of processing large-scale social network data.
Algorithms
Algorithms play a crucial role in the development and engineering of software and applications. They've always been important in the field of computer science. Most computer sciences, including networks, databases, web technologies, and core programming, rely on algorithms; without them, none of them would function.
In the era of big data, with a vast amount of digital data, the topic of human concerns and future research possibilities continues. Big data and large-scale data processing techniques have risen to prominence in recent years. Big data applications drive innovation in a variety of large-scale data management systems in a variety of companies, ranging from established database suppliers to new Internet-based startups. MapReduce is a cloud computing supporting technology. The MapReduce paradigm and big data systems are now under investigation.
Alternatives and limitations
MapReduce is not well adapted for iterative algorithms like those used in machine learning because of its constant data shuffling (machine learning).
The following are some alternatives to standard MapReduce that try to mitigate these bottlenecks:
- Amazon EMR - High-level management for distributed frameworks like Hadoop, Spark, Presto, and Flink operating on the AWS (Amazon Web Services) platform.
- Flink is an open-source framework for processing partial or in-transit data streams. Apache-developed optimization for huge datasets.
- Google Cloud Dataflow - GCP data processing on a distributed scale (Google Cloud Platform).
- Presto is a distributed SQL query engine for large data that is open-source.
Conclusion
In the context of huge data, MapReduce programming has various advantages. It helps organizations to process petabytes of data stored in the HDFS and makes multiple data sources and data kinds more accessible. It leads to faster processing of large volumes of data due to parallel processing and little data transportation. Above all, it's simple to use and allows programmers to use a variety of languages, including Java, C++, and Python.
In most research, MapReduce has shown to be efficient and scalable. It is used to generate and handle large amounts of data in a variety of applications. The MapReduce framework's applicability in many environments, including the cloud, multi-core systems, and parallel processing, have been thoroughly examined.
The MapReduce Framework's purpose is to offer a layer of abstraction between fault tolerance, data distribution, and other parallel system duties, as well as the implementation of aspects of certain algorithm. Clearly, the demands of MapReduce applications are growing dramatically.