
In this article, we will explore the basics of data replication techniques such as Master-slave and Master-master in databases.
Table of Contents
- Data Replication
- Ways of Updating Data
- Synchronous update
- Asynchronous update
- Master-slave model
- Master-master model
Data Replication
Data replication is the process of creating multiple copies of the same data at different places. But why? Why do we need to replicate our data? Well, there can be several reasons why data needs to be replicated.
Imagine if we store all our data in a single database and that database crashes. All our data would be lost and our applications would become unusable. Another example is to imagine if there are millions of queries to our database at the same time. This is not uncommon in large internet companies like Google, Amazon, etc. A single database would not be able to handle all the queries. By replicating the data in multiple databases we can solve this problem.
Keeping the data at multiple geographical locations around the globe can reduce latency and improve the performance of our system. In a nutshell, Database replication ensures high availability and fault tolerance.
Ways of Updating Data
Now the question arises, how do we keep the data consistent? or in other words, how do we ensure that when data in one database is changed, that change is reflected on all the other databases? There are 2 ways of going about it.
Synchronous Update:
In synchronous replication, any change to one of the databases is immediately propagated to all the other replicas. Only after all the databases have been updated further queries are handled. An update operation is complete only when all the databases have been updated. This method ensures that the data always stays updated and ensures no data loss.
The downside to synchronous replication is that we need to wait for all the replicas to be updated before moving on. Hence the write, delete, update operations consume more time. But incase a single node fails, recovery would be pretty easy as all the nodes are updated to the latest data.
Asynchronous Update:
In an asynchronous or lazy update, all the replicas are not updated at the same time. Changes are queued and the update is done only at a few specific intervals. An update operation is considered complete the moment it is finished on one database.
The advantage of asynchronous replication is that operations are much quicker than synchronous updates. But the downside is that if the database which contains the updated data goes down before the change is propagated then the data is lost.
Both ways of replication may be used depending upon the business scenario.
Master-slave Model
In a Master-slave model, there is only one primary database called the Master and several secondary databases called slaves. Write and update operations can only be performed on the master database but read operations can be performed on the slave databases as well.
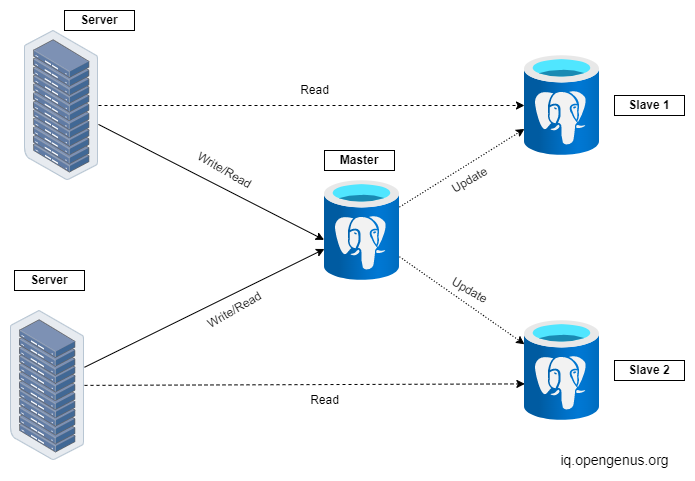
Since the master updates the slaves this model ensures consistency of data among different replicas. If one of the slaves crashes, it can reboot and sync with the master very easily.
But what happens if the master itself goes down? In this scenario, The most recently updated slave is made master. However, if the update configuration is asynchronous then loss of data may occur since the changes may not have been propagated to the slaves yet and thus reducing durability.
This model is best when you have to do a lot of read operations but only a few write operations. For example A streaming service like Netflix, where the data (ie., Movies) have to be written only once but have to be read (ie., streamed) many times by users.
A load balancer is used to split the query traffic among different databases.
Master-master Model
A Master-master model or also known as Multi-master replication is one in which all the nodes are primary. That is all the databases and be read from and written to. Each database propagates its changes to every other database replica so that the system stays consistent.
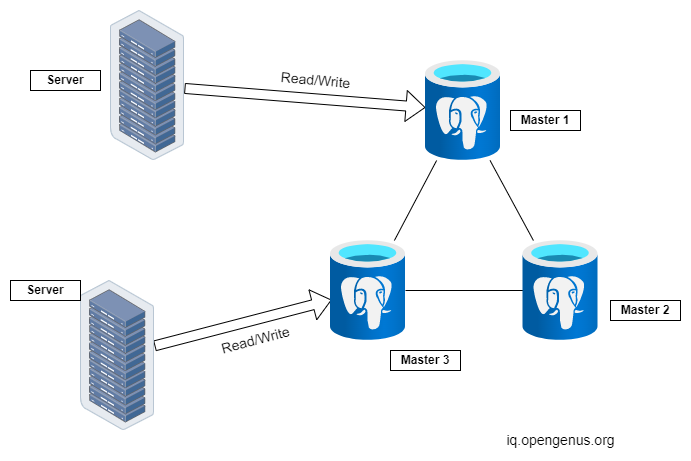
Conflicts may arise if two databases are updated concurrently. The databases may come to a stable state by communicating with each other and using some consensus algorithms or the final decision may be done based on the timestamp of the update. The latest update is kept and the rest are discarded.
Since data is can be read and written to at multiple sites this model is more flexible than the Master-slave model. Even if one of the databases goes down the other masters can be used to update the database.
On the other hand, if the system is asynchronous then if one of the databases goes down, it can lead to an inconsistent state. Also, Master-master systems are very complicated because of the need for conflict resolution which only becomes worse as the number of databases increases.
Master-master model is used for more mission-critical applications and applications that involve a lot of writing. For example A social media website like Twitter where the new tweets have to be written to the database and also continuously read from the database to be displayed on the user's feed.
Most of the databases available today like MySQL, Oracle, PostgreSQL, etc. support both Master-slave and Master-master configuration.
With this article at OpenGenus, you must have the complete idea of Master-slave & Master-master replication in Databases.