
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
By definition, Native language identification (NLI) is the task of determining an author's native language based only on their writings or speeches in a second language. This is an application of Machine Learning. Let us break this down to know what this actually means.
English is a language which is widely used throughout the word. But not all of them who write or speak english are native language speakers. This means that whenever anybody who is not a native english speaker writes or speaks in english language, his speaking and writing tend to be different from the one whose native language is english. This is because his native language tend to affect his writing and speaking style in a different way from an native speaker. For example, an Indian man speaking or writing english is generally different from one whose native language is english. Interestingly, his speaking or writing also tend to be different from, say, a chinise person. So, we can say that every region has its own style or writing or speaking english.
NLI is a field of Natural Language Processing which deals which identifying these subtle differences between non-native speakers. NLI is based on the assumption that the mother tongue (Hindi for Indian or Arabic for Arabs) influences second language acquisition and production (For example, English).
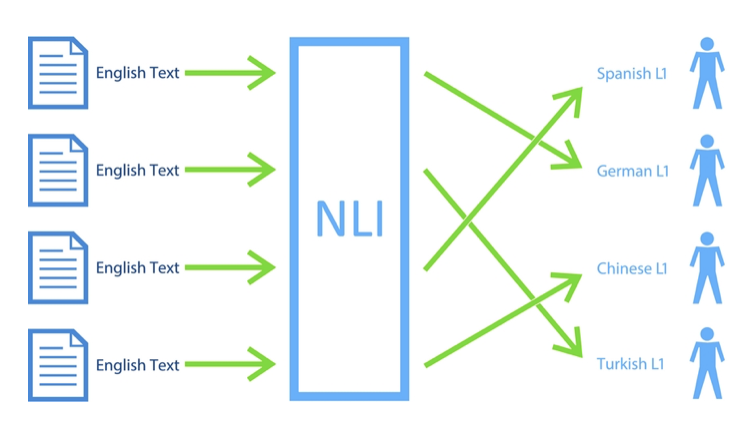
Why to study NLI?
There are two important reasons to study NLI.
Firstly, there is second language acquisition. NLI methods can be used to investigate the influence of native language in foreign language acquisition and production. For example, for an Indian person, how hindi affects his ability to read and write english. What inflections does it introduces in his english language.
Second reason might be a practical one. NLI can be used in Forensic linguistics. For example, it can identify the background and attributes of an author or can identify the native country of the author of an anonymous note.
Methodology for NLI
NLI can be approached as a kind of text classification. In text classification, decisions and choices have to be made at two
levels.
- First, what features should we extract and how should we select the most informative ones?
- Second, which machine learning algorithms could be used for NLI?
Let us dive in these two questions.
Features
- One feature can be n-grams where 'n' can be any natural number. An n-gram is a contiguous sequence of 'n' items from a given sample of text. It means for a word that we are looking, how does it depend on previous 'n' words. We carry this process for all the words. So, if 'n' is 3, that means we will look at 3 previous words for an word 'w' in the text. It is an important feature which is generally used in NLI and is proven to give good results not only in this field but also in general text classification. NLTK library has a function "nltk.ngrams(text,n)", where 'n' corresponds to how many words should a words depend (i.e., n=1 for unigram or n=2 for bigram).
Image shows different n-grams (1(uni) ,2(bi),3(tri)). So, for example, in tri-gram, "a swimmer likes" or "swimmer likes swimming" is considered as a feature.

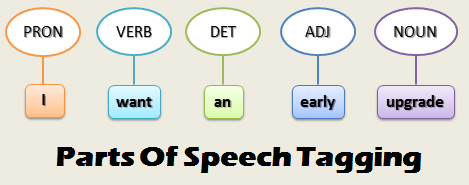
- Another feature can be Part-of-Speech (PoS) tagging, which may be defined as the process of assigning one of the parts of speech to the given word. In simple terms, we need to assign each word in the text with a particular tag. These tags include nouns, verb, adverbs, adjectives, pronouns, conjunction and their sub-categories. NLTK library has a function "nltk.pos_tag(text)"
which divides each word in "text" and associates them with a tag.
- Spelling errors can also be treated as features i.e., words that are not found in standard dictionary. This is because people of some specific country or region might use some lingo that is not prevalent in english langauge.
All the features, consisting of either characters or words or part-of-speech tags or their combinations, etc that are mapped into normalized numbers (norm L2). For the mapping, popular technique is to use TF-IDF, a weighting technique. It automatically gives less weight to words that occur in all the classes or words that have very high frequency (such as a, an, the, etc) and assigns higher weight to words that occur in few classes i.e., words that helps in discriminating classes. In simple terms, TF gives more weight to a frequent term in the text and IDF downscales the weight if the term occurs in many text.
Classifiers
Now, the task is to classify the text into respective country/region. We need algorithms that are suitable for sparse data and high dimensional(text data is high dimensional and sparse). One such prominent algorithm is Support Vector Machines (SVMs). SVM have been explored systematically for text.
categorization. An SVM classifier finds a hyperplane that separates examples into classes with maximal margin. Other classifiers such as neural networks could be tried for NLI. The output of any of these classifiers would be the number of languages we wanted to classify. For example, if you are given english texts of an Indian, Chinise and a Japanese person, the output of a classifier would be 3.
A range of ensemble based classifiers have also been applied to the task and shown to improve performance over single classifier systems.
Is there any dataset which could be used to implement the above or any other method?
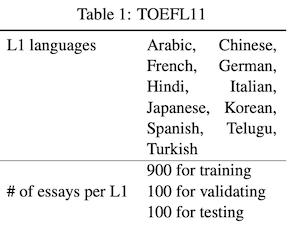
Yes! It is TOEFL11. It consists of 12,100 English essays (about 300 to 400 words long) from the Test of English as a Foreign Language (TOEFL). The essays are written by 11 native language speakers shown in the table below.
Some reseach papers that will help in undertanding NLI further
- http://ceur-ws.org/Vol-2036/T4-5.pdf
- https://www.aclweb.org/anthology/W13-1714.pdf
- https://www.aclweb.org/anthology/R15-1040.pdf
- https://arxiv.org/pdf/1707.07182.pdf
With this article at OpenGenus, you must have a strong understanding of the overview of Native Language Identification (NLI). Enjoy.