
Get this book -> Problems on Array: For Interviews and Competitive Programming
CNN (Convolutional Neural Network) is the fundamental model in Machine Learning and is used in some of the most applications today. There are some drawbacks of CNN models which we have covered and attempts to fix it.
In short, the disadvantages of CNN models are:
- Classification of Images with different Positions
- Adversarial examples
- Coordinate Frame
- Other minor disadvantages like performance
These disadvantages lead to other models/ ideas like Capsule neural network. We have explained the points in depth.
Overview Of Convolutional Neural Network
A convolutional neural network / ConvNet / CNN is a neural network which is made up of neurons and learnable parameters like weights. Each neuron receives many inputs, they then take the weighted sum of the inputs and pass it through an activation function and receive an output. They are used in the field of computer vision and have helped in forming many different applications such as LeNet, AlexNet, VGG etc.
The idea of ConvNet was inspired from the connectivity of the neurons present in the brain.
The Convolutional Layers
A Convolutional Layer is a layer present in the ConvNet which is used to extract features (edges,corners,endpoints etc) from the image which is provided as an input. It is a set of matrices which get multiplied with the previous layer output ,the process is known as convolution.
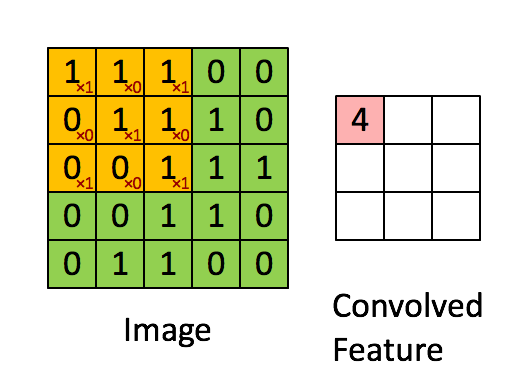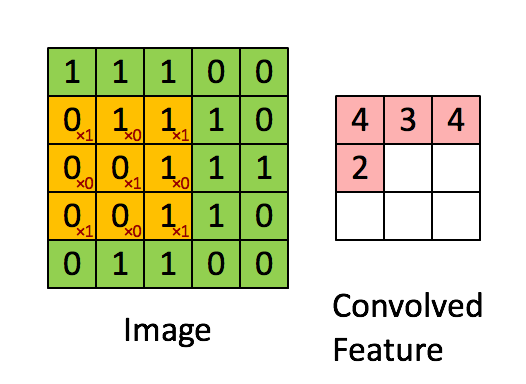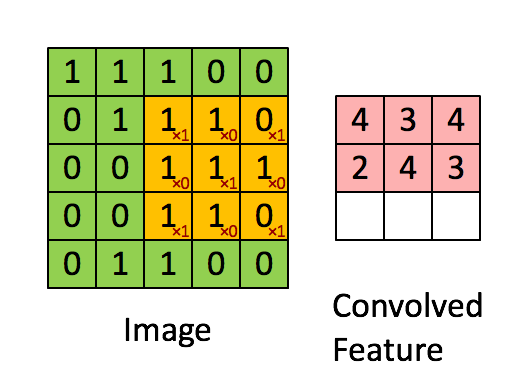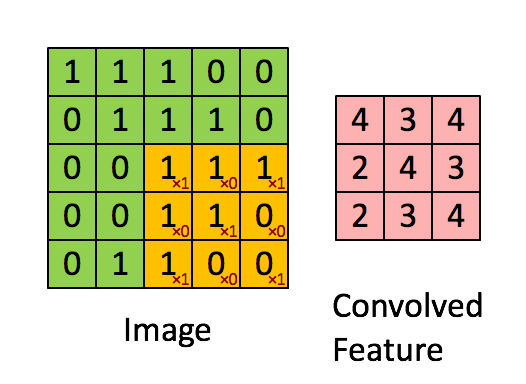
The Drawbacks with CNN:
Classification of Images with different Positions:
One of many challenges in the field of computer vision is to deal with the variance in the data present in the real world. Human visual system can identify images :
1. Under different angles
2. Under different backgrounds
3. Under several different lighting conditions.

[Figure 1] : Same image under different light, angle and shade
When the objects are hidden to a certain extent by other objects or coloured, the human visual system finds signs and other pieces of information to identify what we are seeing.
Creating a ConvNet which has the ability to recognize objects at the same level as humans has been proven difficult..Regardless of where the object is present in the image a well trained ConvNet can identify the object present in the image. But if the object in the image consists of rotations and scaling then the ConvNet will have a hard time identifying the object in the image.
Convolutional Neural networks (CNN) have great performance while classifying images which are very similar to the dataset . However, If the images contain some degree of tilt or rotation then CNNs usually have difficulty in classifying the image (refer to Figure 1). This can be solved by adding different variations to the image during the training process otherwise known as Data Augmentation.
One of the most renowned image Dataset known as ImageNet,(14 mil 200 classes with 500 images for each class) which also sets the standard for providing the most images for training in computer system visions has proven to be flawed as it fails to capture all the different angles and positions of the image as it contains images under ideal lighting and angles.
The classification process of a Convolutional neural network (CNN) is performed in detail. The layers which are present closer to the input in the ConvNet help in classifying simple features such as edges,corners,endpoints etc. On the other hand, layers which are present on the deeper level classify the simple features into complex features. At the end , the top layer combines all the complex features and makes a prediction.
In the convolutional layer , all minute detail recognition is done by high level neurons.
These high level neurons then check if all features are present. The process of checking whether features are present is done by striding the image. During this process the ConvNet completely loses all the information about the composition and position of the components and they transmit the information further to a neuron which might not be able to classify the image.
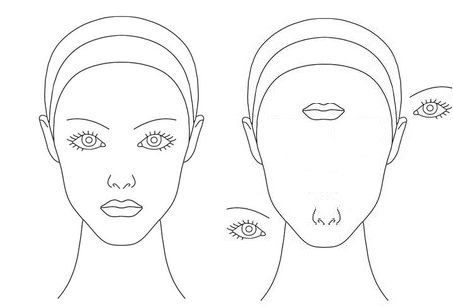
[Figure 2] : (This figure illustrates the dismantled components of a face)
To a CNN both the above pictures are almost similar as both contain the same contents. In the rightmost image above, we see 2 eyes, 1 nose and a mouth but this doesn't necessarily indicate that there is a face. Thereby the importance lies in understanding the certain position of the objects present in the image which the CNN is unable to identify.
This problem could be solved using “data augmentation”. Data augmentation usually revolves around a process where we flip the image or rotate it by small amounts in order to train the dataset. This results in the CNN training with multiple images.
But data augmentation doesn't solve the worst case scenario as real life situations have complex pixel manipulation like a crumpled T-shirt or an inverted chair.
In summary, CNNs make predictions on the basis of the fact that whether or not a specific component is present in the image or not. If the components are present then they classify that image accordingly.
Adversarial examples
From the above drawbacks, it is certain that CNNs recognize the images in a different sense from humans and the need for more training Augmented data won’t solve the problem of learning the object.
If the CNN takes an image along with some noise it recognizes the image as a completely different image whereas the human visual system will identify it as the same image with the noise. This also proves that CNNs are using very different information from a regular visual system in order to recognize images.
The slightly modified images are also known as “adversarial examples”
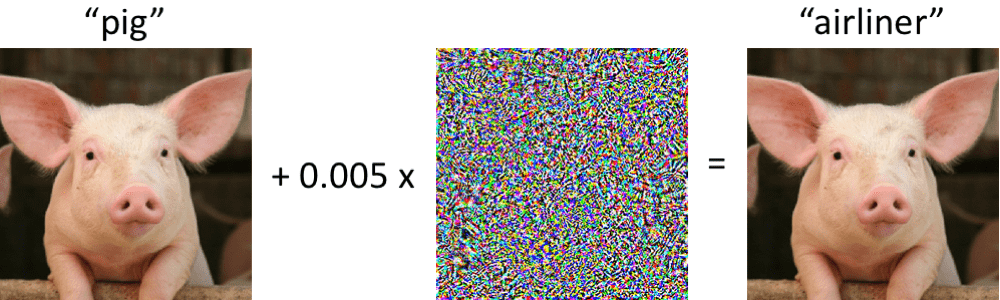
Coordinate Frame
Convolutional networks recognize the image in terms of cluster of pixels which are arranged in distinct patterns and do not understand them as components which are present in the image. The images as visualized by CNN do not have any internal representations of components and their part-whole relationships.
CNNs do not have coordinate frames which are a basic component of human vision(refer to Figure-3).Coordinate frame is basically a mental model which keeps track of the orientation and different features of an object. For example, if we look at the following figure we can identify that the image on the right, if turned upside-down will give us the image on the left. Just by mentally adjusting our coordinate frame in the brain we are able to see both faces, irrespective of the picture’s orientation.This is where the human Coordinate frame enables humans to see both the faces.

[Figure-3]: (This figure illustrates a two different precepts of the same image)
Humans possess multiple percepts whereas a Convolutional neural network consists of only one percept and that percept doesn't depend on the coordinate frames imposed.
Minor Drawbacks of CNN:
-
A Convolutional neural network is significantly slower due to an operation such as maxpool.
-
If the CNN has several layers then the training process takes a lot of time if the computer doesn’t consist of a good GPU.
-
A ConvNet requires a large Dataset to process and train the neural network.
Conclusion:
The above were the drawbacks which are generally found in a convolutional neural network. The drawbacks were taken into consideration and fueled further research which led us to the idea of “Capsule neural network.”
Geoffrey Hinton had originally found the idea for a capsule network.
The paper on capsule network by Geoffrey Hinton: arxiv.org/pdf/1710.09829v2
With this article at OpenGenus, you must have the complete idea of disadvantages of Convolutional Neural Network (CNN). Enjoy.