
Reading time: 35 minutes
Our brain processes things in a pictorial fashion. It tries to look for features and identify or classify objects in our surroundings. Since, our aim with neural networks is to mimic the human brain, a convolutional neural network (CNN) is mechanised such that it looks for features in an object.
Convolutional Neural Network (CNN) is an neural network which extracts or identifies a feature in a particular image. This forms one of the most fundamental operations in Machine Learning and is widely used as a base model in majority of Neural Networks like GoogleNet, VGG19 and others for various tasks such as Object Detection, Image Classification and others.
CNN has the following five basic components:
- Convolution : to detect features in an image
- ReLU : to make the image smooth and make boundaries distinct
- Pooling : to help fix distored images
- Flattening : to turn the image into a suitable representation
- Full connection : to process the data in a neural network
A CNN works in pretty much the same way an ANN works but since we are dealing with images, a CNN has more layers to it than an ANN. In an ANN, the input is a vector, however in a CNN, the input is a multi-channelled image.
Convolution
Convolution is the fundamental mathematical operation that is highly useful to detect features of an image. Convolution preserves the relationship between pixels by learning image features using small squares of input data. It is a mathematical operation that takes two inputs:
- image matrix
- a filter
Consider a 5 x 5 whose image pixel values are 0, 1 and filter matrix 3 x 3 as shown in below
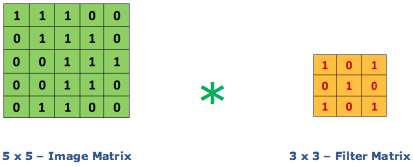
The convolution operation takes place as shown below
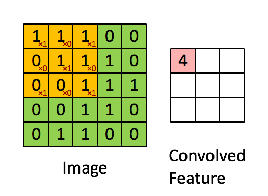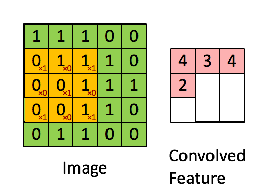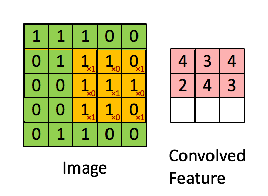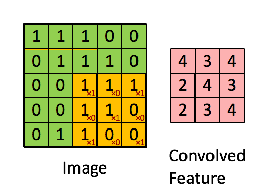
Mathematically, the convolution function is defined as follows:
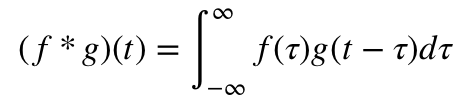
Very intuitively, we take a feature detector or filter and convolve it with the input image. e.g. we take a 5X5X3 and "slide it" all over the input image to get a feature map. The motive of this process is to extract all the important features from the image so that our model will only focus on the features and not on the unnecessary information.

We use various filters to get many feature maps, the collection of which is called a convolution layer. Certain specific filters or feature detectors cause the image to have certain effects.
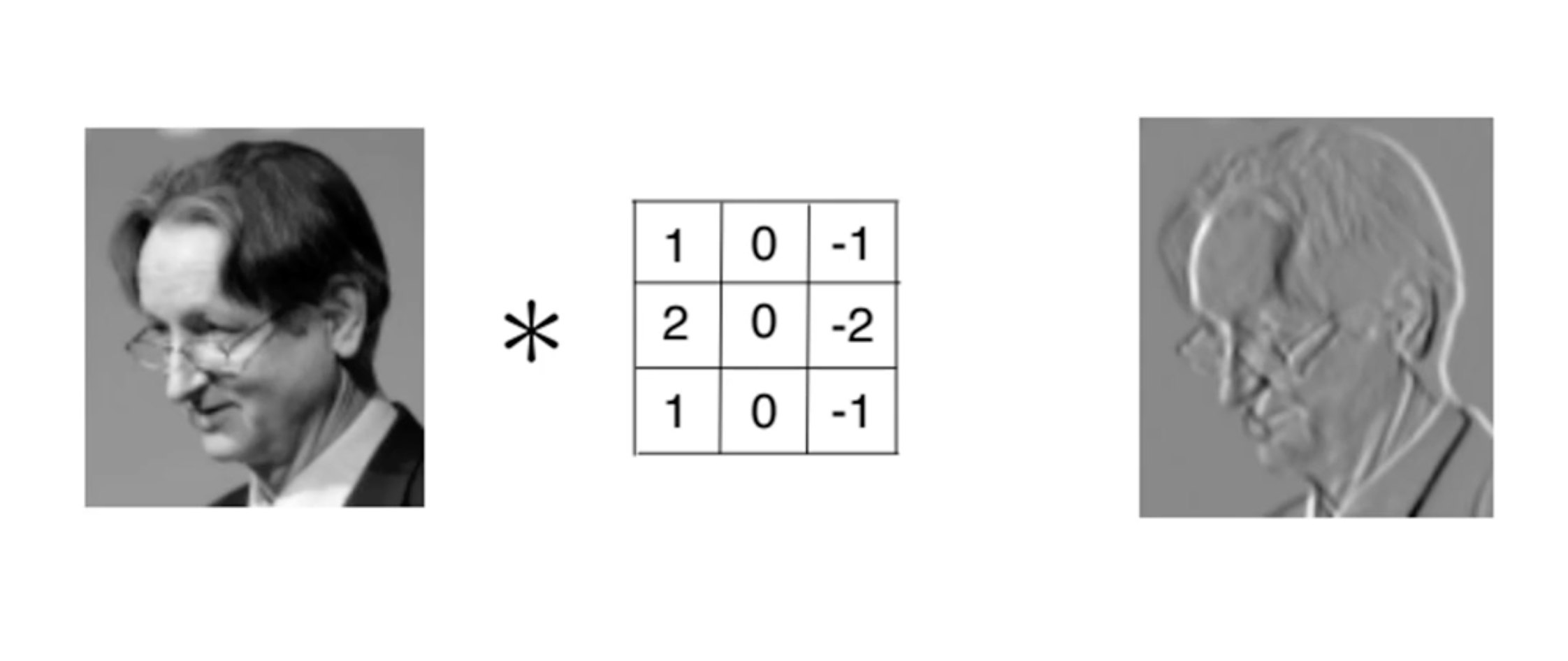
So the primary importance of convolution is that it detects features in an image while preserving the spacial features of the image, which if not achieved will serve no purpose.
Certain filters can be used to:
- blur an image
- detect the edges of an image
Consider this image for some of the types of filters used:

ReLU
An image, in general, is highly non-linear that is it has varied pixel values, especially if it has many features to be detected.
Thus to decrease the non linearity in the convolution layer, we add the rectifier function say max(x, 0), so that in case if there are negative pixel values, they will be replaced by zeroes.
Intuitively, it is fairly difficult for us to comprehend what the benefit of this step is, but it helps greatly in feature detection because:
- it helps in breaking the flow of the gradient in an image
- it brings a sharp or drastic change when there is a different feature.
Pooling
Pooling ensures that even if the features are a little distorted, or not very similar in different images, it still has the flexibility to identify the feature.
Here we focus on max pooling. In max pooling, we take a certain part of the feature map obtained in the previous step and report the highest or maximum value in that portion. In doing so, we preserve the feature of the image but at the same time get rif of more unimportant information. The map that we get as a result is called the pooled feature map.
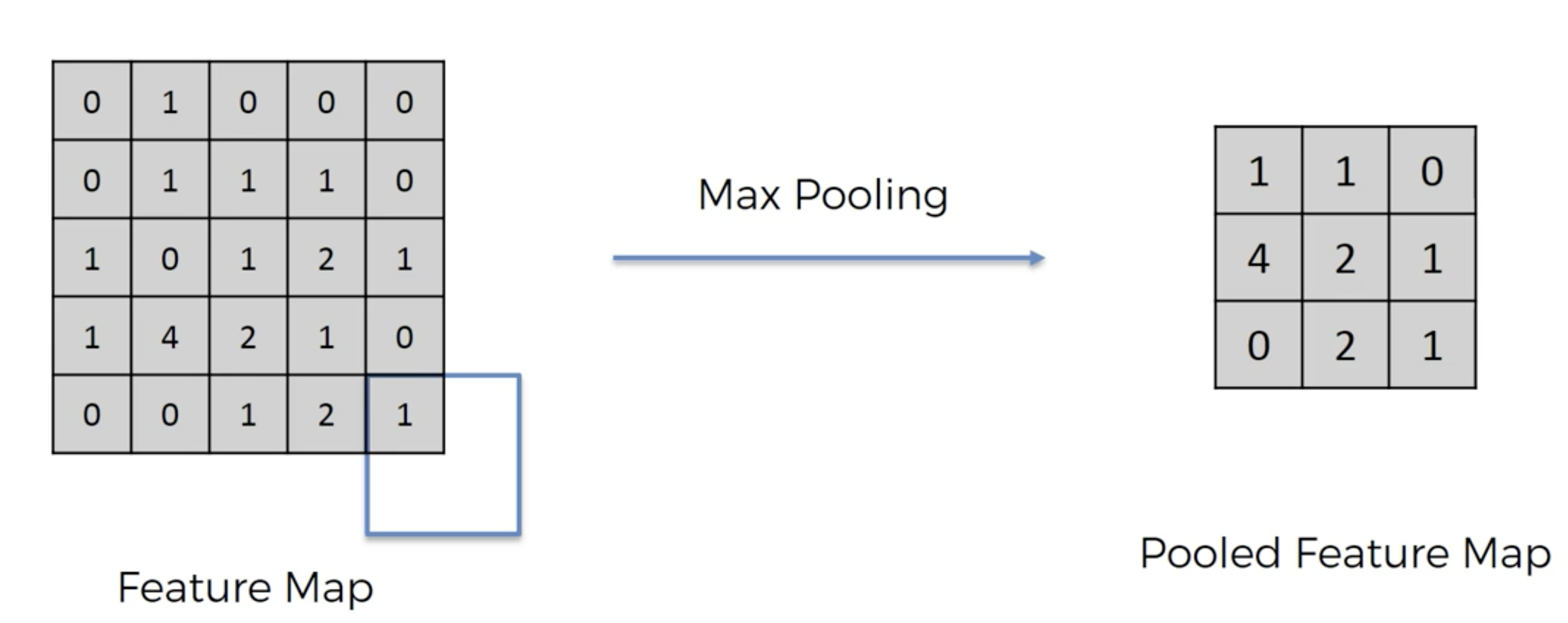
As a result of max pooling, even if the picture were a little tilted, the largest number in a certain region of the feature map would have been recorded and hence, the feature would have been preserved. Moreover, as an added benefit, we are reducing size by a very significant amount which will make our compution much easier.
So till now, we have convolved the image (while applying the ReLU) and carried out max pooling.
Flattening
In the flattening procedure, we basically take the elements in a pooled feature map and put them in a vector form. This becomes the input layer for the upcoming ANN.
Full Connection
Once the image is convolved, max pooled and flattened, the result is a vector. This vector acts as the input layer for an ANN which then works normally to detect the image.
It assigns random weights to each synapse, the input layer is weight adjusted and put into an activation function. The output of this is then compared to the true values and the error generated is back-propagated, i.e. the weights are re-adjusted and all the processes repeated. This is done until the error or cost function is minimised.
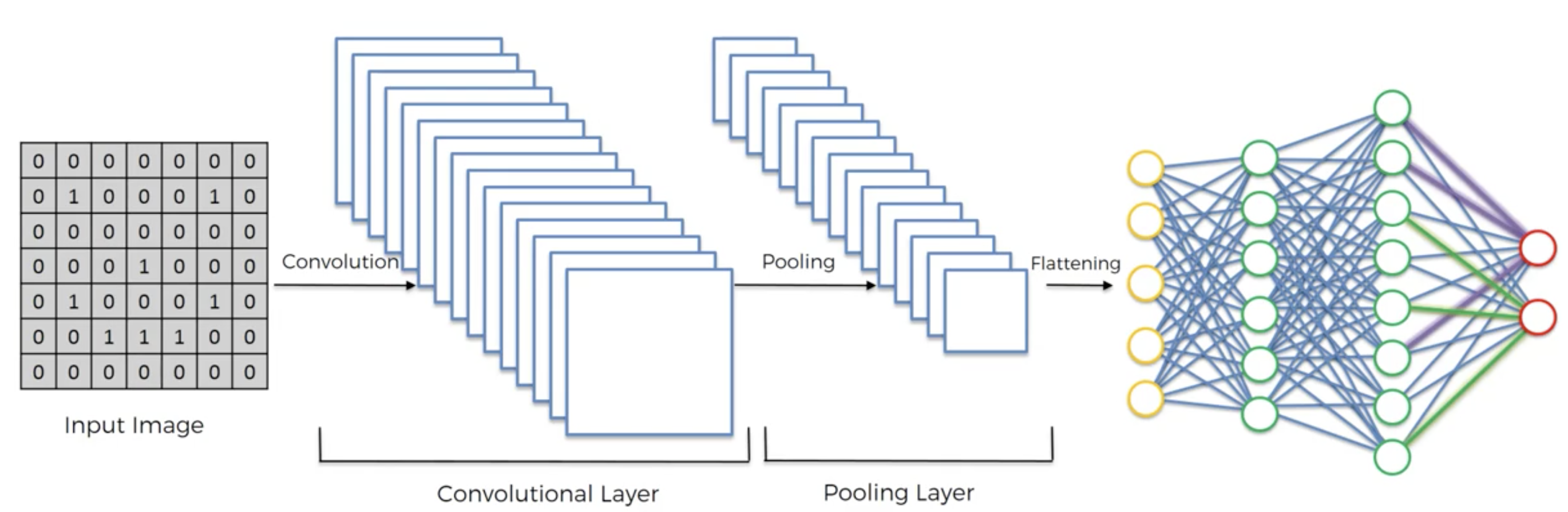
Thus, the basic difference between a CNN and an ANN is only the preprocessing stage. After the flattening stage when the image is converted into a vector, all the subsequent steps resemble those of the ANNs.