
In this article, we have explained one of the most popular applications of Machine Learning namely Object Detection. We have explained the input, output, models used and evaluation metrics for Object Detection.
Table of contents:
- Introduction
- Typical Structure of Object Detection Approach
- Overview of commonly used models for Object Detection
- Evaluation metrics for Object Detection
Introduction
Object detection is an image processing task that refers to the identification of objects in digital images. It is also referred to by synonymous concepts such as object recognition, object identification & image detection. It mainly involves 2 tasks:
1. Object Localization: involves finding one or more objects in an image
2. Object Classification: involves assigning a class label to the objects found in step 1
Object detection combines these two tasks by drawing a bounding box around each object of interest in the image and assigning it a label. Together, all of these problems are referred to as object recognition.

Typical Structure of Object Detection Approach
While both traditional machine learning & deep learning approaches are used for image recognition and object detection, we'll be focusing on the latter only as they have become widely accepted due to the the state-of the-art results they provide.
Deep learning approaches use convolutional neural networks (CNNs) to perform object detection, for which the features need not be defined separately.
Most approaches typically involve an encoder-decoder architecture as described:
- Encoder: This takes an image as an input and extracts features to locate and label objects. The outputs of the encoder are fed as input to the decoder.
- Decoder: This uses the features learned by the encoder to predict bounding boxes and class labels for each object
Input
The input to these models are a set of images which contain training and test images. Since object detection models are trained on input images, its important to ensure that the input dataset is labeled. Some of the commonly used datasets that serve as input for such models are as follows:
-
CIFAR-10: It comprises of 60,000 colour images in 10 different categories
-
Open Images: This has approximately 9 million pictures annotated with image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives. It also has 16 million bounding boxes for 600 object types on 1.9 million images done by expert annotators.
-
MS Coco: MS COCO is a large-scale object detection dataset that approaches three core analysis problems in scene recognition
-
DOTA: DOTA is an enormous dataset used to train object detection in aerial shots
-
ImageNet: This is an image dataset classified according to the WordNet hierarchy, where each link of the system is depicted by multiple pictures.

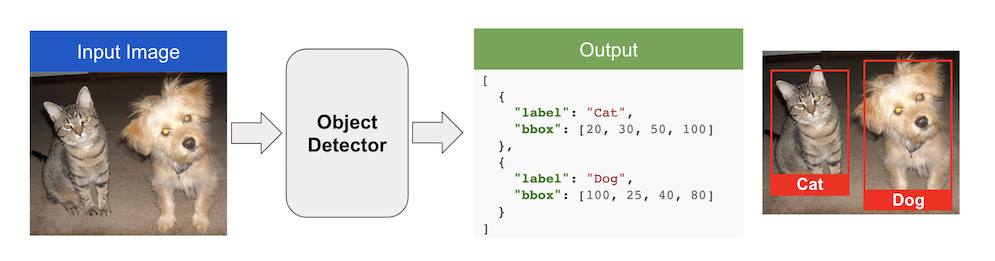
Output
After performing feature extraction from the input image pixels, the model labels these images as belonging to a specific class. This is accomplished by predicting the coordinates (X1, X2, Y1, Y2) of the bounding boxes within which the object is located in the image and the class labels, generally in an XML or JSON format.
Overview of commonly used models for Object Detection
R-CNN
This family of models refers to the R-CNN, which stands for “Regions with CNN Features” or “Region-Based Convolutional Neural Network” and includes R-CNN, Fast R-CNN, and Faster R-CNN.
R-CNN was one of the first simple & straight-forward applications which was able to use CNNs successfully for object detection tasks. However, it involved a multi-stage training pipeline which made it expensive in terms of both space & time, which led to the proposal of Fast R-CNN to overcome its limitations
Fast R-CNN had a single stage training pipeline using a multi-task loss and provide an improvement over R-CNN to the speed and accuracy of the model. Nonetheless, it still required a set of candidate regions to be proposed along with each input image.
Faster R-CNN uses the Region Proposal Network (RPN), a fully convolutonal network that proposes and refines the regions as part of the training process in a more cost-effective manner than both R-CNN and Fast R-CNN. The RPN is used in conjunction with a Fast R-CNN as a single, unified model which improves performance and the number and quality of regions proposed.
Histogram of Oriented Gradients (HOG)
Histogram of oriented gradients (HOG) is essentially a feature descriptor that is used for object detection tasks. This technique includes occurrences of gradient orientation in localized portions of an image, such as detection window, the region of interest (ROI), and more. The advantage of HOG-like features lies in their simplicity and the ease by which the information they carry can be understood
YOLO
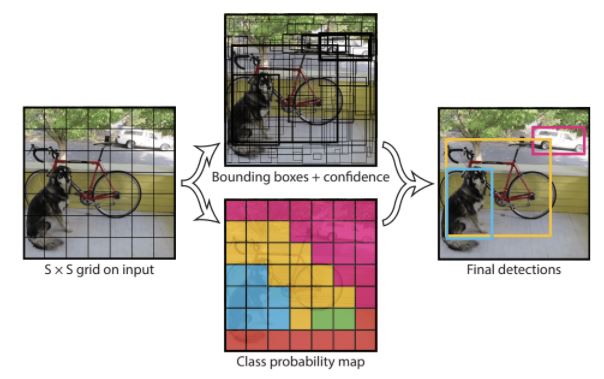
YOLO or “You Only Look Once” is another popular family of object detection models developed by Joseph Redmon, et al. This approach involves the used of a single neural network trained end to end that takes an image as an input, splits into a grid of cells. Each cell is responsible for predicting a bounding box (x & y coordinates) and the confidence, after which a class prediction is made.
Multiple versions of the family exist such as YOLOv2 & YOLOv3 which offer minor improvements over its preceding models. Whilst, the R-CNN family models are generally more accurate, the YOLO family of models are able to produce results in real-time, albeit with a lower accuracy.
Single Shot Detector (SSD)
SSD removes the region proposal generation and feature resampling stages of other models and encapsulates all computations into a single network. In this method, a single deep neural network is used which logically separates the output space of the bounding boxes into boxes over different aspect ratios. The network then combines predictions from the multiple feature maps of different resolutions to handle objects of various sizes. This makes SSDs easy to train and integrate into systems that require an object detection component due to its competitive accuracy
Evaluation Metrics for Object Detection
Accuracy
The accuracy of the predicted class labels of an object detection model can be computed using the metrics given below, which depend on the IoU threshold and the performance of the model.
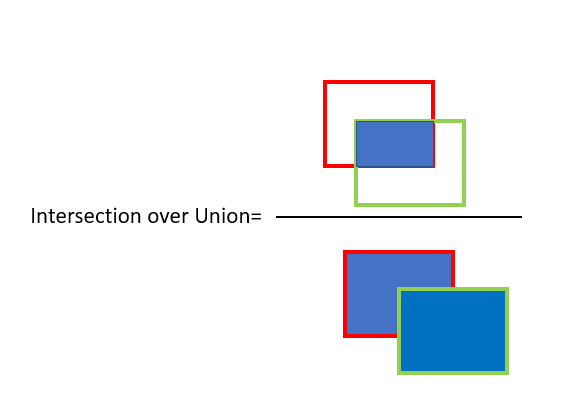
The Intersection over Union (IoU) ratio is used as the threshold to determine whether a predicted outcome is a true positive or a false positive. It is the ratio of the amount of overlap between the bounding box around a predicted object and the bounding box around the ground reference data. An IoU of 1 implies that predicted and the ground-truth bounding boxes overlap perfectly.
-
Precision: It is the ratio of the number of true positives to the total number of positive predictions.
-
Recall: It is the ratio of the number of true positives to the total number of actual (relevant) objects. For example, if the model correctly detects 75 trees in an image, and there are actually 100 trees in the image, the recall is 75 percent.
-
F1 score: The F1 score is a weighted average of the precision and recall. the values can range from 0 to 1; 1 indicating the highest accuracy.
-
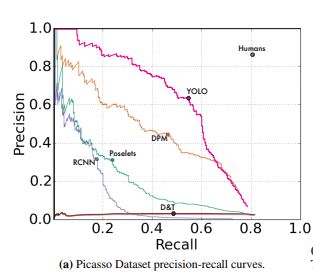
Precision-recall curve: This is a plot of precision (y-axis) and recall (x-axis), and it evaluates the performance of an object detection model. Ideally, the precision should remain high as the recall increases. The image below contains the precision-recall curves of a few popular models against the Picasso dataset.
The most common metric of choice used for Object Detection problems is the Mean Average Precision or the 'mAP' as unlike the above metrics, its capable of measuring the accuracy of both the class label predicted and the bounding boxes drawn over the objects in the image, i.e. the position of the objects in the image.
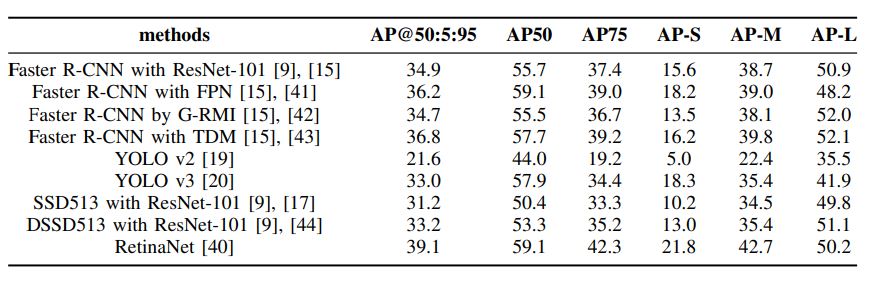
The above table contains results using AP variants obtained by different methods on the COCO dataset. The AP is evaluated with different IOUs. It can be calculated for 10 IOUs varying in a range of 50% to 95% with steps of 5%, usually reported as AP@50:5:95. It can also be evaluated with single values of IOU, where the
most common values are 50% and 75%, or AP50 and AP75 respectively.

The above table contains results of the accuracy of the top object detection models by comparing the mean AP on the PASCAL VOC 2012 dataset.
Performance
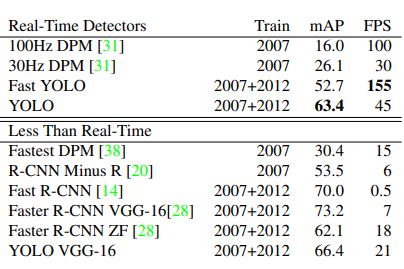
In the image above, the performance and speed of various object detectors are compared on the PASCAL VOC datasets. Fast YOLO is the fastest detector on record for PASCAL VOC 2007 detection and is still twice as accurate as any other real-time detector. Fast R-CNN speeds up the classification stage of R-CNN but still relies on selective search which can take around 2 seconds per image to generate bounding box proposals. Thus, it has a high mAP but is still far from realtime at 0.5 fps. The recent Faster R-CNN achieved 7 fps in its larger, more accurate version.
Conclusion
Over the course of this article at OpenGenus, we have provided a basic introduction to object detection, including the models commonly used & their performances. Numerous real-world applications, such as healthcare, self diving cars, face detection, video surveillance and many more make use of object detection. This can be attributed to the dramatic increase in computing power and hardware advancements such as multi-core processing, graphical processing unit (GPU), and AI accelerators such as tensor processing units (TPU).
Hope this proves helpful in getting you started with your object detection task!
References
- Padilla, Rafael; Net, Sergio L .; da Silva, Eduardo AB (2020). [IEEE 2020 International Conference on Systems, Signals and Image Processing (IWSSIP) - Niterói, Brazil (2020.7.1-2020.7.3)] 2020 International Conference on Systems, Signals and Image Processing (IWSSIP) - A Survey on Performance Metrics for Object -Detection Algorithms. , (), 237–242. doi: 10.1109 / IWSSIP48289.2020.9145130
- Girshick, Ross (2015). [IEEE 2015 IEEE International Conference on Computer Vision (ICCV) - Santiago, Chile (2015.12.7-2015.12.13)] 2015 IEEE International Conference on Computer Vision (ICCV) - Fast R-CNN. , (), 1440–1448. doi:10.1109/ICCV.2015.169