
In this article, we have explained the idea of One Shot Learning in Machine Learning (ML) and where and how it is used along with the limitation of One Shot Learning.
Table of contents for One Shot Learning in ML:
- Introduction to One Shot Learning in ML
- Where is One-shot learning used?
- Conventional Convolutional Neural Networks
- Using existing CNNs for one-shot learning
- Siamese neural network and triplet loss function
- Limitations of one-shot learning
Introduction to One Shot Learning in ML
One-shot learning is a classification task where one, or a couple, examples are used to classify many new examples in the future. Let us learn about it with the help of an example.
Passport identification checks at air terminals and border gates present an exceptional challenge: How would you tell if the individual standing before you is a similar individual whose image is in the visa? Border and customs officials tackle this issue utilizing complex components instilled in the human visual framework through billions of years of evolution.
Though it is not a perfect process, it works most of the time.

In the domain of Artificial Intelligence, this is known as the "one-shot learning" challenge. In a more dynamic manner, would you be able to foster a computer vision framework that can see two pictures it has never seen and say whether they address a similar item?
Data is one of the critical difficulties in deep learning, the part of Artificial Intelligence that has had the most achievement in computer vision. Deep learning models are well-known for requiring enormous amounts of training data to perform basic assignments like recognizing objects in pictures.
However, strangely, if designed appropriately, deep neural networks, the vital part of deep learning frameworks, can perform one-shot learning on simple tasks. As of late, one-shot learning AI has discovered effective applications including face recognition and passport identification checks.
Where is One-shot learning used?
One-shot learning characterizes tasks in the field of facial recognition, for example, face verification and face identification, where individuals should be accurately classified with various looks, lighting conditions, accessories, and haircuts given one or a couple of template photographs.
Present day facial recognition systems approach the issue of one-shot learning through face embedding that can be determined for faces effectively and compared for verification and identification tasks. Face embedding utilizes a rich low-dimensional feature representation which the one-shot learning uses.
In the past, a Siamese network was used to learn the face embeddings. Using loss functions helped the training of the Siamese network which subsequently gave birth to the triplet loss function used in the FaceNet system implemented by Google which became the de facto, state-of-the-art benchmark for facial recognition tasks.
In this post, you will study about the classical convolutional neural networks and how we can repurpose those CNNs to be able to use into one-shot learning. We will than see the Siamese neural network and the triplet loss function. Finally, we will conclude with the current limitations of one-shot learning.
Conventional Convolutional Neural Networks
Perhaps the main models utilized in deep learning is the convolutional neural network (CNN), an extraordinary sort of neural net that is particularly exceptional at working with visual information.
The exemplary utilization of CNNs is to set up multiple convolution layers (with other significant parts in the middle and after), indicate an output, and train the neural network on a large number or labeled examples (training examples).
For example, an image classifier convnet (Convolutional Network) accepts a picture as the input, measures its pixels through its numerous layers, and produces a rundown of qualities that address the likelihood that the picture has a place with one of the classes it detects. The figure below showcases AlexNet, a very famous Convolutional Neural Network.
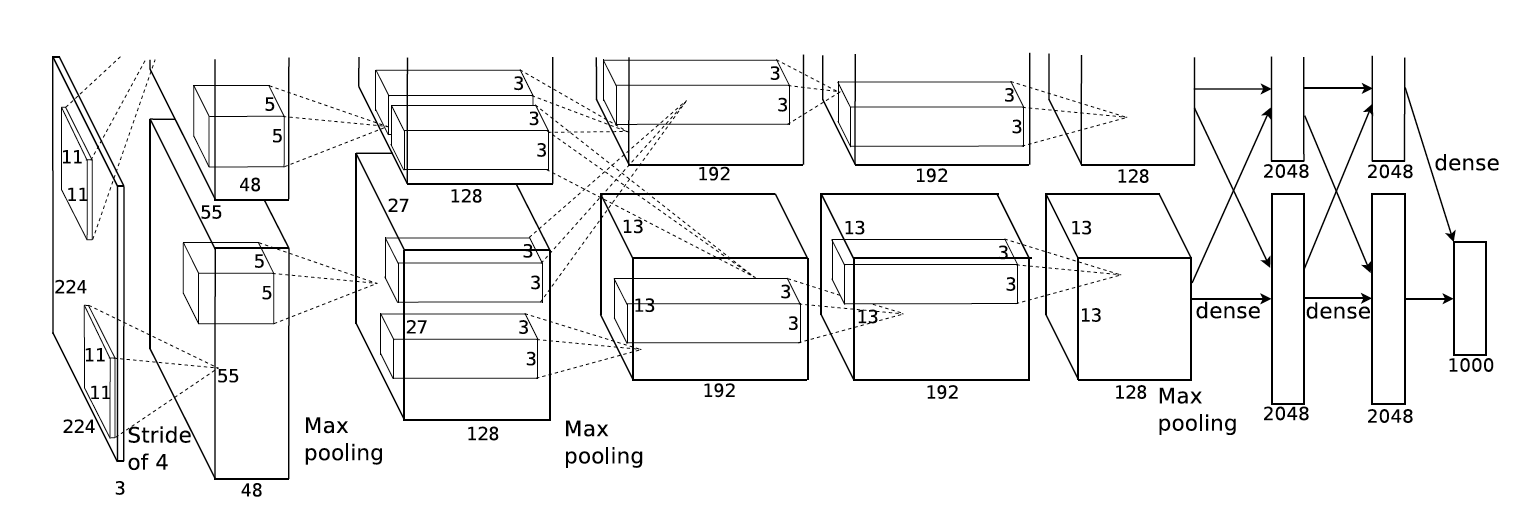
The neural network can be trained on one of many public datasets like ImageNet, which contains millions of pictures marked with in excess of 1,000 classes. As the convnet goes through the training set, it starts to tune its various hyperparameters in order to distinguish the class of each image.
One of the fascinating highlights of these convolutional neural networks is their capacity to separate visual highlights from pictures at various levels. A well trained convolutional neural network fosters a hierarchical construction of highlights, beginning with smaller, more modest highlights in first layers with bigger and more significant level highlights in the more profound layers. Here, highlights refer to the features that the networks detects.
At the point when a picture goes through the CNN, it encodes the picture's highlights into a bunch of numerical values and afterward utilizes these values to figure out which class the picture has to be placed. With enough training examples, a convnet can sum up the component encoding measure all around the image to determine the class in which it should be placed. Numerous computer vision applications use convolutional neural networks.
Rather than ImageNet (or other public datasets), software developers can utilize their own curated training set. But, due to budget constraints and the work of image gathering and image labeling, they generally use a public dataset for their model training. Once they are satisfied with the results, they start to tweak the model and finetune it to smaller datasets which contains the images specific to their problem.
Using existing CNNs for one-shot learning
One of the vital issues in numerous computer vision issues is that you don't have enough labeled images for training your network. For example, models designed for facial recognition must be trained on many images of a same person in order to properly detect and recognize the same individual. Now envision how this problem might affect a facial recognition system installed at an international airport. You soon realize that you would require a lot of images of everyone who might perhaps go through that air terminal, which could add up to billions of images. Beside being essentially difficult to assemble such a dataset, the idea of having an incorporated store of every individuals' face would be a privacy nightmare.
This is the place where one-shot learning becomes an integral factor in mitigating this problem. Rather than thinking the task as a classification problem, one-shot learning transforms it into a difference-evaluation problem.
At the point when a deep learning model is adapted to one-shot learning, it takes two pictures (e.g., the visa picture and the picture of the individual looking at the camera) and returns a value that shows how similar the two pictures are. If the images showcases a similarity between them, the neural network returns a value that is less than the threshold value set. On the other hand, if the images does not have a similarity, then the returned value will be higher than the threshold.
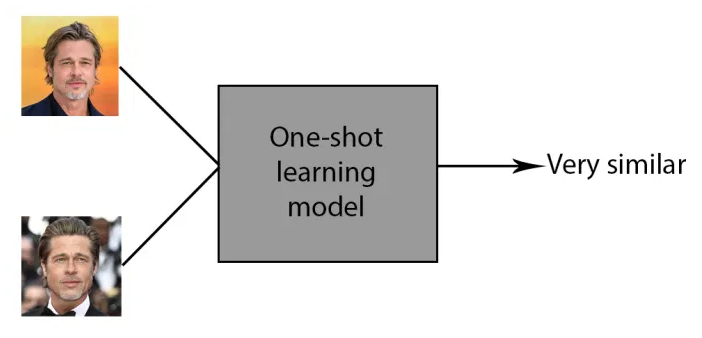
Siamese neural network and triplet loss function
The way to one-shot learning is through an architecture called the "Siamese neural network." Basically, the Siamese neural network isn't very different from other convolutional neural networks it takes in images as input and encodes their features into a bunch of numbers. The distinction comes in the output. During training, classical CNNs tune their parameters so they can relate each picture to its legitimate class. The Siamese neural network trains to measure the distance between the features in the two input images (like the image of a person and its passport image).

How can we achieve a score that can tell the similarity? Well, we make use of a function called the "triplet loss function." Basically, the triplet loss function trains the network by giving it three pictures: an anchor, a positive image, and a negative image. The neural network should change its parameters in accordance to the features extracted from the anchor. This eventually results in the positive image exceptionally close to the anchor while the negative image is altogether different.
Ideally, with enough training set, the neural network will foster a design that can compare high-level features between APN trios. For example, on account of the facial recognition model, a well trained Siamese neural network must be able to analyze the two images with the help of their facial highlights like distance between eyes, nose, and mouth. You can learn more about triplet loss functiono by watching this video.
Preparing the Siamese neural network actually requires a large set of APN trios. However, making the training set is a lot simpler than classical datasets that need each picture to be named. Let's assume you have a dataset of 20 faces from two individuals, which implies you have 10 pictures for each individual. You can produce 1,800 APN trios from this dataset. (You take the 10 photos of every individual to make 10×9 AP matches and consolidate it with the excess 10 pictures to make a sum of 10x9x10x2 = 1800 APN triplets)
With 30 pictures, you can make 5,400 triplets, and with 100 pictures, you can make 81,000 APNs. Preferably, your dataset must have a variety of face images for better generalization across different features. Another smart thought is to utilize a formerly prepared convolutional neural network and finetune it for one-shot learning. This is known as transfer learning and is a productive method to reduce down the expenses and time of training and creating a new neural network.
Once the training of the Siamese neural network is finished, if you give two new images of a face or an object (e.g., passport photo and camera input), it will be able to distinguish and tell if the two pictures are similar or not. This way, you don't have to prepare your facial recognition model on every one of the faces that are there in this world.
Limitations of one-shot learning
While one-shot learning eliminates the need of training a billion images to a model, its use is highly specific. You cannot use the model that you use in getting the similarity of a passport image and the person looking at the camera to tell if two pictures contain the same cat or same car.
Another disadvantage of one-shot learning is that there is an element of variance. One-shot learning is highly susceptible to variance; the accuracy can significantly decrease if the person is wearing a hat, scarf, sunglasses or any other accesory that can hide the face. Nevertheless, one-shot learning is an actively developed topic with vairances like zero-shot learning and few-shot learning.
With this article at OpenGenus, you must have the complete idea of One Shot Learning in Machine Learning (ML).