
In this article, we will explore the model architecture of RetinaNet Model which is widely used for Object Detection tasks. This is a strong alternative to YOLO, SSD and Faster R-CNN. It has over 32 million parameters for ResNet-50 as baseline model.
We'll discuss:
- Introduction
- Object Detection
- Challenges with Object Detection
- RetinaNet: One-Stage Object Detector
- Feature Pyramid Netwrok (FPN)
- Focal Loss Function
- RetinaNet Training
- Compare RetinaNet with other models
- Conclusion
Introduction
Object detection is a critical task in computer vision that involves identifying objects within an image and determining their locations. It has numerous applications in fields such as self-driving cars, surveillance systems, and robotics. One of the challenges in object detection is accurately identifying objects of different sizes within an image, as well as handling imbalanced data where the number of objects in a particular class is much smaller than others.
To address these issues, RetinaNet was developed as a one-stage object detection model that uses a Feature Pyramid Network (FPN) and Focal Loss function. In this blog, we will explore RetinaNet in depth, explaining its architecture and how it overcomes these challenges. We will also discuss the training process and the evaluation metrics used to assess object detection performance. Whether you are a beginner in computer vision or an experienced researcher, this blog will provide you with a comprehensive understanding of RetinaNet and its contributions to the field of object detection.
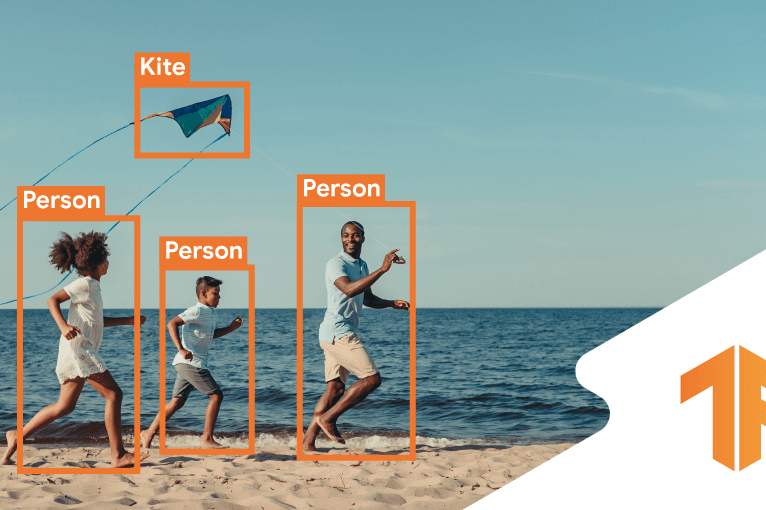
Object Detection
Object detection is a fundamental task in computer vision that involves identifying objects within an image and determining their locations. It is a crucial task that has many real-world applications, such as detecting pedestrians, vehicles, and traffic signs in self-driving cars, identifying suspicious activities in surveillance videos, and counting and tracking wildlife in environmental monitoring.
Object detection is typically accomplished using a two-stage framework. In the first stage, a region proposal network (RPN) generates candidate object bounding boxes. These candidate boxes are then fed into a second stage where object classification and bounding box regression are performed. The RPN is typically a separate network from the object classification network, which can lead to inefficiencies and difficulties in handling objects of different sizes.
However, RetinaNet uses a different approach, a one-stage object detection model. The model detects objects in a single feed-forward pass, making it more computationally efficient than two-stage models. In the next section, we will explore the challenges with object detection that RetinaNet addresses.
Challenges with Object Detection
While object detection is a powerful tool in computer vision, it comes with its own set of challenges. Two of the most significant challenges are handling imbalanced data and detecting objects of different sizes.
One of the primary issues in object detection is that the number of objects in a particular class can be significantly smaller than others. For example, in a pedestrian detection system, the number of non-pedestrian objects may be much larger than the number of pedestrians. This can lead to biased learning, where the model focuses too much on the more abundant objects and may miss the less common objects.
Another significant challenge is detecting objects of different sizes. In a single image, objects can range from very small to very large, and detecting them all can be difficult. Traditional object detection models that use a fixed-size input image can miss small objects or confuse large objects for background regions.
In the next section, we will discuss how RetinaNet addresses these challenges with its unique architecture.
RetinaNet: One-Stage Object Detector
RetinaNet is a one-stage object detection model that addresses the challenges of imbalanced data and objects of different sizes. It accomplishes this through a unique architecture that uses a Feature Pyramid Network (FPN) and Focal Loss function.
RetinaNet architecture consists of a backbone network, a feature pyramid network (FPN), and two task-specific subnetworks for classification and regression. The backbone network is responsible for extracting features from the input image. RetinaNet uses ResNet as the backbone network with four feature maps of different resolutions. The FPN combines these feature maps to construct a pyramid of multi-scale feature maps that are used to detect objects of different sizes.
The classification subnetwork uses the feature maps produced by the FPN to classify objects into different classes, while the regression subnetwork refines the bounding box coordinates of the objects. RetinaNet uses anchor boxes, which are predefined bounding boxes of different sizes and aspect ratios, to detect objects at different locations and scales.
RetinaNet's Focal Loss function is a key component of its architecture. It addresses the issue of imbalanced data by assigning higher weights to hard examples, which are objects that the model is struggling to detect. This reduces the impact of easy examples, allowing the model to focus more on difficult examples and improve its performance.
The parameters of the RetinaNet model depend on the backbone network used. For example, if we use ResNet-50 as the backbone network, the model has around 32 million parameters. On the other hand, if we use ResNet-101 as the backbone network, the model has around 45 million parameters. Additionally, the FPN and the two subnetworks also contribute to the total number of parameters.
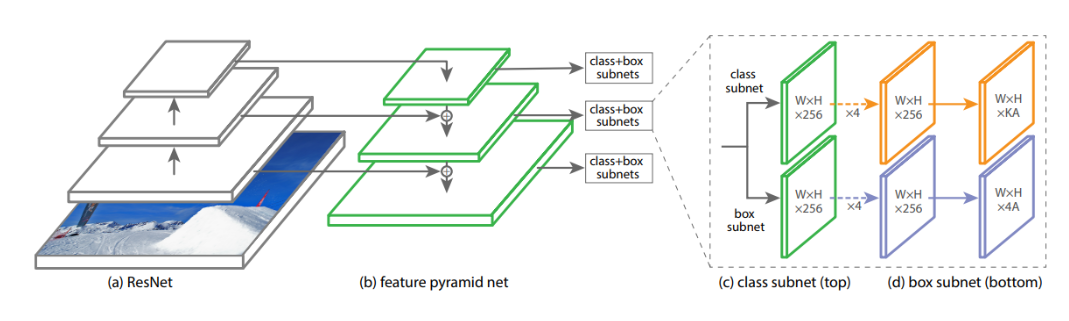
In the next sections, we will dive deeper into FPN and the Focal Loss function, and how they contribute to RetinaNet's success in object detection.
Feature Pyramid Network (FPN)
The Feature Pyramid Network (FPN) is a critical component of RetinaNet's architecture. It addresses the issue of objects of different scales by generating a feature pyramid with different scales and resolutions.
FPN works by first taking the feature maps produced by the backbone network and processing them through a top-down pathway and a bottom-up pathway. The top-down pathway upsamples the feature maps to a higher resolution and merges them with corresponding feature maps from the bottom-up pathway. This process is repeated multiple times to produce a feature pyramid with multiple levels.
The feature maps at each level of the pyramid have different scales and resolutions, enabling the model to detect objects of different sizes. For example, the feature maps at the top of the pyramid have a higher resolution and are better suited for detecting small objects, while the feature maps at the bottom of the pyramid have a lower resolution and are better suited for detecting large objects.
The FPN architecture is essential for RetinaNet's success in object detection. It enables the model to detect objects of different sizes and scales accurately, which is crucial for many real-world applications. In the next section, we will discuss how the Focal Loss function further improves RetinaNet's performance.
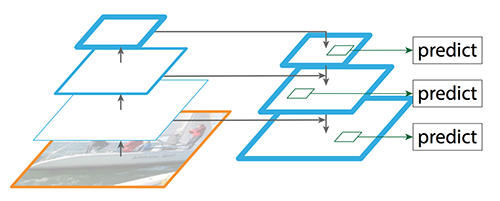
Focal Loss Function
The Focal Loss function is another critical component of RetinaNet's architecture. It addresses the issue of imbalanced data by assigning higher weights to hard examples, which are objects that the model is struggling to detect.
The focal loss function works by down-weighting the loss assigned to well-classified examples and up-weighting the loss assigned to misclassified examples. It accomplishes this by introducing a modulating factor called the focal factor, which reduces the loss assigned to well-classified examples and increases the loss assigned to misclassified examples.
The focal factor is a function of the predicted probability of the object. When the predicted probability is high, the focal factor is low, and the loss is down-weighted. When the predicted probability is low, the focal factor is high, and the loss is up-weighted. This approach is more effective than traditional cross-entropy loss, which assigns equal weight to all examples regardless of their difficulty.
The focal loss function is crucial for RetinaNet's success in object detection, especially when dealing with imbalanced data. By assigning higher weights to hard examples, it reduces the impact of easy examples and allows the model to focus more on difficult examples. This results in a more robust and accurate object detection model.
RetinaNet Training
Training RetinaNet involves several critical steps, including data preparation, model selection, and evaluation. In this section, we will briefly discuss the training process and some essential concepts.
First, to train RetinaNet, we need a dataset of labeled images with bounding boxes around objects of interest. We also need to split the dataset into training, validation, and test sets to evaluate the model's performance.
Once we have the dataset, we can start training the model using a stochastic gradient descent optimizer with the focal loss function as the objective. The training process involves adjusting the weights of the network based on the error signal generated by the loss function. This process is repeated for several epochs until the model's performance on the validation set starts to plateau.
Here's an example code snippet that shows how to train a RetinaNet model using the PyTorch deep learning framework:
import torch
import torchvision
from torchvision.models.detection.retinanet import RetinaNet
# Define the dataset and data loaders
dataset = MyDataset(...)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=True, num_workers=4)
# Define the RetinaNet model
model = RetinaNet(num_classes=10, pretrained_backbone=True)
# Define the optimizer and loss function
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
loss_fn = RetinaNet.FocalLoss()
# Train the model for several epochs
for epoch in range(10):
for images, targets in data_loader:
images = list(image for image in images)
targets = [{k: v for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
# Evaluate the model on the validation set
# ...
This code is just an example, and in practice, you may need to modify it to fit your specific use case. However, it should give you a general idea of how to train a RetinaNet model using PyTorch.
One important concept in RetinaNet training is anchor boxes. Anchor boxes are pre-defined boxes of different shapes and sizes that serve as reference points for the model to predict the location and size of the objects. The model generates a set of anchor boxes at each spatial location in the feature maps and predicts the offset and scale for each anchor box to match the ground-truth boxes in the training data.
Another important concept in RetinaNet training is evaluation metrics. The most commonly used metrics for object detection are mean Average Precision (mAP) and Intersection over Union (IoU). mAP is a measure of the overall performance of the model, while IoU is a measure of the overlap between the predicted and ground-truth bounding boxes.
Compare RetinaNet with other models
RetinaNet is not the only object detection model out there. There are many popular object detection models that have been proposed over the years, including YOLO (You Only Look Once), Faster R-CNN, and SSD (Single Shot Detector).
While all these models aim to achieve the same goal, i.e., detecting objects in an image, they differ in their architecture and approach. Here's a brief comparison of RetinaNet with other popular object detection models:
-
YOLO (You Only Look Once) : YOLO is a popular object detection model that operates in real-time. Unlike RetinaNet, YOLO treats object detection as a regression problem, where the model directly predicts the bounding boxes and class probabilities in a single shot. YOLO is faster than RetinaNet but may sacrifice accuracy in some cases.
-
Faster R-CNN : Faster R-CNN is a two-stage object detection model that uses a Region Proposal Network (RPN) to generate candidate regions, followed by a classifier to predict the class of each candidate. While Faster R-CNN may be slower than RetinaNet, it is generally more accurate.
-
SSD (Single Shot Detector) : SSD is another single-stage object detection model that predicts the class and location of objects in a single shot. SSD is similar to RetinaNet in that it uses a feature pyramid network to detect objects at multiple scales. However, SSD may struggle with detecting small objects.
Conclusion
Overall, RetinaNet is a powerful model that has shown promising results in many different applications. As deep learning research continues to evolve, we can expect further developments in object detection with RetinaNet and other similar models.
In conclusion, RetinaNet is a powerful model that provides significant improvements in object detection, and it is essential to have an understanding of its architecture and benefits for any computer vision practitioner.